Configuring neural networks is difficult because there is no good theory on how to do it.
You must be systematic and explore different configurations both from a dynamical and an objective results point of a view to try to understand what is going on for a given predictive modeling problem.
In this tutorial, you will discover how you can explore how to configure an LSTM network on a time series forecasting problem.
After completing this tutorial, you will know:
- How to tune and interpret the results of the number of training epochs.
- How to tune and interpret the results of the size of training batches.
- How to tune and interpret the results of the number of neurons.
Tutorial Overview
This tutorial is broken down into 6 parts; they are:
- Shampoo Sales Dataset
- Experimental Test Harness
- Tuning the Number of Epochs
- Tuning the Batch Size
- Tuning the Number of Neurons
- Summary of Results
Environment
This tutorial assumes you have a Python SciPy environment installed. You can use either Python 2 or 3 with this example.
This tutorial assumes you have Keras v2.0 or higher installed with either the TensorFlow or Theano backend.
The tutorial also assumes you have scikit-learn, Pandas, NumPy and Matplotlib installed.
If you need help setting up your Python environment, see this post:
Shampoo Sales Dataset
This dataset describes the monthly number of sales of shampoo over a 3-year period.
The units are a sales count and there are 36 observations. The original dataset is credited to Makridakis, Wheelwright, and Hyndman (1998).
The example below loads and creates a plot of the loaded dataset.
Running the example loads the dataset as a Pandas Series and prints the first 5 rows.
A line plot of the series is then created showing a clear increasing trend.
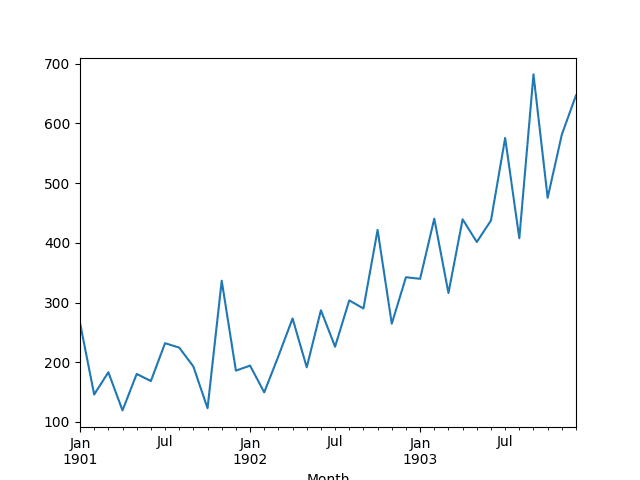
Line Plot of Shampoo Sales Dataset
Next, we will take a look at the LSTM configuration and test harness used in the experiment.
Need help with Deep Learning for Time Series?
Take my free 7-day email crash course now (with sample code).
Click to sign-up and also get a free PDF Ebook version of the course.
Experimental Test Harness
This section describes the test harness used in this tutorial.
Data Split
We will split the Shampoo Sales dataset into two parts: a training and a test set.
The first two years of data will be taken for the training dataset and the remaining one year of data will be used for the test set.
Models will be developed using the training dataset and will make predictions on the test dataset.
The persistence forecast (naive forecast) on the test dataset achieves an error of 136.761 monthly shampoo sales. This provides a lower acceptable bound of performance on the test set.
Model Evaluation
A rolling-forecast scenario will be used, also called walk-forward model validation.
Each time step of the test dataset will be walked one at a time. A model will be used to make a forecast for the time step, then the actual expected value from the test set will be taken and made available to the model for the forecast on the next time step.
This mimics a real-world scenario where new Shampoo Sales observations would be available each month and used in the forecasting of the following month.
This will be simulated by the structure of the train and test datasets. We will make all of the forecasts in a one-shot method.
All forecasts on the test dataset will be collected and an error score calculated to summarize the skill of the model. The root mean squared error (RMSE) will be used as it punishes large errors and results in a score that is in the same units as the forecast data, namely monthly shampoo sales.
Data Preparation
Before we can fit an LSTM model to the dataset, we must transform the data.
The following three data transforms are performed on the dataset prior to fitting a model and making a forecast.
