
Kernel Methods in Machine Learning with Python
Image by Editor | Midjourney
Introduction
Kernel methods are a powerful class of machine learning algorithm that allow us to perform complex, non-linear transformations of data without explicitly computing the transformed feature space. These methods are particularly useful when dealing with high-dimensional data or when the relationship between features is non-linear.
Kernel methods rely on the concept of a kernel function, which computes the dot product of two vectors in a transformed feature space without explicitly performing the transformation. This is known as the kernel trick. The kernel trick allows us to work in high-dimensional spaces efficiently, making it possible to solve complex problems that would be computationally infeasible otherwise.
Why would we use kernel methods?
- Non-linearity: Kernel methods can capture non-linear relationships in data by mapping it to a higher-dimensional space where linear methods can be applied
- Efficiency: By using the kernel trick, we avoid the computational cost of explicitly transforming the data
- Versatility: Kernel methods can be applied to a wide range of tasks, including classification, regression, and dimensionality reduction
In this tutorial, we will explore the fundamentals of kernel methods, focusing on the following topics:
- The Kernel Trick: Understanding the mathematical foundation of kernel methods
- Support Vector Machines (SVMs): Using SVMs for classification with kernel functions
- Kernel PCA: Dimensionality reduction using kernel PCA
- Practical Examples: Implementing SVMs and Kernel PCA in Python
The Kernel Trick
The kernel trick is a mathematical technique that allows us to compute the dot product of two vectors in a high-dimensional space without explicitly mapping the vectors to that space. This is particularly useful when the transformation to the high-dimensional space is computationally expensive or even impossible to compute directly.
A kernel function
Here,
Common kernel functions include:
- Linear Kernel:
- Polynomial Kernel:
- Radial Basis Function (RBF) Kernel:
The choice of kernel function depends on the problem at hand. For example, the RBF kernel is often used when the data is not linearly separable.
