Understanding RAG Part I: Why It’s Needed
Natural language processing (NLP) is an area of artificial intelligence (AI) aimed at teaching computers to understand written and verbal human language and interact with humans by using such a language. Whilst traditional NLP methods have been studied for decades, the recent emergence of large language models (LLMs) has virtually taken over all developments in the field. By combining sophisticated deep learning architectures with the self-attention mechanism capable of analyzing complex patterns and interdependences in language, LLMs have revolutionized the field of NLP and AI as a whole, due to the wide range of language generation and language understanding tasks they can address and their range of applications: conversational chatbots, in-depth document analysis, translation, and more.

Some of the tasks LLMs most frequently perform
LLM Capabilities and Limitations
The largest general-purpose LLMs launched by major AI firms, such as OpenAI’s ChatGPT models, mainly specialize in language generation, that is, given a prompt — a query, question, or request formulated by a user in human language — the LLM must produce a natural language response to that prompt, generating it word by word. To make this seemingly arduous task possible, LLMs are trained upon extremely vast datasets consisting of millions to billions of text documents ranging from any topic(s) you can imagine. This way, LLMs comprehensively learn the nuances of human language, mimicking how we communicate and using the learned knowledge to produce “human-like language” of their own, enabling fluent human-machine communication at unprecedented levels.
There’s no doubt LLMs have meant a big step forward in AI developments and horizons, yet they are not exempt from their limitations. Concretely, if a user asks an LLM for a precise answer in a certain context (for instance, the latest news), the model may not be able to provide a specific and accurate response by itself. The reason: LLMs’ knowledge about the world is limited to the data they have been exposed to, particularly during their training stage. An LLM would normally not be aware of the latest news unless it keeps being retrained frequently (which, we are not going to lie, is an overly expensive process).
What is worse, when LLMs lack ground information to provide a precise, relevant, or truthful answer, there is a significant risk they may still generate a convincing-looking response, even though that means formulating it upon completely invented information. This frequent problem in LLMs is known as hallucinations: generating inexact and unfounded text, thereby misleading the user.
Why RAG Emerged
Even the largest LLMs in the market have suffered from data obsolescence, costly retraining, and hallucination problems to some degree, and tech giants are well aware of the risks and impact they constitute when these models are used by millions of users across the globe. The prevalence of hallucinations in earlier ChatGPT models, for instance, was estimated at around 15%, having profound implications for the reputation of organizations using them and compromising the reliability and trust in AI systems as a whole.
This is why RAG (retrieval augmented generation) came onto the scene. RAG has unquestionably been one of the major NLP breakthroughs following the emergence of LLMs, due to their effective approach to addressing the LLM limitations above. The key idea behind RAG is to synthesize the accuracy and search capabilities of information retrieval techniques typically used by search engines, with the in-depth language understanding and generation capabilities of LLMs.
In broad terms, RAG systems enhance LLMs by incorporating up-to-date and truthful contextual information in user queries or prompts. This context is obtained as a result of a retrieval phase before the language understanding and subsequent response generation process led by the LLM.
Here’s how RAG can help addressing the aforementioned problems traditionally found in LLMs:
- Data obsolescence: RAG can help overcome data obsolescence by retrieving and integrating up-to-date information from outer sources so that responses reflect the latest knowledge available
- Re-training costs: by dynamically retrieving relevant information, RAG reduces the necessity of frequent and costly re-training, allowing LLMs to stay current without being fully retrained
- Hallucinations: RAG helps mitigate hallucinations by grounding responses in factual information retrieved from real documents, minimizing the generation of false or made-up responses lacking any truthfulness
At this point, we hope you gained an initial understanding of what RAG is and why it arose to improve existing LLM solutions. The next article in this series will dive deeper into understanding the general approach to how RAG processes work.
Understanding RAG Part II: How Classic RAG Works
n the first post in this series, we introduced retrieval augmented generation (RAG), explaining that it became necessary to expand the capabilities of conventional large language models (LLMs). We also briefly outlining what is the key idea underpinning RAG: retrieving contextually relevant information from external knowledge bases to ensure that LLMs produce accurate and up-to-date information, without suffering from hallucinations and without the need for constantly re-training the model.
The second article in this revealing series demystifies the mechanisms under which a conventional RAG system operates. While many enhanced and more sophisticated versions of RAG keep spawning almost daily as part of the frantic AI progress nowadays, the first step to understanding the latest state-of-the-art RAG approaches is to first comprehend the classic RAG workflow.
