The Long Short-Term Memory (LSTM) network in Keras supports multiple input features.
This raises the question as to whether lag observations for a univariate time series can be used as features for an LSTM and whether or not this improves forecast performance.
In this tutorial, we will investigate the use of lag observations as features in LSTM models in Python.
After completing this tutorial, you will know:
- How to develop a test harness to systematically evaluate LSTM features for time series forecasting.
- The impact of using a varied number of lagged observations as input features for LSTM models.
- The impact of using a varied number of lagged observations and matching numbers of neurons for LSTM models.
Tutorial Overview
This tutorial is divided into 4 parts. They are:
- Shampoo Sales Dataset
- Experimental Test Harness
- Experiments with Timesteps
- Experiments with Timesteps and Neurons
Environment
This tutorial assumes you have a Python SciPy environment installed. You can use either Python 2 or 3 with this example.
This tutorial assumes you have Keras v2.0 or higher installed with either the TensorFlow or Theano backend.
This tutorial also assumes you have scikit-learn, Pandas, NumPy, and Matplotlib installed.
Shampoo Sales Dataset
This dataset describes the monthly number of sales of shampoo over a 3-year period.
The units are a sales count and there are 36 observations. The original dataset is credited to Makridakis, Wheelwright, and Hyndman (1998).
The example below loads and creates a plot of the loaded dataset.
Running the example loads the dataset as a Pandas Series and prints the first 5 rows.
A line plot of the series is then created showing a clear increasing trend.
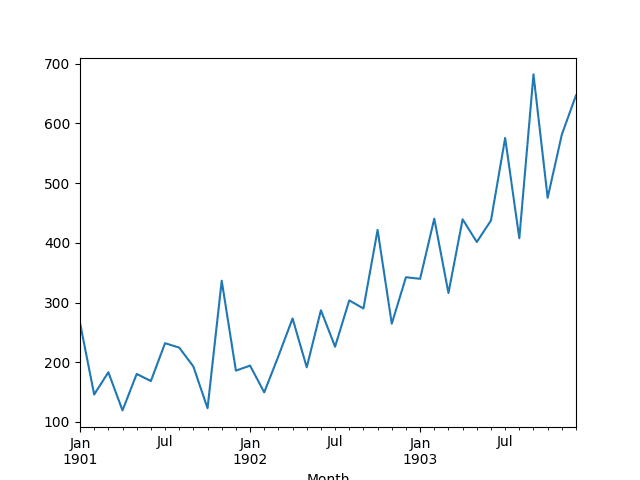
Line Plot of Shampoo Sales Dataset
Next, we will take a look at the LSTM configuration and test harness used in the experiment.
Experimental Test Harness
This section describes the test harness used in this tutorial.
Data Split
We will split the Shampoo Sales dataset into two parts: a training and a test set.
The first two years of data will be taken for the training dataset and the remaining one year of data will be used for the test set.
Models will be developed using the training dataset and will make predictions on the test dataset.
The persistence forecast (naive forecast) on the test dataset achieves an error of 136.761 monthly shampoo sales. This provides a lower acceptable bound of performance on the test set.
Model Evaluation
A rolling-forecast scenario will be used, also called walk-forward model validation.
Each time step of the test dataset will be walked one at a time. A model will be used to make a forecast for the time step, then the actual expected value from the test set will be taken and made available to the model for the forecast on the next time step.
This mimics a real-world scenario where new Shampoo Sales observations would be available each month and used in the forecasting of the following month.
This will be simulated by the structure of the train and test datasets.
All forecasts on the test dataset will be collected and an error score calculated to summarize the skill of the model. The root mean squared error (RMSE) will be used as it punishes large errors and results in a score that is in the same units as the forecast data, namely monthly shampoo sales.
Data Preparation
Before we can fit an LSTM model to the dataset, we must transform the data.
The following three data transforms are performed on the dataset prior to fitting a model and making a forecast.
- Transform the time series data so that it is stationary. Specifically, a lag=1 differencing to remove the increasing trend in the data.
- Transform the time series into a supervised learning problem. Specifically, the organization of data into input and output patterns where the observation at the previous time step is used as an input to forecast the observation at the current time step
- Transform the observations to have a specific scale. Specifically, to rescale the data to values between -1 and 1 to meet the default hyperbolic tangent activation function of the LSTM model.
These transforms are inverted on forecasts to return them into their original scale before calculating and error score.
LSTM Model
We will use a base stateful LSTM model with 1 neuron fit for 500 epochs.
A batch size of 1 is required as we will be using walk-forward validation and making one-step forecasts for each of the final 12 months of test data.
A batch size of 1 means that the model will be fit using online training (as opposed to batch training or mini-batch training). As a result, it is expected that the model fit will have some variance.