- Transform the time series data so that it is stationary. Specifically, a lag=1 differencing to remove the increasing trend in the data.
- Transform the time series into a supervised learning problem. Specifically, the organization of data into input and output patterns where the observation at the previous time step is used as an input to forecast the observation at the current time time step
- Transform the observations to have a specific scale. Specifically, to rescale the data to values between -1 and 1 to meet the default hyperbolic tangent activation function of the LSTM model.
These transforms are inverted on forecasts to return them into their original scale before calculating and error score.
Experimental Runs
Each experimental scenario will be run 10 times.
The reason for this is that the random initial conditions for an LSTM network can result in very different results each time a given configuration is trained.
A diagnostic approach will be used to investigate model configurations. This is where line plots of model skill over time (training iterations called epochs) will be created and studied for insight into how a given configuration performs and how it may be adjusted to elicit better performance.
The model will be evaluated on both the train and the test datasets at the end of each epoch and the RMSE scores saved.
The train and test RMSE scores at the end of each scenario are printed to give an indication of progress.
The series of train and test RMSE scores are plotted at the end of a run as a line plot. Train scores are colored blue and test scores are colored orange.
Let’s dive into the results.
Tuning the Number of Epochs
The first LSTM parameter we will look at tuning is the number of training epochs.
The model will use a batch size of 4, and a single neuron. We will explore the effect of training this configuration for different numbers of training epochs.
Diagnostic of 500 Epochs
The complete code listing for this diagnostic is listed below.
The code is reasonably well commented and should be easy to follow. This code will be the basis for all future experiments in this tutorial and only the changes made in each subsequent experiment will be listed.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
Running the experiment prints the RMSE for the train and the test sets at the end of each of the 10 experimental runs.
A line plot of the series of RMSE scores on the train and test sets after each training epoch is also created.
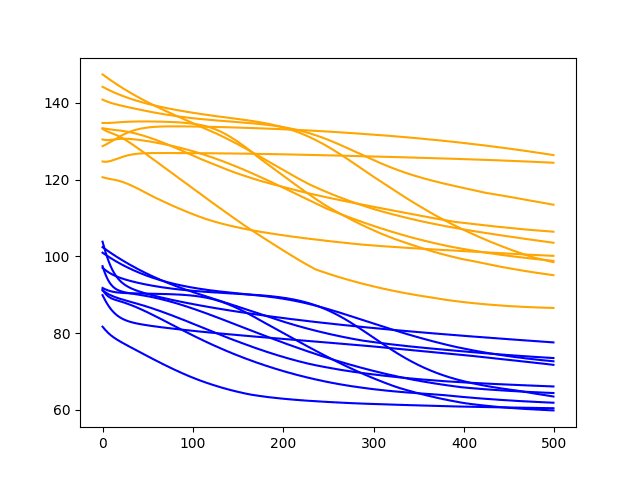
Diagnostic Results with 500 Epochs
The results clearly show a downward trend in RMSE over the training epochs for almost all of the experimental runs.
This is a good sign, as it shows the model is learning the problem and has some predictive skill. In fact, all of the final test scores are below the error of a simple persistence model (naive forecast) that achieves an RMSE of 136.761 on this problem.
The results suggest that more training epochs will result in a more skillful model.
Let’s try doubling the number of epochs from 500 to 1000.
Diagnostic of 1000 Epochs
In this section, we use the same experimental setup and fit the model over 1000 training epochs.
Specifically, the n_epochs parameter is set to 1000 in the run() function.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
Running the example prints the RMSE for the train and test sets from the final epoch.
A line plot of the test and train RMSE scores each epoch is also created.