The Classic RAG Workflow
A typical RAG system (depicted in the diagram below) handles three key data-related components:
- An LLM that has acquired knowledge from the data it has been trained with, typically millions to billions of text documents.
- A vector database, also called knowledge base storing text documents. But why the name vector database? In RAG and natural language processing (NLP) systems as a whole, text information is transformed into numerical representations called vectors, capturing the semantic meaning of the text. Vectors represent words, sentences, or entire documents, maintaining key properties of the original text such that two similar vectors are associated with words, sentences, or pieces of text with similar semantics. Storing text as numerical vectors enhances the system’s efficiency, such that relevant documents are quickly found and retrieved.
- Queries or prompts formulated by the user in natural language.
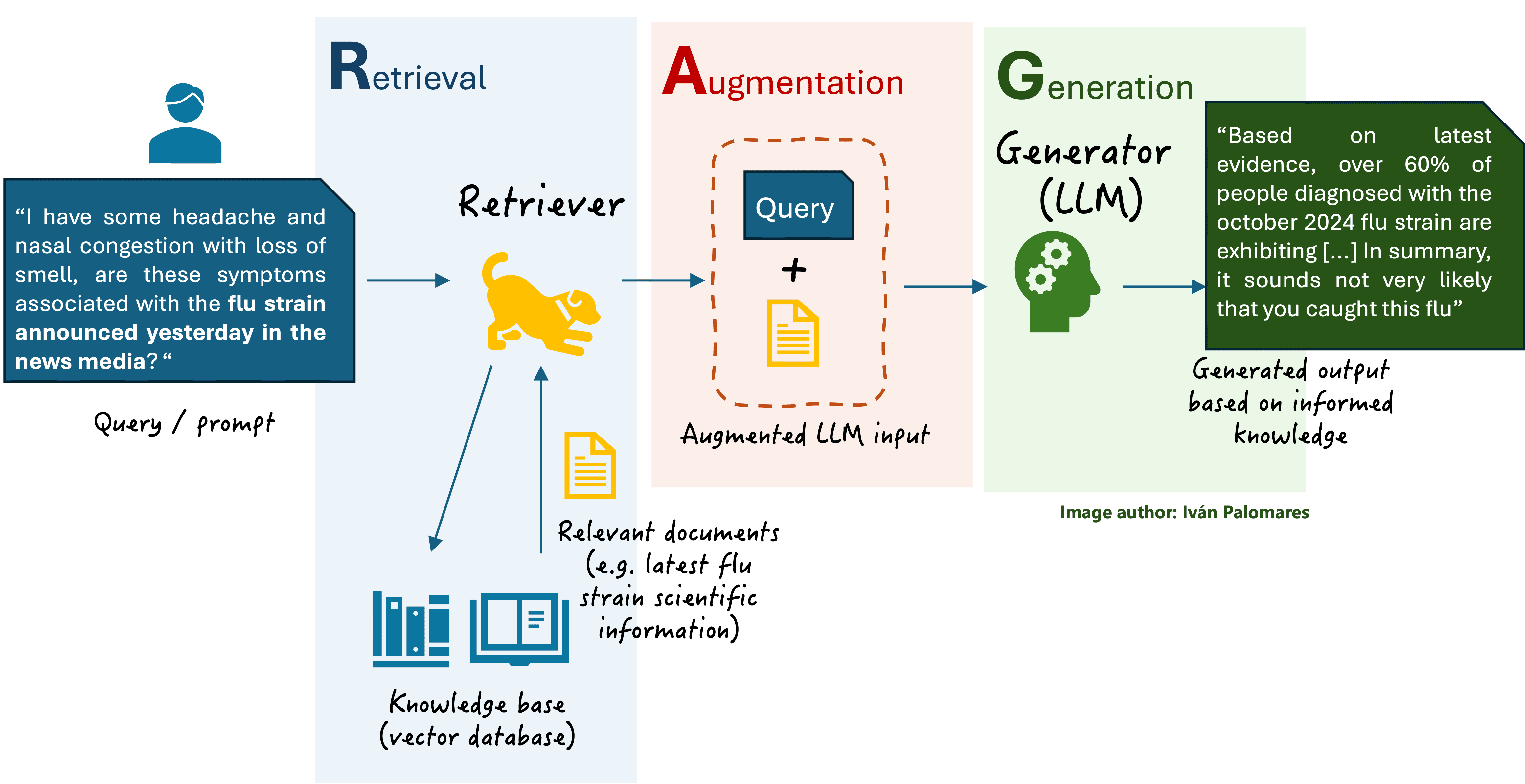
General scheme of a basic RAG system
In a nutshell, when the user asks a question in natural language to an LLM-based assistant endowed with an RAG engine, three stages take place between sending the question and receiving the answer:
- Retrieval: a component called retriever accesses the vector database to find and retrieve relevant documents to the user query.
