The encoder-decoder model provides a pattern for using recurrent neural networks to address challenging sequence-to-sequence prediction problems, such as machine translation.
Encoder-decoder models can be developed in the Keras Python deep learning library and an example of a neural machine translation system developed with this model has been described on the Keras blog, with sample code distributed with the Keras project.
In this post, you will discover how to define an encoder-decoder sequence-to-sequence prediction model for machine translation, as described by the author of the Keras deep learning library.
After reading this post, you will know:
- The neural machine translation example provided with Keras and described on the Keras blog.
- How to correctly define an encoder-decoder LSTM for training a neural machine translation model.
- How to correctly define an inference model for using a trained encoder-decoder model to translate new sequences.
Kick-start your project with my new book Deep Learning for Natural Language Processing, including step-by-step tutorials and the Python source code files for all examples.
Let’s get started.
- Update Apr/2018: For an example applying this complex model, see the post: How to Develop an Encoder-Decoder Model for Sequence-to-Sequence Prediction in Keras

How to Define an Encoder-Decoder Sequence-to-Sequence Model for Neural Machine Translation in Keras
Photo by Tom Lee, some rights reserved.
Sequence-to-Sequence Prediction in Keras
Francois Chollet, the author of the Keras deep learning library, recently released a blog post that steps through a code example for developing an encoder-decoder LSTM for sequence-to-sequence prediction titled “A ten-minute introduction to sequence-to-sequence learning in Keras“.
The code developed in the blog post has also been added to Keras as an example in the file lstm_seq2seq.py.
The post develops a sophisticated implementation of the encoder-decoder LSTM as described in the canonical papers on the topic:
- Sequence to Sequence Learning with Neural Networks, 2014.
- Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation, 2014.
The model is applied to the problem of machine translation, the same as the source papers in which the approach was first described. Technically, the model is a neural machine translation model.
Francois’ implementation provides a template for how sequence-to-sequence prediction can be implemented (correctly) in the Keras deep learning library at the time of writing.
In this post, will take a closer look at exactly how the training and inference models were designed and how they work.
You will be able to use this understanding to develop similar models for your own sequence-to-sequence prediction problems.
Need help with Deep Learning for Text Data?
Take my free 7-day email crash course now (with code).
Click to sign-up and also get a free PDF Ebook version of the course.
Machine Translation Data
The dataset used in the example involves short French and English sentence pairs used in the flash card software Anki.
The dataset is called “Tab-delimited Bilingual Sentence Pairs” and is part of the Tatoeba Project and listed on the ManyThings.org site for helping English as a Second Language students.
The dataset used in the tutorial can be downloaded from here:
Below is a sample of the first 10 rows from the fra.txt data file you will see after you unzip the downloaded archive.
The problem is framed as a sequence prediction problem where input sequences of characters are in English and output sequences of characters are in French.
A total of 10,000 of the nearly 150,000 examples in the data file are used in the dataset. Some technical details of the prepared data are as follows:
- Input Sequences: Padded to a maximum length of 16 characters with a vocabulary of 71 different characters (10000, 16, 71).
- Output Sequences: Padded to a maximum length of 59 characters with a vocabulary of 93 different characters (10000, 59, 93).
The training data is framed such that the input for the model is comprised of one whole input sequence of English characters and the whole output sequence of French characters. The output of the model is the whole sequence of French characters, but offset forward by one time step.
For example (with minimal padding and without one-hot encoding):
- Input1: [‘G’, ‘o’, ‘.’, ”]
- Input2: [ ”, ‘V’, ‘a’, ‘ ‘]
- Output: [‘V’, ‘a’, ‘ ‘, ‘!’]
Machine Translation Model
The neural translation model is an encoder-decoder recurrent neural network.
It is comprised of an encoder that reads a variable length input sequence and a decoder that predicts a variable length output sequence.
In this section, we will step through each element of the model’s definition, with code taken directly from the post and the code example in the Keras project (at the time of writing).
The model is divided into two sub-models: the encoder responsible for outputting a fixed-length encoding of the input English sequence, and the decoder responsible for predicting the output sequence, one character per output time step.
The first step is to define the encoder.
The input to the encoder is a sequence of characters, each encoded as one-hot vectors with length of num_encoder_tokens.
The LSTM layer in the encoder is defined with the return_state argument set to True. This returns the hidden state output returned by LSTM layers generally, as well as the hidden and cell state for all cells in the layer. These are used when defining the decoder.
Next, we define the decoder.
The decoder input is defined as a sequence of French character one-hot encoded to binary vectors with a length of num_decoder_tokens.
The LSTM layer is defined to both return sequences and state. The final hidden and cell states are ignored and only the output sequence of hidden states is referenced.