Ideally, more training epochs would be used (such as 1000 or 1500), but this was truncated to 500 to keep run times reasonable.
The model will be fit using the efficient ADAM optimization algorithm and the mean squared error loss function.
Experimental Runs
Each experimental scenario will be run 10 times.
The reason for this is that the random initial conditions for an LSTM network can result in very different results each time a given configuration is trained.
Let’s dive into the experiments.
Experiments with Features
We will perform 5 experiments; each will use a different number of lag observations as features from 1 to 5.
A representation with a 1 input feature would be the default representation when using a stateful LSTM. Using 2 to 5 features is contrived. The hope would be that the additional context from the lagged observations may improve performance of the predictive model.
The univariate time series is converted to a supervised learning problem before training the model. The specified number of features defines the number of input variables (X) used to predict the next observation (y). As such, for each feature used in the representation, that many rows must be removed from the beginning of the dataset. This is because there are no prior observations to use as features for the first values in the dataset.
The complete code listing for testing 1 input feature is provided below.
The features parameter in the run() function is varied from 1 to 5 for each of the 5 experiments. In addition, the results are saved to file at the end of the experiment and this filename must also be changed for each different experimental run, e.g. experiment_features_1.csv, experiment_features_2.csv, etc.
Run the 5 different experiments for the 5 different numbers of features.
You can run them in parallel if you have sufficient memory and CPU resources. GPU resources are not required for these experiments and runs should be complete in minutes to tens of minutes.
After running the experiments, you should have 5 files containing the results, as follows:
- experiment_features_1.csv
- experiment_features_2.csv
- experiment_features_3.csv
- experiment_features_4.csv
- experiment_features_5.csv
We can write some code to load and summarize these results.
Specifically, it is useful to review both descriptive statistics from each run and compare the results for each run using a box and whisker plot.
Code to summarize the results is listed below.
Running the code first prints descriptive statistics for each set of results.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
We can see from the average performance alone that the default of using a single feature resulted in the best performance. This is also shown when reviewing the median test RMSE (50th percentile).
A box and whisker plot comparing the distributions of results is also created.
The plot tells the same story as the descriptive statistics. The test RMSE seems to leap up with 2 features and trend upward as the number of features is increased.
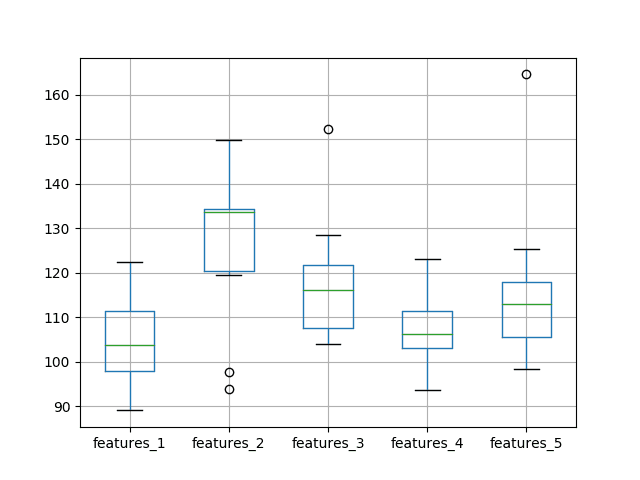
Box and Whisker Plot of Test RMSE vs The Number of Input Features
The expectation of decreased error with the increase of features was not observed, at least with the dataset and LSTM configuration used.
This raises the question as to whether the capacity of the network is a limiting factor. We will look at this in the next section.
Experiments with Features and Neurons
The number of neurons (also called units) in the LSTM network defines its learning capacity.
It is possible that in the previous experiments the use of one neuron limited the learning capacity of the network such that it was not capable of making effective use of the lagged observations as features.
We can repeat the above experiments and increase the number of neurons in the LSTM with the increase in features and see if it results in an increase in performance.
This can be achieved by changing the line in the experiment function from:
to
In addition, we can keep the results written to file separate from the results from the first experiment by adding a “_neurons” suffix to the filenames, for example, changing:
to
Repeat the same 5 experiments with these changes.
After running these experiments, you should have 5 result files.
- experiment_features_1_neurons.csv
- experiment_features_2_neurons.csv
- experiment_features_3_neurons.csv
- experiment_features_4_neurons.csv
- experiment_features_5_neurons.csv
As in the previous experiment, we can load the results, calculate descriptive statistics, and create a box and whisker plot. The complete code listing is below.
Running the code first prints descriptive statistics from each of the 5 experiments.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
The results tell a different story to the first set of experiments with a one neuron LSTM. The average test RMSE appears lowest when the number of neurons and the number of features is set to one, then error increases as neurons and features are increased.
A box and whisker plot is created to compare the distributions.
The trend in spread and median performance almost shows a linear increase in test RMSE as the number of neurons and input features is increased.