- Augmentation: the original user query is augmented by incorporating contextual knowledge from the retrieved documents.
- Generation: the LLM -also commonly referred to as generator from an RAG viewpoint- receives the user query augmented with relevant contextual information and generates a more precise and truthful text response.
Inside the Retriever
The retriever is the component in an RAG system that finds relevant information to enhance the final output later generated by the LLM. You can picture it like an enhanced search engine that doesn’t just match keywords in the user query to stored documents but understands the meaning behind the query.
The retriever scans a vast body of domain knowledge related to the query, stored in vectorized format (numerical representations of text), and pulls out the most relevant pieces of text to build a context around them which is attached to the original user query. A common technique to identify relevant knowledge is similarity search, where the user query is encoded into a vector representation, and this vector is compared to stored vector data. This way, detecting the most relevant pieces of knowledge to the user query, boils down to iteratively performing some mathematical calculations to identify the closest (most similar) vectors to the vector representation of that query. And thus, the retriever manages to pull accurate, context-aware information not only efficiently, but also accurately.
Inside the Generator
The generator in RAG is typically a sophisticated language model, often an LLM based on transformer architecture, which takes the augmented input from the retriever and produces an accurate, context-aware, and usually truthful response. This outcome normally surpasses the quality of a standalone LLM by incorporating relevant external information.
Inside the model, the generation process involves both understanding and generating text, managed by components that encode the augmented input and generate output text word by word. Each word is predicted based on the preceding words: this task, performed as the last stage inside the LLM, is known as the next-word prediction problem: predicting the most likely next word to maintain coherence and relevance in the message being generated.
This post further elaborates on the language generation process led by the generator.
Looking Ahead
In the next post in this article series about understanding RAG, we will uncover fusion methods for RAG, characterized by using specialized approaches for combining information from multiple retrieved documents, thereby enhancing the context for generating a response.
One common example of fusion methods in RAG is reranking, which involves scoring and prioritizing multiple retrieved documents based on their user relevance before passing the most relevant ones to the generator. This helps further improve the quality of the augmented context, and the eventual responses produced by the language model.
Understanding RAG III: Fusion Retrieval and Reranking
Having previously introduced what is RAG, why it matters in the context of Large Language Models (LLMs), and what does a classic retriever-generator system for RAG look like, the third post in the "Understanding RAG" series examines an upgraded approach to building RAG systems: fusion retrieval.
Before deep diving, it is worth briefly revisiting the basic RAG scheme we explored in part II of this series.
Basic RAG scheme
Fusion Retrieval Explained
Fusion retrieval approaches involve the fusion or aggregation of multiple information flows during the retrieval stage of a RAG system. Recall that during the retrieval phase, the retriever -an information retrieval engine- takes the original user query for the LLM, encodes it into a vector numerical representation, and uses it to search in a vast knowledge base for documents that strongly match the query. After that, the original query is augmented by adding additional context information resulting from the retrieved documents, finally sending the augmented input to the LLM that generates a response.
By applying fusion schemes in the retrieval stage, the context added on top of the original query can become more coherent and contextually relevant, further improving the final response generated by the LLM. Fusion retrieval leverages the knowledge from multiple pulled documents (search results) and combines it into a more meaningful and accurate context. However, the basic RAG scheme we are already familiar with can also retrieve multiple documents from the knowledge base, not necessarily just one. So, what is the difference between the two approaches?
The key difference between classic RAG and fusion retrieval lies in how the multiple retrieved documents are processed and integrated into the final response. In classic RAG, the content in the retrieved documents is simply concatenated or, at most, extractively summarized, and then fed as additional context into the LLM to generate the response. There are no advanced fusion techniques applied. Meanwhile, in fusion retrieval, more specialized mechanisms are used to combine relevant information across multiple documents. This fusion process can occur either in the augmentation stage (retrieval stage) or even in the generation stage.
