The large language models today are a simplified form of the transformer model. They are called decoder-only models because their role is similar to the decoder part of the transformer, which generates an output sequence given a partial sequence as input. Architecturally, they are closer to the encoder part of the transformer model. In this post, you will build a decoder-only transformer model for text generation in the same architecture as Meta’s Llama-2 or Llama-3. Specifically, you will learn:
- How to build a decoder-only model
- The variations in the architecture design of the decoder-only model
- How to train the model
Kick-start your project with my book Building Transformer Models From Scratch with PyTorch. It provides self-study tutorials with working code.
Let’s get started.

Building a Decoder-Only Transformer Model for Text Generation
Photo by Jay. Some rights reserved.
Overview
This post is divided into five parts; they are:
- From a Full Transformer to a Decoder-Only Model
- Building a Decoder-Only Model
- Data Preparation for Self-Supervised Learning
- Training the Model
- Extensions
From a Full Transformer to a Decoder-Only Model
The transformer model originated as a sequence-to-sequence (seq2seq) model that converts an input sequence into a context vector, which is then used to generate a new sequence. In this architecture, the encoder part is responsible for converting the input sequence into a context vector, while the decoder part generates the new sequence from this context vector.
Instead of using the context vector to generate an entirely new sequence, can we project it into a vector of logits representing probabilities for each token in the vocabulary? This way, given a partial sequence as input, the model can predict the next most likely token. By iteratively feeding the sequence back into the model, we can generate coherent text one token at a time, much like auto-complete functions in text editors. This simplified architecture, which focuses solely on predicting the next token, is called a decoder-only model.
Building a Decoder-Only Model
A decoder-only model has a simpler architecture than a full transformer model. Starting with the full transformer architecture discussed in the previous post, you can create a decoder-only model by removing the encoder component entirely and adapting the decoder for standalone operation.
The implementation reuses a significant portion of the code from the full transformer model. The DecoderLayer class shares the same structure as the EncoderLayer from the previous implementation. The TextGenerationModel class features a simplified forward()
method since it no longer needs to handle encoder-decoder interactions.
It simply converts input token IDs into embeddings, processes them
through the stacked decoder layers, and projects the output into logits
representing probabilities for each token in the vocabulary.
In the picture, the model is like the following. This shares the same architectural design of Llama-2/Llama-3 models proposed by Meta:
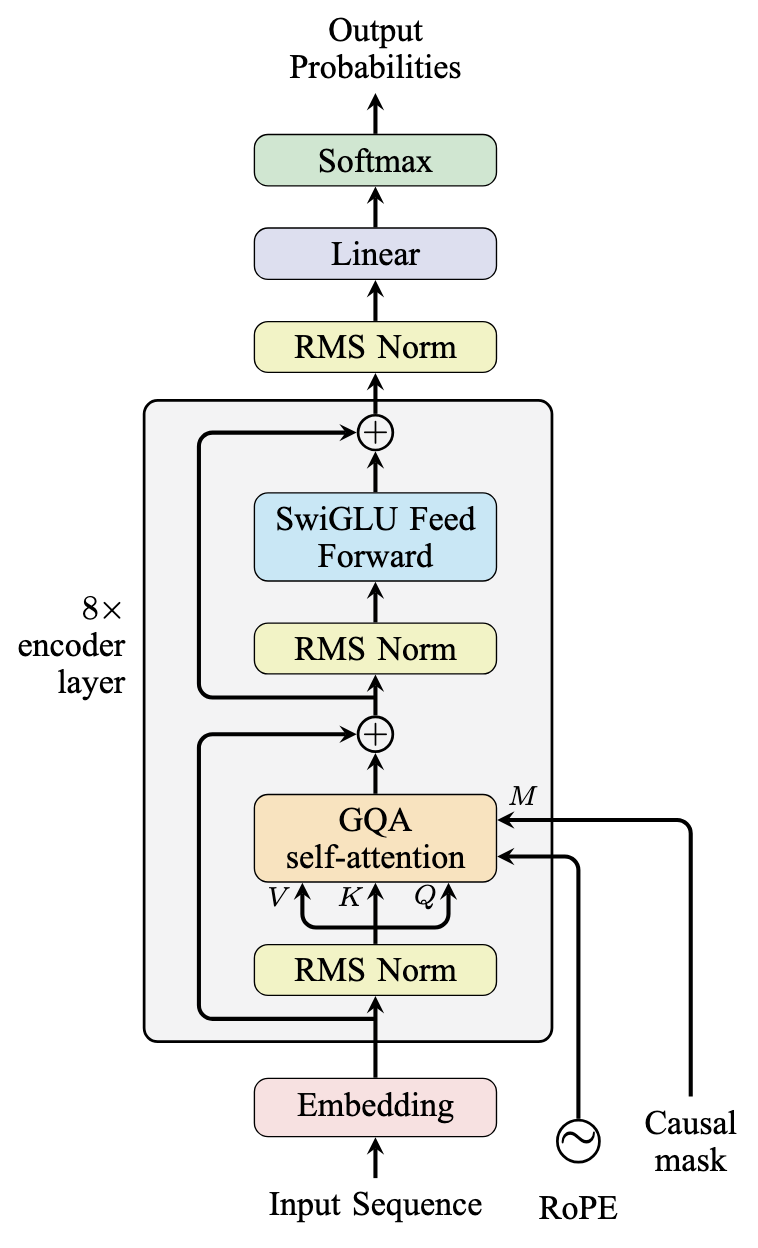
Decoder-Only Model Following the Architecture of Llama-2/Llama-3
Data Preparation for Self-Supervised Learning
Our goal is to create a model that can generate coherent paragraphs of text from a given prompt, even if that prompt is just a single word. To train such a model effectively, we need to consider our training approach and data requirements carefully.