The linear trend may suggest that the increase network capacity is not given sufficient time to fit the data. Perhaps an increase in the number of epochs would be required as well.
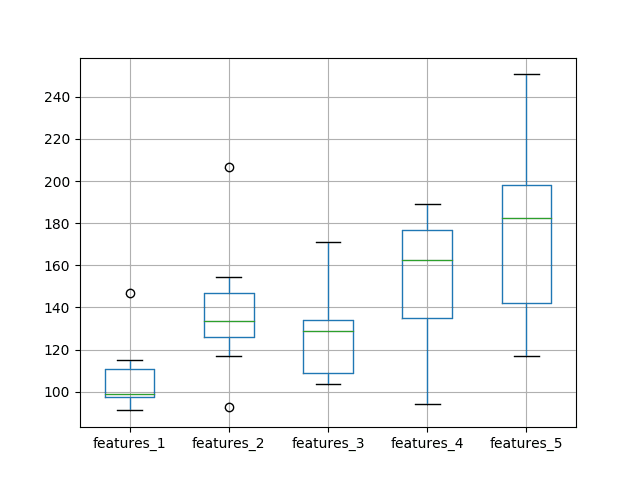
Box and Whisker Plot of Test RMSE vs The Number of Neurons and Input Features
Experiments with Features and Neurons More Epochs
In this section, we repeat the above experiment to increase the number of neurons with the number of features but double the number of training epochs from 500 to 1000.
This can be achieved by changing the line in the experiment function from:
to
In addition, we can keep the results written to file separate from the results from the previous experiment by adding a “1000” suffix to the filenames, for example, changing:
to
Repeat the same 5 experiments with these changes.
After running these experiments, you should have 5 result files.
- experiment_features_1_neurons1000.csv
- experiment_features_2_neurons1000.csv
- experiment_features_3_neurons1000.csv
- experiment_features_4_neurons1000.csv
- experiment_features_5_neurons1000.csv
As in the previous experiment, we can load the results, calculate descriptive statistics, and create a box and whisker plot. The complete code listing is below.
Running the code first prints descriptive statistics from each of the 5 experiments.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
The results tell a very similar story to the previous experiment with half the number of training epochs. On average, a model with 1 input feature and 1 neuron outperformed the other configurations.
A box and whisker plot was also created to compare the distributions. In the plot, we see the same trend as was clear in the descriptive statistics.
At least on this problem and with the chosen LSTM configuration, we do not see any clear benefit in increasing the number of input features.
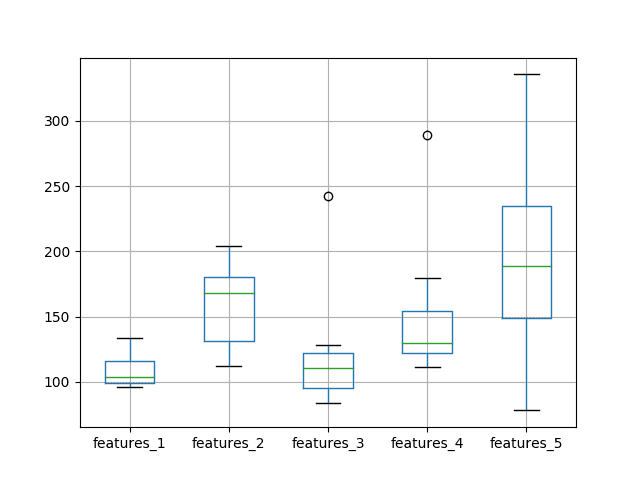
Box and Whisker Plot of Test RMSE vs The Number of Neurons and Input Features and 1000 Epochs
Extensions
This section lists some areas for further investigation that you may consider exploring.
- Diagnostic Run Plots. It may be helpful to review plots of train and test RMSE over epochs for multiple runs for a given experiment. This might help tease out whether overfitting or underfitting is taking place, and in turn, methods to address it.
- Increase Repeats. Using 10 repeats results in a relatively small population of test RMSE results. It is possible that increasing repeats to 30 or 100 (or even higher) may result in a more stable outcome.
Did you explore any of these extensions?
Share your findings in the comments below; I’d love to hear what you found.Summary
In this tutorial, you discovered how to investigate using lagged observations as input features in an LSTM network.
Specifically, you learned:
- How to develop a robust test harness for experimenting with input representation with LSTMs.
- How to use lagged observations as input features for time series forecasting with LSTMs.
- How to increase the learning capacity of the network with the increase of input features.
You discovered that the expectation that “the use of lagged observations as input features improves model skill” did not decrease the test RMSE on the chosen problem and LSTM configuration.
Do you have any questions?
Ask your questions in the comments below and I will do my best to answer them.






No comments:
Post a Comment