- Fusion in the augmentation stage consists of applying techniques to reorder, filter, or combine multiple documents before they are passed to the generator. Two examples of this are reranking, where documents are scored and ordered by relevance before being fed into the model alongside the user prompt, and aggregation, where the most relevant pieces of information from each document are merged into a single context. Aggregation is applied through classic information retrieval methods like TF-IDF (Term Frequency - Inverse Document Frequency), operations on embeddings, etc.
- Fusion in the generation stage involves the LLM (the generator) processing each retrieved document independently -including the user prompt- and fusing the information of several processing jobs during the generation of the final response. Broadly speaking, the augmentation stage in RAG becomes part of the generation stage. One common method in this category is Fusion-in-Decoder (FiD), which allows the LLM to process each retrieved document separately and then combine their insights while generating the final response. The FiD approach is described in detail in this paper.
Reranking is one of the simplest yet effective fusion approaches to meaningfully combine information from multiple retrieved sources. The next section briefly explains how it works:
How Reranking Works
In a reranking process, the initial set of documents fetched by the retriever is reordered to improve relevance to the user query, thereby better accommodating the user's needs and enhancing the overall output quality. The retriever passes the fetched documents to an algorithmic component called a ranker, which re-evaluates the retrieved results based criteria like learned user preferences, and applies a sorting of documents aimed at maximizing the relevance of the results presented to that particular user. Mechanisms like like weighted averaging or other forms of scoring are used to combine and prioritize the documents in the highest positions of the ranking, such that content from documents ranked near the top is more likely to become part of the final, combined context than content from documents ranked at lower positions.
The following diagram illustrates the reranking mechanism:
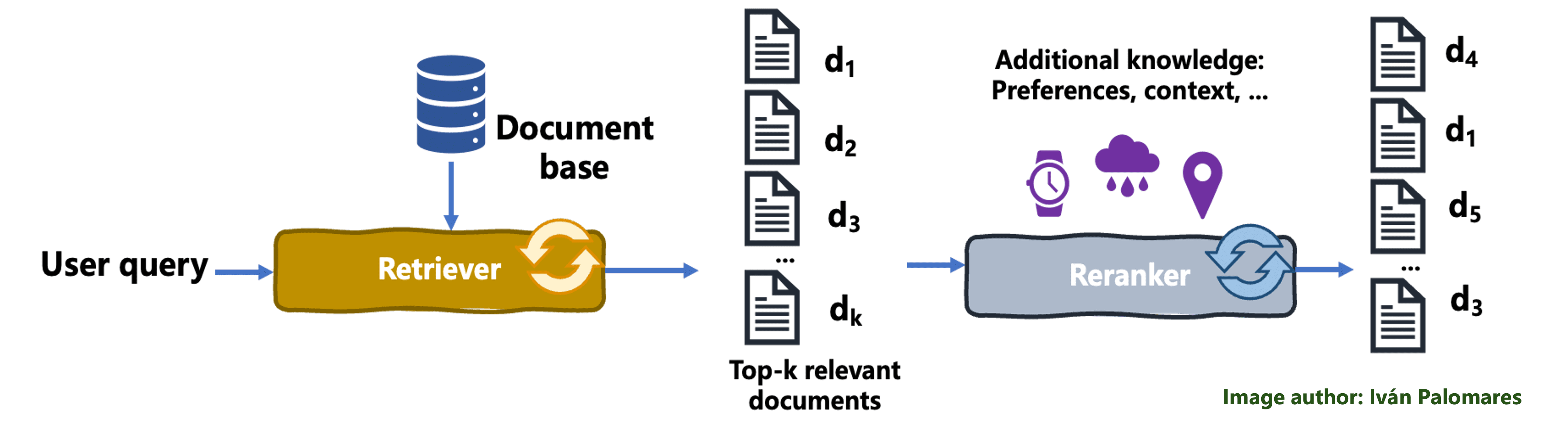
The reranking process
Let’s describe an example to better understand reranking, in the context of tourism in Eastern Asia. Imagine a traveler querying a RAG system for "top destinations for nature lovers in Asia." An initial retrieval system might return a list of documents including general travel guides, articles on popular Asian cities, and recommendations for natural parks. However, a reranking model, possibly using additional traveler-specific preferences and contextual data (like preferred activities, previously liked activities or previous destinations), can reorder these documents to prioritize the most relevant content to that user. It might highlight serene national parks, lesser-known hiking trails, and eco-friendly tours that might not be at the top of everyone's list of suggestions, thereby offering results that go “straight to the point” for nature-loving tourists like our target user.