The training technique we’ll use is called self-supervised learning. Unlike traditional supervised learning, which requires manually labeled data, self-supervised learning leverages the inherent structure of the text itself. When we input a sequence of text, the model learns to predict the next token, and the actual next token in the text serves as the ground truth. This eliminates the need for manual labeling.
The size of the training dataset is crucial. With a vocabulary size of 𝑁 tokens and a dataset containing 𝑀 words, each token appears approximately 𝑀/𝑁 times on average. To ensure the model learns meaningful representations for all tokens, this ratio needs to be sufficiently large.
In this post, you will download some novels from Project Gutenberg and use them as the dataset to train the model.
These public domain novels, written by various authors across different genres, provide a diverse dataset that will help our model learn a wide range of vocabulary and writing styles.
With these novels downloaded, you can extract the main context as a string and keep these strings as a list:
The next step is to create a tokenizer. You can build a naive tokenizer by splitting the text into words. You can also use the Byte-Pair Encoding (BPE) algorithm to create a more sophisticated tokenizer, as follows:
This uses the tokenizers library to train a BPE tokenizer. You called get_dataset_text() to get the text of all the novels and then train the tokenizer on it. You also need two special tokens: [pad] and [eos]. Most importantly, the [eos] token is used to indicate the end of the sequence. If your model generates this token, you know you can stop the generation.
Training the Model
With the tokenizer and the dataset ready, you can now train the model.
First, you need to create a Dataset object that can be used to train the model. PyTorch provides a framework for this.
This Dataset object is used to create a DataLoader object that can be used to train the model. The DataLoader object will automatically batch the data and shuffle it.
The Dataset object produces a pair of input and output sequences in the __getitem__()
method. They are of the same length but offset by one token. When the
input sequence is passed to the model, the model generates the next
token for each position in the sequence. Hence, the ground truth output
is from the same source, offset by one. This is how you can set up the
self-supervised training.
Now you can create the model and train it. You can use this code to create a very large model. However, if you do not expect the model to be very powerful, you can design a smaller one. Let’s make one with:
- 8 layers
- Attention uses 8 query heads and 4 key-value heads
- Hidden dimension is 768
- Maximum sequence length is 512
- Set dropout at attention to 0.1
- Train with AdamW optimizer with initial learning rate 0.0005
- Learning rate scheduler with 2000 steps of warmup and then cosine annealing
- Train for 2 epochs with batch size 32, clip norm to 6.0
Everything above is typical. Training a decoder-only model typically requires a very large dataset, and the number of epochs may be as few as 1. It is the number of steps trained that matters. The training will use a linear warmup to gradually increase the learning rate at the beginning, which can reduce the effect of how the model is initialized. Then the cosine annealing will gradually decrease the learning rate such that at the end of the training, when the model is almost converged, it keeps the learning rate at a very small value to stabilize the result.
The code for model creation and training is as follows:
In the training loop, you did the usual forward and backward passes. The model will be saved whenever the loss is improved. For simplicity, no evaluation is implemented. You should evaluate the model regularly (not necessarily after every epoch) to monitor progress.
Due to the large vocabulary size and sequence length, the training process is computationally intensive. Even on a high-end RTX 4090 GPU, each epoch takes approximately 10 hours to complete.
Once the training is done, you can load the model and generate text:
The model was used to generate text in the generate_text() function. It expects a partial sentence as input prompt,
and the model will be used to generate the next token for each step
inside the for-loop. The generation algorithm uses a probability
sampling rather than always choosing the most likely token. This allows
the model to generate more creative text. The temperature parameter controls the level of creativity of the generated text.
The output from the model is a vector of logits, and the sampling process generates a vector of token IDs. This vector will be converted back to a string by the tokenizer.
If you run this code, you may see the following output:
While the generated text shows some coherence and understanding of language patterns, it’s not perfect. However, considering the relatively small size of our model and limited training data, these results are encouraging.
For completeness, below is the full code of the model and the training:
Extensions
While we’ve successfully implemented a basic decoder-only model, modern large language models (LLMs) are significantly more sophisticated. Here are key areas for improvement:
- Scale and Architecture: Modern LLMs use many more layers and larger hidden dimensions. They also incorporate advanced techniques beyond what we’ve implemented here, such as mixture of experts.
- Dataset Size and Diversity: Our current dataset, consisting of a few megabytes of novel text, is tiny compared to the terabyte-scale datasets used in modern LLMs. Production models are trained on diverse content types across multiple languages.
- Training Pipeline: What we’ve implemented is called “pretraining” in LLM development. Production models typically undergo additional fine-tuning phases for specific tasks, such as question-answering or instruction-following, using specialized datasets and tailored training objectives.
- Training Infrastructure: Training larger models requires sophisticated techniques for distributed training across multiple GPUs, gradient accumulation, and other optimizations that would require significant modifications to our training loop.
Further Reading
Below are some links that you may find useful:
- LLaMA: Open and Efficient Foundation Language Models
- BloombergGPT: A Large Language Model for Finance
- SmolLM2: When Smol Goes Big — Data Centric Training of a Small Language Model
- What is the difference between pre-training, fine-tuning, and instruct-tuning exactly?
Summary
In this post, you’ve walked through the process of building a decoder-only transformer model for text generation. In particular, you’ve learned:
- Understanding how to simplify a full transformer architecture into a decoder-only model
- Implementing self-supervised learning for text generation tasks
- Creating a text generation pipeline using the trained model
This decoder-only architecture serves as the foundation for many modern large language models, making it a crucial concept to understand in the field of natural language processing.






No comments:
Post a Comment