Unlock the Power of Artificial Intelligence, Machine Learning, and Data Science with our Blog
Discover the latest insights, trends, and innovations in Artificial Intelligence (AI), Machine Learning (ML), and Data Science through our informative and engaging Hubspot blog. Gain a deep understanding of how these transformative technologies are shaping industries and revolutionizing the way we work.
Stay updated with cutting-edge advancements, practical applications, and real-world use.
Saturday, 21 December 2024
How to Develop a Multichannel CNN Model for Text Classification
A standard deep learning model fortext classificationandsentiment analysisuses a word embedding layer and one-dimensional convolutional neural network.
The model can be expanded by using multiple parallel convolutional neural networks that read the source document using different kernel sizes. This, in effect, creates a multichannel convolutional neural network for text that reads text with different n-gram sizes (groups of words).
In this tutorial, you will discover how to develop a multichannel convolutional neural network for sentiment prediction on text movie review data.
After completing this tutorial, you will know:
How to prepare movie review text data for modeling.
How to develop a multichannel convolutional neural network for text in Keras.
How to evaluate a fit model on unseen movie review data.
Tutorial Overview
This tutorial is divided into 4 parts; they are:
Movie Review Dataset
Data Preparation
Develop Multichannel Model
Evaluate Model
Python Environment
This tutorial assumes you have a Python 3 SciPy environment installed.
You must have Keras (2.0 or higher) installed with either the TensorFlow or Theano backend.
The tutorial also assumes you have scikit-learn, Pandas, NumPy, and Matplotlib installed.
If you need help with your environment, see this post:
Take my free 7-day email crash course now (with code).
Click to sign-up and also get a free PDF Ebook version of the course.
Movie Review Dataset
The Movie Review Data is a collection of movie reviews retrieved from the imdb.com website in the early 2000s by Bo Pang and Lillian Lee. The reviews were collected and made available as part of their research on natural language processing.
The reviews were originally released in 2002, but an updated and cleaned up version was released in 2004, referred to as “v2.0”.
The dataset is comprised of 1,000 positive and 1,000 negative movie reviews drawn from an archive of the rec.arts.movies.reviews newsgroup hosted at imdb.com. The authors refer to this dataset as the “polarity dataset.”
Our data contains 1000 positive and 1000 negative reviews all written before 2002, with a cap of 20 reviews per author (312 authors total) per category. We refer to this corpus as the polarity dataset.
The data has been cleaned up somewhat; for example:
The dataset is comprised of only English reviews.
All text has been converted to lowercase.
There is white space around punctuation like periods, commas, and brackets.
Text has been split into one sentence per line.
The data has been used for a few related natural language processing tasks. For classification, the performance of machine learning models (such as Support Vector Machines) on the data is in the range of high 70% to low 80% (e.g. 78%-82%).
More sophisticated data preparation may see results as high as 86% with 10-fold cross-validation. This gives us a ballpark of low-to-mid 80s if we were looking to use this dataset in experiments of modern methods.
… depending on choice of downstream polarity classifier, we can achieve highly statistically significant improvement (from 82.8% to 86.4%)
After unzipping the file, you will have a directory called “txt_sentoken” with two sub-directories containing the text “neg” and “pos” for negative and positive reviews. Reviews are stored one per file with a naming convention cv000 to cv999 for each neg and pos.
Next, let’s look at loading and preparing the text data.
Data Preparation
In this section, we will look at 3 things:
Separation of data into training and test sets.
Loading and cleaning the data to remove punctuation and numbers.
Prepare all reviews and save to file.
Split into Train and Test Sets
We are pretending that we are developing a system that can predict the sentiment of a textual movie review as either positive or negative.
This means that after the model is developed, we will need to make predictions on new textual reviews. This will require all of the same data preparation to be performed on those new reviews as is performed on the training data for the model.
We will ensure that this constraint is built into the evaluation of our models by splitting the training and test datasets prior to any data preparation. This means that any knowledge in the data in the test set that could help us better prepare the data (e.g. the words used) is unavailable in the preparation of data used for training the model.
That being said, we will use the last 100 positive reviews and the last 100 negative reviews as a test set (100 reviews) and the remaining 1,800 reviews as the training dataset.
This is a 90% train, 10% split of the data.
The split can be imposed easily by using the filenames of the reviews where reviews named 000 to 899 are for training data and reviews named 900 onwards are for test.
Loading and Cleaning Reviews
The text data is already pretty clean; not much preparation is required.
Without getting bogged down too much by the details, we will prepare the data in the following way:
Split tokens on white space.
Remove all punctuation from words.
Remove all words that are not purely comprised of alphabetical characters.
Remove all words that are known stop words.
Remove all words that have a length <= 1 character.