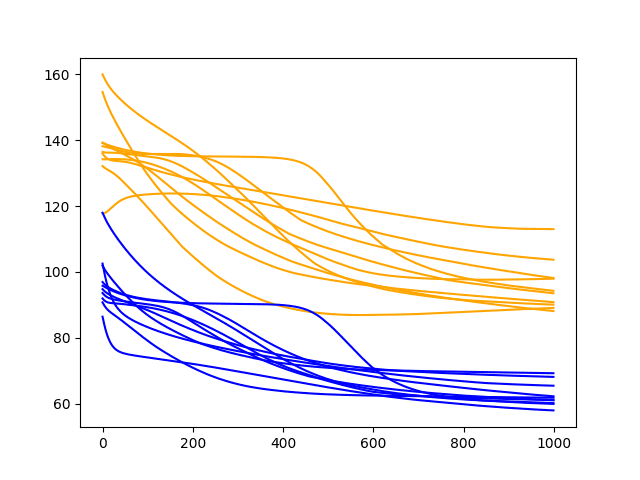
Diagnostic Results with 1000 Epochs
We can see that the downward trend of model error does continue and appears to slow.
The lines for the train and test cases become more horizontal, but still generally show a downward trend, although at a lower rate of change. Some examples of test error show a possible inflection point around 600 epochs and may show a rising trend.
It is worth extending the epochs further. We are interested in the average performance continuing to improve on the test set and this may continue.
Let’s try doubling the number of epochs from 1000 to 2000.
Diagnostic of 2000 Epochs
In this section, we use the same experimental setup and fit the model over 2000 training epochs.
Specifically, the n_epochs parameter is set to 2000 in the run() function.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
Running the example prints the RMSE for the train and test sets from the final epoch.
A line plot of the test and train RMSE scores each epoch is also created.
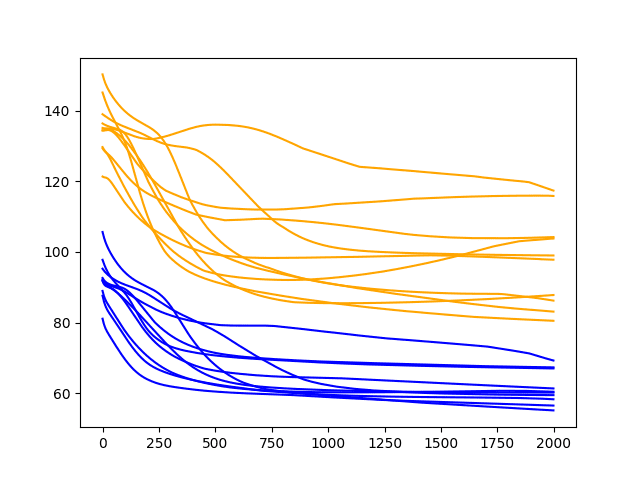
Diagnostic Results with 2000 Epochs
As one might have guessed, the downward trend in error continues over the additional 1000 epochs on both the train and test datasets.
Of note, about half of the cases continue to decrease in error all the way to the end of the run, whereas the rest show signs of an increasing trend.
The increasing trend is a sign of overfitting. This is when the model overfits the training dataset at the cost of worse performance on the test dataset. It is exemplified by continued improvements on the training dataset and improvements followed by an inflection point and worsting skill in the test dataset. A little less than half of the runs show the beginnings of this type of pattern on the test dataset.
Nevertheless, the final epoch results on the test dataset are very good. If there is a chance we can see further gains by even longer training, we must explore it.
Let’s try doubling the number of epochs from 2000 to 4000.
Diagnostic of 4000 Epochs
In this section, we use the same experimental setup and fit the model over 4000 training epochs.
Specifically, the n_epochs parameter is set to 4000 in the run() function.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
Running the example prints the RMSE for the train and test sets from the final epoch.
A line plot of the test and train RMSE scores each epoch is also created.
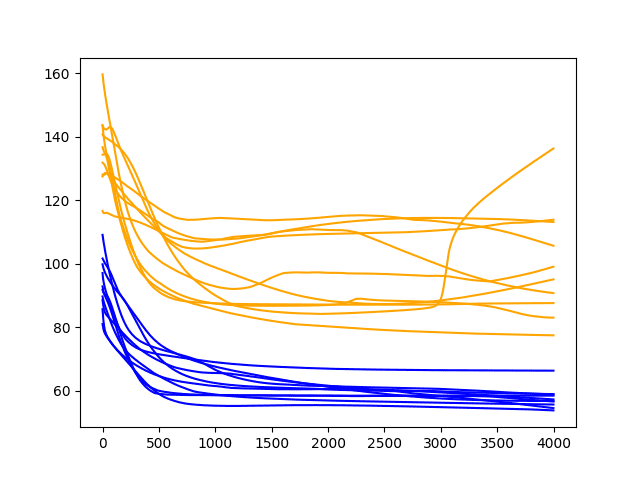
Diagnostic Results with 4000 Epochs
A similar pattern continues.
