Gentle introduction to CNN LSTM recurrent neural networks
with example Python code.
Input with spatial structure, like images, cannot be modeled easily with the standard Vanilla LSTM.
The CNN Long Short-Term Memory Network or CNN LSTM for short is an LSTM architecture specifically designed for sequence prediction problems with spatial inputs, like images or videos.
In this post, you will discover the CNN LSTM architecture for sequence prediction.
After completing this post, you will know:
- About the development of the CNN LSTM model architecture for sequence prediction.
- Examples of the types of problems to which the CNN LSTM model is suited.
- How to implement the CNN LSTM architecture in Python with Keras.
CNN LSTM Architecture
The CNN LSTM architecture involves using Convolutional Neural Network (CNN) layers for feature extraction on input data combined with LSTMs to support sequence prediction.
CNN LSTMs were developed for visual time series prediction problems and the application of generating textual descriptions from sequences of images (e.g. videos). Specifically, the problems of:
- Activity Recognition: Generating a textual description of an activity demonstrated in a sequence of images.
- Image Description: Generating a textual description of a single image.
- Video Description: Generating a textual description of a sequence of images.
[CNN LSTMs are] a class of models that is both spatially and temporally deep, and has the flexibility to be applied to a variety of vision tasks involving sequential inputs and outputs
— Long-term Recurrent Convolutional Networks for Visual Recognition and Description, 2015.
This architecture was originally referred to as a Long-term Recurrent Convolutional Network or LRCN model, although we will use the more generic name “CNN LSTM” to refer to LSTMs that use a CNN as a front end in this lesson.
This architecture is used for the task of generating textual descriptions of images. Key is the use of a CNN that is pre-trained on a challenging image classification task that is re-purposed as a feature extractor for the caption generating problem.
… it is natural to use a CNN as an image “encoder”, by first pre-training it for an image classification task and using the last hidden layer as an input to the RNN decoder that generates sentences
— Show and Tell: A Neural Image Caption Generator, 2015.
This architecture has also been used on speech recognition and natural language processing problems where CNNs are used as feature extractors for the LSTMs on audio and textual input data.
This architecture is appropriate for problems that:
- Have spatial structure in their input such as the 2D structure or pixels in an image or the 1D structure of words in a sentence, paragraph, or document.
- Have a temporal structure in their input such as the order of images in a video or words in text, or require the generation of output with temporal structure such as words in a textual description.
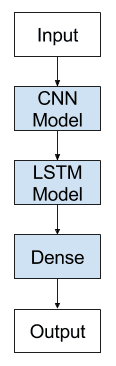
Convolutional Neural Network Long Short-Term Memory Network Architecture
Need help with LSTMs for Sequence Prediction?
Take my free 7-day email course and discover 6 different LSTM architectures (with code).
Click to sign-up and also get a free PDF Ebook version of the course.
Implement CNN LSTM in Keras
We can define a CNN LSTM model to be trained jointly in Keras.
A CNN LSTM can be defined by adding CNN layers on the front end followed by LSTM layers with a Dense layer on the output.
It is helpful to think of this architecture as defining two sub-models: the CNN Model for feature extraction and the LSTM Model for interpreting the features across time steps.
Let’s take a look at both of these sub models in the context of a sequence of 2D inputs which we will assume are images.
CNN Model
As a refresher, we can define a 2D convolutional network as comprised of Conv2D and MaxPooling2D layers ordered into a stack of the required depth.
The Conv2D will interpret snapshots of the image (e.g. small squares) and the polling layers will consolidate or abstract the interpretation.
For example, the snippet below expects to read in 10×10 pixel images with 1 channel (e.g. black and white). The Conv2D will read the image in 2×2 snapshots and output one new 10×10 interpretation of the image. The MaxPooling2D will pool the interpretation into 2×2 blocks reducing the output to a 5×5 consolidation. The Flatten layer will take the single 5×5 map and transform it into a 25-element vector ready for some other layer to deal with, such as a Dense for outputting a prediction.
This makes sense for image classification and other computer vision tasks.
LSTM Model
The CNN model above is only capable of handling a single image, transforming it from input pixels into an internal matrix or vector representation.
We need to repeat this operation across multiple images and allow the LSTM to build up internal state and update weights using BPTT across a sequence of the internal vector representations of input images.
The CNN could be fixed in the case of using an existing pre-trained model like VGG for feature extraction from images. The CNN may not be trained, and we may wish to train it by backpropagating error from the LSTM across multiple input images to the CNN model.
In both of these cases, conceptually there is a single CNN model and a sequence of LSTM models, one for each time step. We want to apply the CNN model to each input image and pass on the output of each input image to the LSTM as a single time step.
We can achieve this by wrapping the entire CNN input model (one layer or more) in a TimeDistributed layer. This layer achieves the desired outcome of applying the same layer or layers multiple times. In this case, applying it multiple times to multiple input time steps and in turn providing a sequence of “image interpretations” or “image features” to the LSTM model to work on.
We now have the two elements of the model; let’s put them together.
CNN LSTM Model
We can define a CNN LSTM model in Keras by first defining the CNN layer or layers, wrapping them in a TimeDistributed layer and then defining the LSTM and output layers.
We have two ways to define the model that are equivalent and only differ as a matter of taste.
You can define the CNN model first, then add it to the LSTM model by wrapping the entire sequence of CNN layers in a TimeDistributed layer, as follows:
An alternate, and perhaps easier to read, approach is to wrap each layer in the CNN model in a TimeDistributed layer when adding it to the main model.
The benefit of this second approach is that all of the layers appear in the model summary and as such is preferred for now.
You can choose the method that you prefer.
Further Reading
This section provides more resources on the topic if you are looking go deeper.
Papers on CNN LSTM
- Long-term Recurrent Convolutional Networks for Visual Recognition and Description, 2015.
- Show and Tell: A Neural Image Caption Generator, 2015.
- Convolutional, Long Short-Term Memory, fully connected Deep Neural Networks, 2015.
- Character-Aware Neural Language Models, 2015.
- Convolutional LSTM Network: A Machine Learning Approach for Precipitation Nowcasting, 2015.
Keras API
Posts
- Crash Course in Convolutional Neural Networks for Machine Learning
- Sequence Classification with LSTM Recurrent Neural Networks in Python with Keras
Summary
In this post, you discovered the CNN LSTN model architecture.
Specifically, you learned:
- About the development of the CNN LSTM model architecture for sequence prediction.
- Examples of the types of problems to which the CNN LSTM model is suited.
- How to implement the CNN LSTM architecture in Python with Keras.
Do you have any questions?
Ask your questions in the comments below and I will do my best to answer.





No comments:
Post a Comment