We can put all of these steps into a function called clean_doc() that takes as an argument the raw text loaded from a file and returns a list of cleaned tokens. We can also define a function load_doc() that loads a document from file ready for use with the clean_doc() function. An example of cleaning the first positive review is listed below.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
from nltk.corpus import stopwords
import string
# load doc into memory
def load_doc(filename):
# open the file as read only
file=open(filename,'r')
# read all text
text=file.read()
# close the file
file.close()
returntext
# turn a doc into clean tokens
def clean_doc(doc):
# split into tokens by white space
tokens=doc.split()
# remove punctuation from each token
table=str.maketrans('','',string.punctuation)
tokens=[w.translate(table)forwintokens]
# remove remaining tokens that are not alphabetic
tokens=[wordforwordintokens ifword.isalpha()]
# filter out stop words
stop_words=set(stopwords.words('english'))
tokens=[wforwintokens ifnotwinstop_words]
# filter out short tokens
tokens=[wordforwordintokens iflen(word)>1]
returntokens
# load the document
filename='txt_sentoken/pos/cv000_29590.txt'
text=load_doc(filename)
tokens=clean_doc(text)
print(tokens)
Running the example loads and cleans one movie review.
The tokens from the clean review are printed for review.
We can now use the function to clean reviews and apply it to all reviews.
To do this, we will develop a new function named process_docs() below that will walk through all reviews in a directory, clean them, and return them as a list.
We will also add an argument to the function to indicate whether the function is processing train or test reviews, that way the filenames can be filtered (as described above) and only those train or test reviews requested will be cleaned and returned.
The full function is listed below.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# load all docs in a directory
def process_docs(directory,is_trian):
documents=list()
# walk through all files in the folder
forfilename inlistdir(directory):
# skip any reviews in the test set
ifis_trian andfilename.startswith('cv9'):
continue
ifnotis_trian andnotfilename.startswith('cv9'):
continue
# create the full path of the file to open
path=directory+'/'+filename
# load the doc
doc=load_doc(path)
# clean doc
tokens=clean_doc(doc)
# add to list
documents.append(tokens)
returndocuments
We can call this function with negative training reviews as follows:
Next, we need labels for the train and test documents. We know that we have 900 training documents and 100 test documents. We can use a Python list comprehension to create the labels for the negative (0) and positive (1) reviews for both train and test sets.
1
2
trainy=[0for_inrange(900)]+[1for_inrange(900)]
testY=[0for_inrange(100)]+[1for_inrange(100)]
Finally, we want to save the prepared train and test sets to file so that we can load them later for modeling and model evaluation.
The function below-named save_dataset() will save a given prepared dataset (X and y elements) to a file using the pickle API.
1
2
3
4
# save a dataset to file
def save_dataset(dataset,filename):
dump(dataset,open(filename,'wb'))
print('Saved: %s'%filename)
Complete Example
We can tie all of these data preparation steps together.
Running the example cleans the text movie review documents, creates labels, and saves the prepared data for both train and test datasets in train.pkl and test.pkl respectively.
Now we are ready to develop our model.
Develop Multichannel Model
In this section, we will develop a multichannel convolutional neural network for the sentiment analysis prediction problem.
This section is divided into 3 parts:
Encode Data
Define Model.
Complete Example.
Encode Data
The first step is to load the cleaned training dataset.
The function below-named load_dataset() can be called to load the pickled training dataset.
1
2
3
4
5
# load a clean dataset
def load_dataset(filename):
returnload(open(filename,'rb'))
trainLines,trainLabels=load_dataset('train.pkl')
Next, we must fit a Keras Tokenizer on the training dataset. We will use this tokenizer to both define the vocabulary for the Embedding layer and encode the review documents as integers.
The function create_tokenizer() below will create a Tokenizer given a list of documents.
1
2
3
4
5
# fit a tokenizer
def create_tokenizer(lines):
tokenizer=Tokenizer()
tokenizer.fit_on_texts(lines)
returntokenizer
We also need to know the maximum length of input sequences as input for the model and to pad all sequences to the fixed length.
The function max_length() below will calculate the maximum length (number of words) for all reviews in the training dataset.
1
2
3
# calculate the maximum document length
def max_length(lines):
returnmax([len(s.split())forsinlines])
We also need to know the size of the vocabulary for the Embedding layer.
This can be calculated from the prepared Tokenizer, as follows:
1
2
# calculate vocabulary size
vocab_size=len(tokenizer.word_index)+1
Finally, we can integer encode and pad the clean movie review text.
The function below named encode_text() will both encode and pad text data to the maximum review length.
A standard model for document classification is to use an Embedding layer as input, followed by a one-dimensional convolutional neural network, pooling layer, and then a prediction output layer.
The kernel size in the convolutional layer defines the number of words to consider as the convolution is passed across the input text document, providing a grouping parameter.
