R
ecent advances have made deep neural networks the leading paradigm of artificial intelligence. One of the great things about deep neural networks is that, given a large number of examples, they can learn how to act. This means we can get software to learn to do things that even their programmers don’t know how to do. The more complicated the task is, the more powerful the neural net has to be.
Although inspired by brain architecture, research on neural nets usually doesn’t have anything to do with actual neurons. But in a recent analysis, Hebrew University of Jerusalem neuroscientist David Beniaguev and his team found out just how powerful a deep neural net would need to be to replicate the behavior of a single neuron. The surprising result: a really, really powerful one.
Think of many of the brain’s 10 billion neurons as being deep networks themselves.
With artificial neural nets, rather than directly programming in the rules of thought, the programmer instead makes a system that can learn from input data. It’s called a neural network because its architecture is inspired by neurons in brains—although the “units” in an artificial neural network are far simpler than biological neurons.
An artificial neural network is exposed to thousands, sometimes hundreds of thousands, of examples. Every time it experiences a new example, it subtly changes the links between the units to produce a better output. You might train a neural network to determine if a picture is of a child or an adult. Over time, the program learns how to do it well.
Notoriously, however, even when we have a working neural network, the explanation for how it does what it does is unknown and requires further study and analysis: What we end up with are numeric “weights” between thousands of units, which are difficult to look at and derive general principles from. Traditional (“shallow”) neural networks had only three layers (one input, one hidden, and one output).
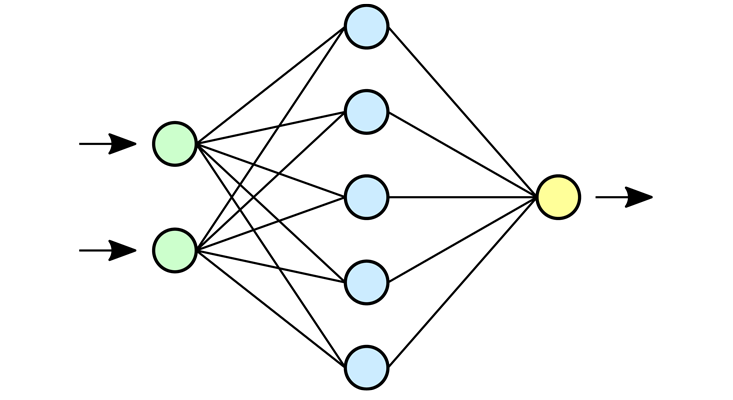
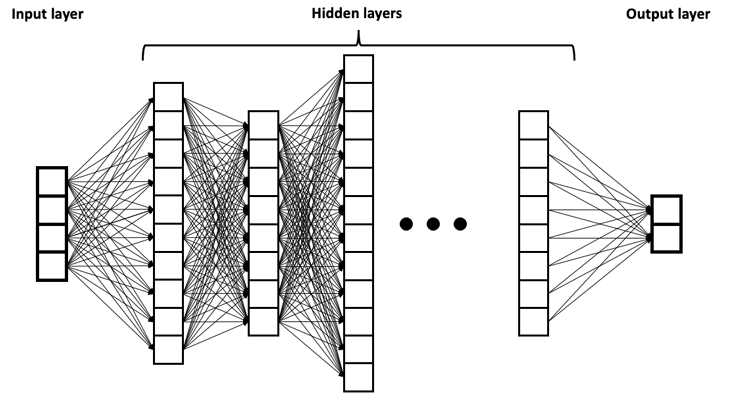
In the past decade, more hidden layers have been effectively used, which is why they are called “deep” neural networks that do “deep learning.”
This makes artificial neural networks particularly useful for situations where we don’t understand what thinking would be involved to do the task. How would you describe to somebody how to tell the difference between the faces of Jesse Eisenberg and Michael Cera? Nobody knows, but, with a lot of images, you could train a neural net to figure it out. The network learns for itself from examples, and we don’t need to know how we would have programmed it in a traditional way.
So how did the neuroscientists Beniaguev, Segev, and London use neural nets to understand biological neurons better? Previous neuroscience has come up with partial differential equations to describe neural behavior, and the team used these equations to calculate what the neurons would do when given thousands of randomly generated possible inputs. Then they used these inputs and outputs to train deep neural nets. Their question was: How complex would the deep learning neural net have to be to model what the equations produced?
One way to estimate the complexity of a neural net architecture is to look at how many layers are used—deep nets are called “deep” because they have more than one hidden layer. Another measure of complexity is the number of units in each hidden layer.
It turns out that modeling some neurons doesn’t require deep networks at all. One kind of neuron is the “integrate-and-fire.” All this neuron does is add up its excitatory input, subtract the inhibitory input, and then fire if the amount is greater than some threshold. The researchers were able to model this with a traditional “shallow” neural net (a single hidden layer with only one unit!).
Things were different when they tried to model a more complex kind of neuron found in the cerebral cortex (the L5 cortical pyramidal, or L5PC neuron). What they found was that these individual neurons are much more complex than we’d previously thought: Artificial networks (the temporal-convolutional type) needed a full seven layers, each with 128 units, to successfully simulate these pyramidal neurons.
Deeper investigation suggests that these neurons don’t simply fire or not fire given their immediate input. Rather, they integrate input over tens of milliseconds. The dendrites (the input structures of neurons) seem to be doing significant processing by themselves, using information about space (where the input came in) as well as time (when each input arrived). Each neuron is, as the authors put it, a “sophisticated computational unit,” all by itself.
In fact, rather than thinking that the brain works like a deep learning network, it might be more accurate to think of many of the brain’s 10 billion neurons as being deep networks, with five to eight layers in each one. If true, this would mean that the brain’s computational capabilities are much greater than we’d thought, and that simulating the brain at a biological level will involve staggeringly large computational resources. (This is bad news for scientists like me, who hope to model human minds on machines to better understand them.)
The silver lining is that, complex as deep learning networks are, they are computationally more efficient than the more thorough description given by the partial differential equations, thousands of which need to be solved for each neuron. The neural network is about 2,000 times faster to compute, and future deep learning designs will likely make this even faster






No comments:
Post a Comment