In summary, reranking reorganizes multiple retrieved documents based on additional user relevance criteria to focus the content extraction process in documents ranked first, thereby improving relevance of subsequent generated responses.
Understanding RAG Part IV: RAGAs & Other Evaluation Frameworks
Retrieval augmented generation (RAG) has played a pivotal role in expanding the limits and overcoming many limitations of standalone large language models (LLMs). By incorporating a retriever, RAG enhances response relevance and factual accuracy: all it takes is leveraging external knowledge sources like vector document bases in real-time, and adding relevant contextual information to the original user query or prompt before passing it to the LLM for the output generation process.
A natural question arises for those diving into the realm of RAG: how can we evaluate these far-from-simple systems?
There exist several frameworks to this end, like DeepEval, which offers over 14 evaluation metrics to assess criteria like hallucination and faithfulness; MLflow LLM Evaluate, known for its modularity and simplicity, enabling evaluations within custom pipelines; and RAGAs, which focuses on defining RAG pipelines, providing metrics such as faithfulness and contextual relevancy to compute a comprehensive RAGAs quality score.
Here’s a summary of these three frameworks:
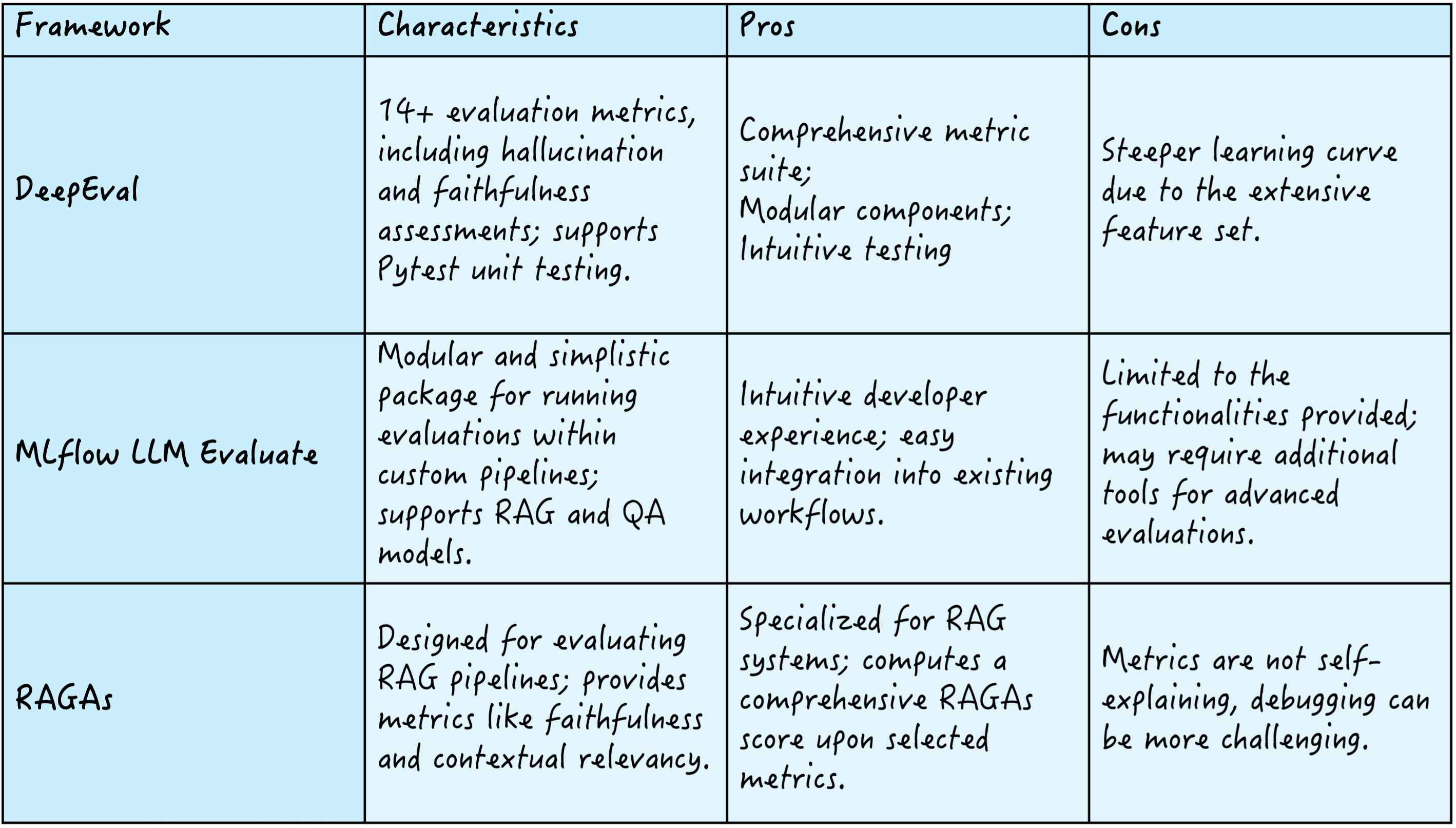
RAG evaluation frameworks
Let’s further examine the latter: RAGAs.