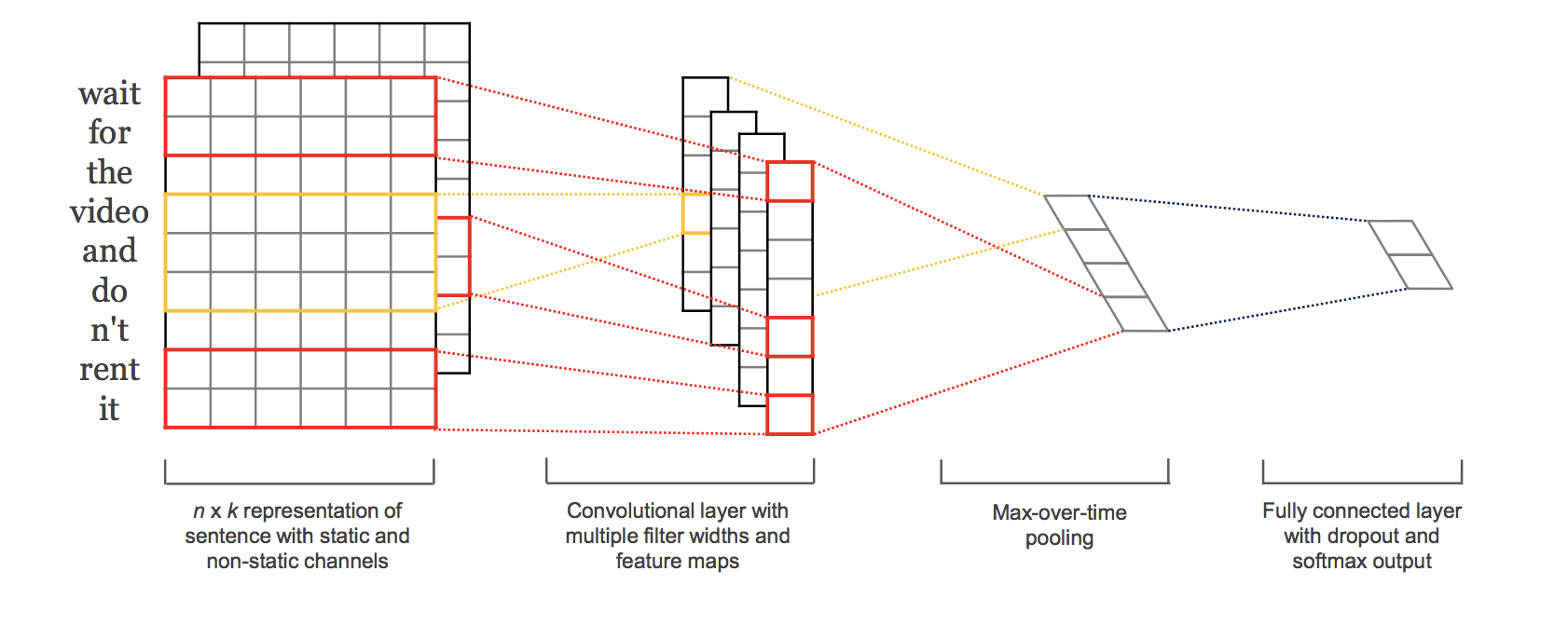
A multi-channel convolutional neural network for document classification involves using multiple versions of the standard model with different sized kernels. This allows the document to be processed at different resolutions or different n-grams (groups of words) at a time, whilst the model learns how to best integrate these interpretations.
In the paper, Kim experimented with static and dynamic (updated) embedding layers, we can simplify the approach and instead focus only on the use of different kernel sizes.
This approach is best understood with a diagram taken from Kim’s paper:
Depiction of the multiple-channel convolutional neural network for text. Taken from “Convolutional Neural Networks for Sentence Classification.”