Support Vector Machines (SVMs) with Kernel Functions
A Support Vector Machine (SVM) is a supervised learning algorithm used for classification and regression tasks. The goal of an SVM is to find the hyperplane that best separates the data into different classes. When the data is not linearly separable, we can use kernel functions to map the data to a higher-dimensional space where it becomes separable.
Let’s implement a kernel SVM using the scikit-learn library. We’ll use the famous Iris dataset for classification.
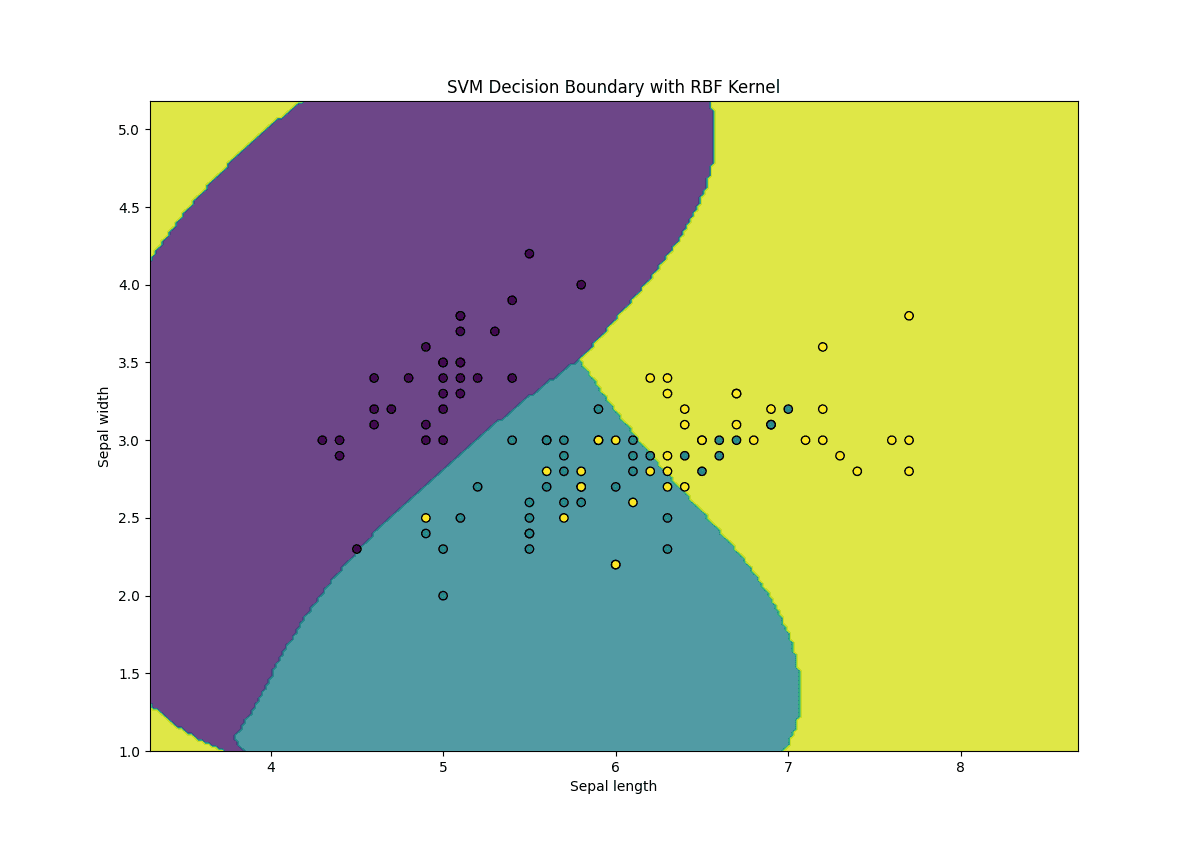
Here’s what’s going on in the above code:
- Kernel Selection: We use the RBF kernel (kernel=’rbf’) to handle non-linear data
- Gamma Parameter: The gamma parameter controls the influence of each training example, where a higher gamma value results in a more complex decision boundary
- C Parameter: The C parameter controls the trade-off between achieving a low training error and a low testing error
Kernel Principal Component Analysis (Kernel PCA)
Principal Component Analysis (PCA) is a dimensionality reduction technique that projects data onto a lower-dimensional space while preserving as much variance as possible. However, standard PCA is limited to linear transformations. Kernel PCA extends PCA by using kernel functions to perform non-linear dimensionality reduction.
Let’s implement Kernel PCA using scikit-learn and apply it to a non-linear dataset.
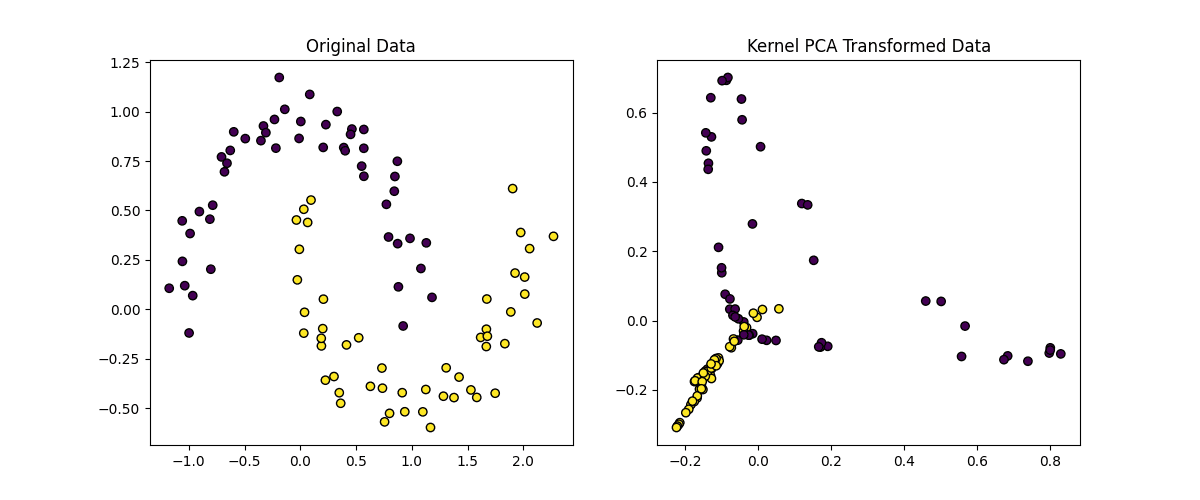
Here’s an explanation of the code above:
- Kernel Selection: We use the RBF kernel (kernel=’rbf’) to capture non-linear relationships in the data
- Gamma Parameter: The gamma parameter controls the influence of each data point, where a higher gamma value results in a more complex transformation
- Number of Components: We reduce the data to 2 dimensions (n_components=2) for visualization
Implementing the Kernel Trick from Scratch
A quick reminder: the kernel trick allows us to compute the dot product of two vectors in a high-dimensional space without explicitly mapping the vectors to that space. This is done using a kernel function, which directly computes the dot product in the transformed space.