Understanding RAGAs
RAGAs (an abbreviation for retrieval augmented generation assessment) is considered one of the best toolkits for evaluating LLM applications. It succeeds in evaluating the performance of a RAG system’s components &madsh; namely the retriever and the generator in its simplest approach — both in isolation and jointly as a single pipeline.
A core element of RAGAs is its metric-driven development (MDD) approach, which relies on data to make well-informed system decisions. MDD entails continuously monitoring essential metrics over time, providing clear insights into an application’s performance. Besides allowing developers to assess their LLM/RAG applications and undertake metric-assisted experiments, the MDD approach aligns well with application reproducibility.
RAGAs components
- Prompt object: A component that defines the structure and content of the prompts employed to elicit responses generated by the language model. By abiding with consistent and clear prompts, it facilitates accurate evaluations.
- Evaluation Sample: An individual data instance that encapsulates a user query, the generated response, and the reference response or ground truth (similar to LLM metrics like ROUGE, BLEU, and METEOR). It serves as the basic unit to assess an RAG system’s performance.
- Evaluation dataset: A set of evaluation samples used to evaluate the overall RAG system’s performance more systematically, based on various metrics. It aims to comprehensively appraise the system’s effectiveness and reliability.
RAGAs Metrics
RAGAs offers the capability of configuring your RAG system metrics, by defining the specific metrics for the retriever and the generator, and blending them into an overall RAGAs score, as depicted in this visual example:

RAGAs score | Image credits: RAGAs documentation
Let’s navigate some of the most common metrics in the retrieval and generation sides of things.
Retrieval performance metrics:
- Contextual recall: The recall measures the fraction of relevant documents retrieved from the knowledge base across the ground-truth top-k results, i.e., how many of the most relevant documents to answer the prompt have been retrieved? It is calculated by dividing the number of relevant retrieved documents by the total number of relevant documents.
- Contextual precision: Within the retrieved documents, how many are relevant to the prompt, instead of being noise? This is the question answered by contextual precision, which is computed by dividing the number of relevant retrieved documents by the total number of retrieved documents.
Generation performance metrics:
- Faithfulness: It evaluates whether the generated response aligns with the retrieved evidence, in other words, the response’s factual accuracy. This is usually done by comparing the response and retrieved documents.
- Contextual Relevancy: This metric determines how relevant the generated response is to the query. It is typically computed either based on human judgment or via automated semantic similarity scoring (e.g., cosine similarity).
As an example metric that bridges both aspects of a RAG system — retrieval and generation — we have:
- Context utilization: This evaluates how effectively an RAG system utilizes the retrieved context to generate its response. Even if the retriever fetched excellent context (high precision and recall), poor generator performance may fail to use it effectively, context utilization was proposed to capture this nuance.
In the RAGAs framework, individual metrics are combined to calculate an overall RAGAs score that comprehensively quantifies the RAG system’s performance. The process to calculate this score entails selecting relevant metrics and calculating them, normalizing them to move in the same range (normally 0-1), and computing a weighted average of the metrics. Weights are assigned depending on each use case’s priorities, for instance, you might want to prioritize faithfulness over recall for systems requiring strong factual accuracy.
More about RAGAs metrics and their calculation through Python examples can be found here.