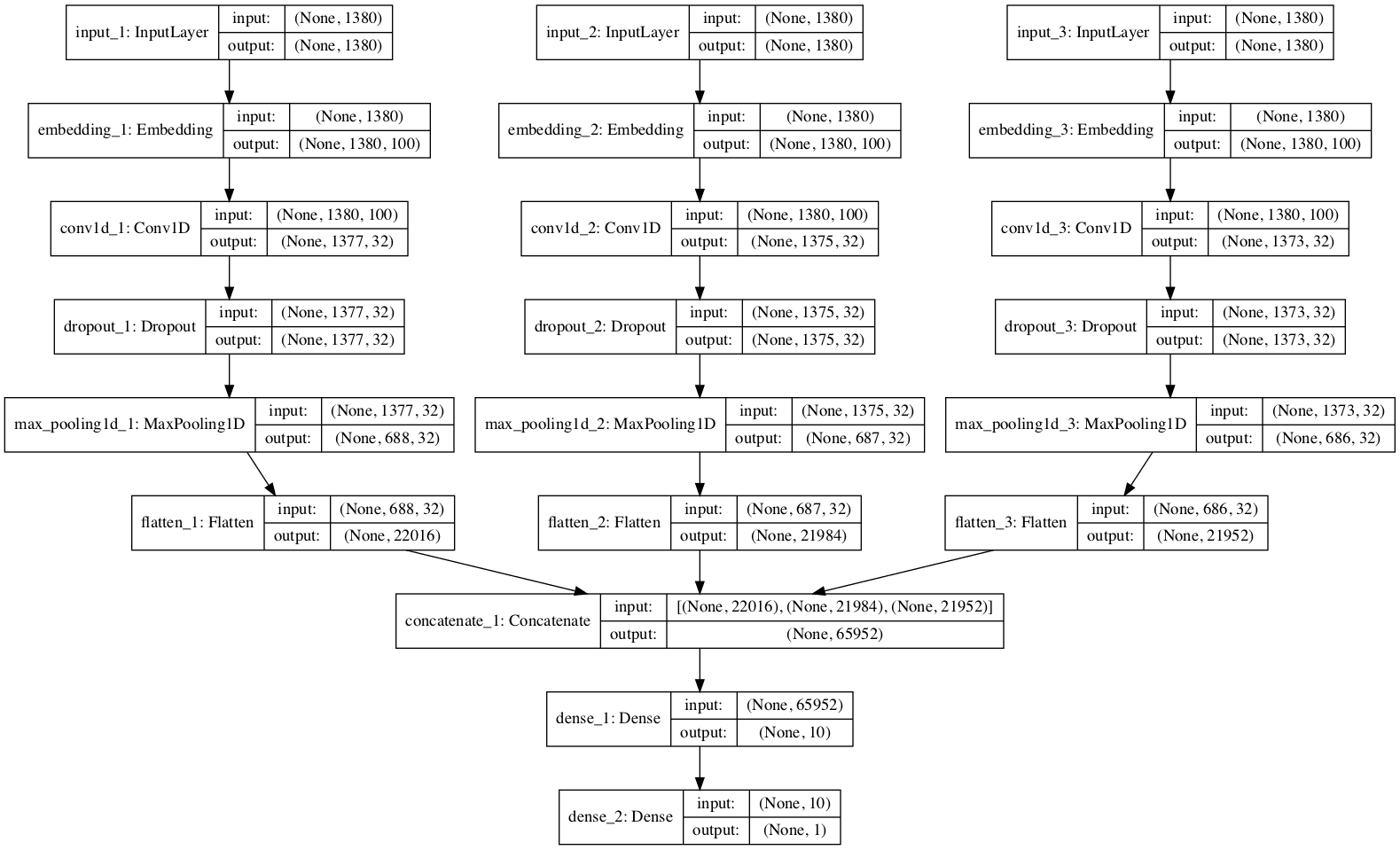
In Keras, a multiple-input model can be defined using the functional API.
We will define a model with three input channels for processing 4-grams, 6-grams, and 8-grams of movie review text.
Each channel is comprised of the following elements:
Input layer that defines the length of input sequences.
Embedding layer set to the size of the vocabulary and 100-dimensional real-valued representations.
One-dimensional convolutional layer with 32 filters and a kernel size set to the number of words to read at once.
Max Pooling layer to consolidate the output from the convolutional layer.
Flatten layer to reduce the three-dimensional output to two dimensional for concatenation.
The output from the three channels are concatenated into a single vector and process by a Dense layer and an output layer.
The function below defines and returns the model. As part of defining the model, a summary of the defined model is printed and a plot of the model graph is created and saved to file.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
Running the example prints the skill of the model on both the training and test datasets.
1
2
3
4
5
6
Max document length: 1380
Vocabulary size: 44277
(1800, 1380) (200, 1380)
Train Accuracy: 100.000000
Test Accuracy: 87.500000
We can see that, as expected, the skill on the training dataset is excellent, here at 100% accuracy.
We can also see that the skill of the model on the unseen test dataset is also very impressive, achieving 87.5%, which is above the skill of the model reported in the 2014 paper (although not a direct apples-to-apples comparison).
Extensions
This section lists some ideas for extending the tutorial that you may wish to explore.
Different n-grams. Explore the model by changing the kernel size (number of n-grams) used by the channels in the model to see how it impacts model skill.
More or Fewer Channels. Explore using more or fewer channels in the model and see how it impacts model skill.
Deeper Network. Convolutional neural networks perform better in computer vision when they are deeper. Explore using deeper models here and see how it impacts model skill.
Further Reading
This section provides more resources on the topic if you are looking to go deeper.





No comments:
Post a Comment