Importantly, the final hidden and cell state from the encoder is used to initialize the state of the decoder. This means every time that the encoder model encodes an input sequence, the final internal states of the encoder model are used as the starting point for outputting the first character in the output sequence. This also means that the encoder and decoder LSTM layers must have the same number of cells, in this case, 256.
A Dense output layer is used to predict each character. This Dense is used to produce each character in the output sequence in a one-shot manner, rather than recursively, at least during training. This is because the entire target sequence required for input to the model is known during training.
The Dense does not need to be wrapped in a TimeDistributed layer.
Finally, the model is defined with inputs for the encoder and the decoder and the output target sequence.
We can tie all of this together in a standalone example and fix the configuration and print a graph of the model. The complete code example for defining the model is listed below.
Running the example creates a plot of the defined model that may help you better understand how everything hangs together.
Note that the encoder LSTM does not directly pass its outputs as inputs to the decoder LSTM; as noted above, the decoder uses the final hidden and cell states as the initial state for the decoder.
Also note that the decoder LSTM only passes the sequence of hidden states to the Dense for output, not the final hidden and cell states as suggested by the output shape information.
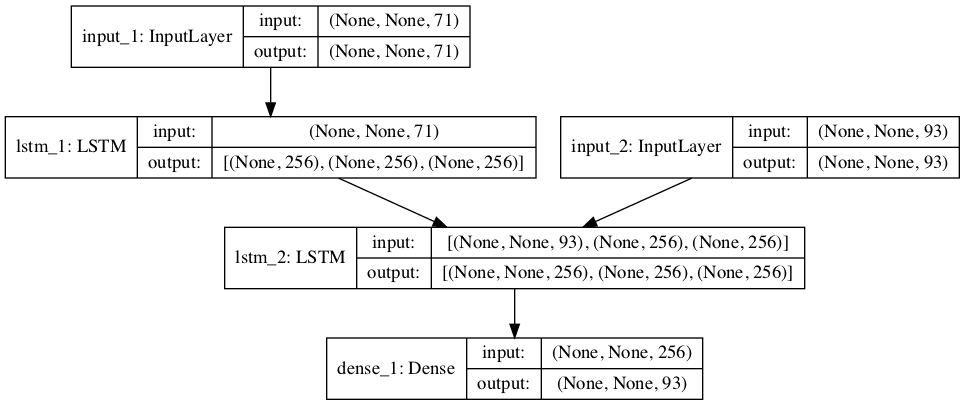
Graph of Encoder-Decoder Model For Training
Neural Machine Translation Inference
Once the defined model is fit, it can be used to make predictions. Specifically, output a French translation for an English source text.
The model defined for training has learned weights for this operation, but the structure of the model is not designed to be called recursively to generate one character at a time.
Instead, new models are required for the prediction step, specifically a model for encoding English input sequences of characters and a model that takes the sequence of French characters generated so far and the encoding as input and predicts the next character in the sequence.
Defining the inference models requires reference to elements of the model used for training in the example. Alternately, one could define a new model with the same shapes and load the weights from file.
The encoder model is defined as taking the input layer from the encoder in the trained model (encoder_inputs) and outputting the hidden and cell state tensors (encoder_states).
The decoder is more elaborate.
The decoder requires the hidden and cell states from the encoder as the initial state of the newly defined encoder model. Because the decoder is a separate standalone model, these states will be provided as input to the model, and therefore must first be defined as inputs.
They can then be specified for use as the initial state of the decoder LSTM layer.
Both the encoder and decoder will be called recursively for each character that is to be generated in the translated sequence.
On the first call, the hidden and cell states from the encoder will be used to initialize the decoder LSTM layer, provided as input to the model directly.
On subsequent recursive calls to the decoder, the last hidden and cell state must be provided to the model. These state values are already within the decoder; nevertheless, we must re-initialize the state on each call given the way that the model was defined in order to take the final states from the encoder on the first call.
Therefore, the decoder must output the hidden and cell states along with the predicted character on each call, so that these states can be assigned to a variable and used on each subsequent recursive call for a given input sequence of English text to be translated.
We can tie all of this together into a standalone code example combined with the definition of the training model of the previous section, given the reuse of some elements. The complete code listing is provided below.
Running the example defines the training model, inference encoder, and inference decoder.
Plots of all three models are then created.
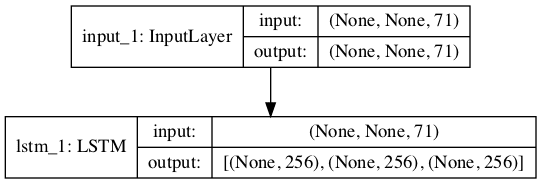
Graph of Encoder Model For Inference
The plot of the encoder is straightforward.
The decoder shows the three inputs required to decode a single character in the translated sequence, the encoded translation output so far, and the hidden and cell states provided first from the encoder and then from the output of the decoder as the model is called recursively for a given translation.

Graph of Decoder Model For Inference
Further Reading
This section provides more resources on the topic if you are looking to go deeper.
- Francois Chollet on Twitter
- A ten-minute introduction to sequence-to-sequence learning in Keras
- Keras seq2seq Code Example (lstm_seq2seq)
- Keras Functional API
- LSTM API in Keras
- Long Short-Term Memory, 1997.
- Understanding LSTM Networks, 2015.
- Sequence to Sequence Learning with Neural Networks, 2014.
- Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation, 2014.
Update
For an example of how to use this model on a standalone problem, see this post:
Summary
In this post, you discovered how to define an encoder-decoder sequence-to-sequence prediction model for machine translation, as described by the author of the Keras deep learning library.
Specifically, you learned:
- The neural machine translation example provided with Keras and described on the Keras blog.
- How to correctly define an encoder-decoder LSTM for training a neural machine translation model.
- How to correctly define an inference model for using a trained encoder-decoder model to translate new sequences.
Do you have any questions?
Ask your questions in the comments below and I will do my best to answer.





No comments:
Post a Comment