Wrapping Up
This article introduces and provides a general understanding of RAGAs: a popular evaluation framework to systematically measure several aspects of RAG systems performance, both from an information retrieval and text generation standpoint. Understanding the key elements of this framework is the first step towards mastering its practical use to leverage high-performing RAG applications. Conventional large language models (LLMs) had context length limit, which restricts the amount of information processed in a single user-model interaction, as one of their major limitations. Addressing this limitation has been one of the main courses of action in the LLMs development community, raising awareness of the advantages of increasing context length in producing more coherent and accurate responses. For example, GPT-3 — released in 2020 — had a context length of 2048 tokens, while its younger but more powerful sibling GPT-4 Turbo — born in 2023 — allows a whooping 128K tokens in a single prompt. Needless to say this is equivalent to being able to process an entire book in a single interaction, for instance, to summarize it.
Retrieval augmented generation (RAG), on the other hand, incorporates external knowledge from retrieved documents (usually vector databases) to enhance the context and relevance of LLM outputs. Managing context length in RAG systems is, however, still a challenge, as in certain scenarios requiring substantial contextual information, efficient selection and summarization of retrieved information are necessitated to stay below the LLM’s input limit without losing essential knowledge.
Strategies for Long Context Management in RAG
There are several strategies for RAG systems to incorporate as much relevant retrieved knowledge as possible in the initial user query before passing it to the LLM, and stay within the model’s input limits. Four of them are outlined below, from simplest to most sophisticated.
1. Document Chunking
Document chunking is generally the simplest strategy, it focuses on splitting documents in the vector database into smaller chunks. Whilst it may not sound obvious at first glance, this strategy helps overcome the context length limitation of LLMs inside RAG systems in various ways, for instance by reducing the risk of retrieving redundant information while keeping contextual integrity in chunks.
2. Selective Retrieval
Selective retrieval consists of applying a filtering process on a large set of relevant documents to retrieve only the most highly relevant parts, narrowing down the size of the input sequence passed to the LLM. By intelligently filtering parts of the retrieved documents to be retained, its target is to avoid incorporating irrelevant or extraneous information.
3. Targeted Retrieval
While similar to selective retrieval, the essence of targeted retrieval is retrieving data with a very concrete intent or final response in mind. This is achieved by optimizing the retriever mechanisms for specific types of query or data sources, e.g. building specialized retrievers for medical texts, news articles, recent science breakthroughs, and so on. In short, it constitutes an evolved and more specialized form of selective retrieval with additional domain-specific criteria in the loop.
4. Context Summarization
Context summarization is a more sophisticated approach to manage context length in RAG systems, in which we apply text summarization techniques in the process of building the final context. One possible way to do this is by using an additional language model -often smaller and trained for summarization tasks- that summarizes large chunks of retrieved documents. This summarization task can be extractive or abstractive, the former identifying and extracting relevant text passages, and the latter generating from scratch a summary that rephrases and condenses the original chunks. Alternatively, some RAG solutions use heuristic methods to assess the relevance of pieces of text e.g. chunks, discarding less relevant ones.
| Strategy | Summary |
|---|---|
| Document Chunking | Splits documents into smaller, coherent chunks to preserve context while reducing redundancy and staying within LLM limits. |
| Selective Retrieval | Filters large sets of relevant documents to retrieve only the most pertinent parts, minimizing extraneous information. |
| Targeted Retrieval | Optimizes retrieval for specific query intents using specialized retrievers, adding domain-specific criteria to refine results. |
| Context Summarization | Uses extractive or abstractive summarization techniques to condense large amounts of retrieved content, ensuring essential information is passed to the LLM. |
Long-Context Language Models
And how about long-context LLMs? Wouldn’t that be enough, without the need for RAG?
That’s an important question to address. Long-context LLMs (LC-LLMs) are “extra-large” LLMs capable of accepting very long sequences of input tokens. Despite research evidence that LC-LLMs often outperform RAG systems, the latter still have particular advantages, most notably in scenarios requiring dynamic real-time information retrieval and cost efficiency. In these applications, it is worth pondering the use of a smaller LLM wrapped in an RAG system that use the above described strategies, instead of an LC-LLM. None of them are one-fits-all solutions, and both of them will be able to shine in particular settings they are suited for.
Wrapping Up
This article introduced and described four strategies for managing context length in RAG systems and dealing with long contexts in situations where LLMs in such systems might have limitations in the length of inputs they can accept in single user interactions. While the use of so-called Long-Context LLMs has recently become a trend to overcome this issue, there are situations when sticking to RAG systems might still be worth it, especially in dynamic information retrieval scenarios requiring real-time up-to-date contexts.







No comments:
Post a Comment