Let’s implement the Radial Basis Function (RBF) kernel from scratch and use it to compute the kernel matrix for a dataset. The RBF kernel is defined as:
Where:
Step 1: Define the RBF Kernel Function
Let’s start with the RBF kernel function.
Step 2: Compute the Kernel Matrix
The kernel matrix (or Gram matrix) is a matrix where each element
Step 3: Apply the Kernel Trick to a Simple Dataset
Let’s generate a simple 2D dataset and compute its kernel matrix using the RBF kernel.
The kernel matrix will look something like this:
Step 4: Use the Kernel Matrix in a Kernelized Algorithm
Now that we have the kernel matrix, we can use it in a kernelized algorithm, such as a kernel SVM. However, implementing a full kernel SVM from scratch is complex, so we’ll use the kernel matrix to demonstrate the concept.
For example, in a kernel SVM, the decision function for a new data point
Where:
While we won’t implement the full SVM here, the kernel matrix is a crucial component of kernelized algorithms.
Here is a summary of the kernel trick implementation:
- we implemented the RBF kernel function from scratch
- we computed the kernel matrix for a dataset using the RBF kernel
- the kernel matrix can be used in kernelized algorithms like kernel SVMs or kernel PCA
This implementation demonstrates the core idea of the kernel trick: working in a high-dimensional space without explicitly transforming the data. You can extend this approach to implement other kernel functions (e.g., polynomial kernel) or use the kernel matrix in custom kernelized algorithms.
Benefits of Kernel Trick vs. Explicit Transformation
So, why do we use the kernel trick instead of explicit transformation?
Explicit Transformation
Suppose we have a 2D dataset
Here,
And the output of the above code would be:
Here, we explicitly computed the new features in the 5D space. This works fine for small datasets and low-dimensional transformations, but it becomes problematic for:
- High-dimensional data: If the original data has many features, the transformed space can explode in size
- Complex transformations: Some transformations (e.g., RBF) map data into an infinite-dimensional space, which is impossible to compute explicitly.
Let’s now contrast this with the kernel trick.
Kernel Trick
The kernel trick avoids explicitly computing
And the output:
Here, we never explicitly computed
Method Comparison
Here’s why explicit transformation is problematic:
- Computational Cost: Explicitly transforming data into a high-dimensional space requires computing and storing the new features, which can be computationally expensive
- Infinite Dimensions: Some transformations (e.g., RBF) map data into an infinite-dimensional space, which is impossible to compute explicitly
- Memory Usage: Storing the transformed data can require a lot of memory, especially for large datasets
Explicit transformation TL;DR: Directly computes the transformed features
Conversely, the kernel trick is particularly useful when:
- The transformed feature space is very high-dimensional or infinite-dimensional
- You want to avoid the computational cost of explicitly transforming the data
- You are working with kernelized algorithms like SVMs, Kernel PCA, or Gaussian Processes
Kernel trick TL;DR: Avoids explicit transformation by computing the dot product
Conclusion
Kernel methods are a powerful tool in machine learning, enabling us to handle non-linear data efficiently. In this tutorial, we explored the kernel trick, kernel SVMs, and Kernel PCA, and provided practical Python examples to help you get started with these techniques.
By mastering kernel methods, you can tackle a wide range of machine learning problems, from classification to dimensionality reduction, with greater flexibility and efficiency.







No comments:
Post a Comment