There is a general trend of improving performance, even over the 4000 epochs. There is one case of severe overfitting where test error rises sharply.
Again, most runs end with a “good” (better than persistence) final test error.
Summary of Results
The diagnostic runs above are helpful to explore the dynamical behavior of the model, but fall short of an objective and comparable mean performance.
We can address this by repeating the same experiments and calculating and comparing summary statistics for each configuration. In this case, 30 runs were completed of the epoch values 500, 1000, 2000, 4000, and 6000.
The idea is to compare the configurations using summary statistics over a larger number of runs and see exactly which of the configurations might perform better on average.
The complete code example is listed below.
Running the code first prints summary statistics for each of the 5 configurations. Notably, this includes the mean and standard deviations of the RMSE scores from each population of results.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
The mean gives an idea of the average expected performance of a configuration, whereas the standard deviation gives an idea of the variance. The min and max RMSE scores also give an idea of the range of possible best and worst case examples that might be expected.
Looking at just the mean RMSE scores, the results suggest that an epoch configured to 1000 may be better. The results also suggest further investigations may be warranted of epoch values between 1000 and 2000.
The distributions are also shown on a box and whisker plot. This is helpful to see how the distributions directly compare.
The green line shows the median and the box shows the 25th and 75th percentiles, or the middle 50% of the data. This comparison also shows that the choice of setting epochs to 1000 is better than the tested alternatives. It also shows that the best possible performance may be achieved with epochs of 2000 or 4000, at the cost of worse performance on average.
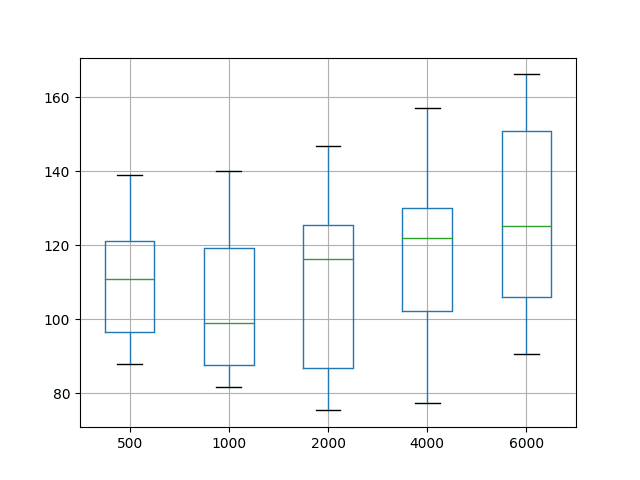
Box and Whisker Plot Summarizing Epoch Results
Next, we will look at the effect of batch size.
Tuning the Batch Size
Batch size controls how often to update the weights of the network.
Importantly in Keras, the batch size must be a factor of the size of the test and the training dataset.
In the previous section exploring the number of training epochs, the batch size was fixed at 4, which cleanly divides into the test dataset (with the size 12) and in a truncated version of the test dataset (with the size of 20).
In this section, we will explore the effect of varying the batch size. We will hold the number of training epochs constant at 1000.
Diagnostic of 1000 Epochs and Batch Size of 4
As a reminder, the previous section evaluated a batch size of 4 in the second experiment with a number of epochs of 1000.
The results showed a downward trend in error that continued for most runs all the way to the final training epoch.
Diagnostic Results with 1000 Epochs
Diagnostic of 1000 Epochs and Batch Size of 2
In this section, we look at halving the batch size from 4 to 2.
This change is made to the n_batch parameter in the run() function; for example:
Running the example shows the same general trend in performance as a batch size of 4, perhaps with a higher RMSE on the final epoch.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
The runs may show the behavior of stabilizing the RMES sooner rather than seeming to continue the downward trend.
The RSME scores from the final exposure of each run are listed below.
A line plot of the test and train RMSE scores each epoch is also created.
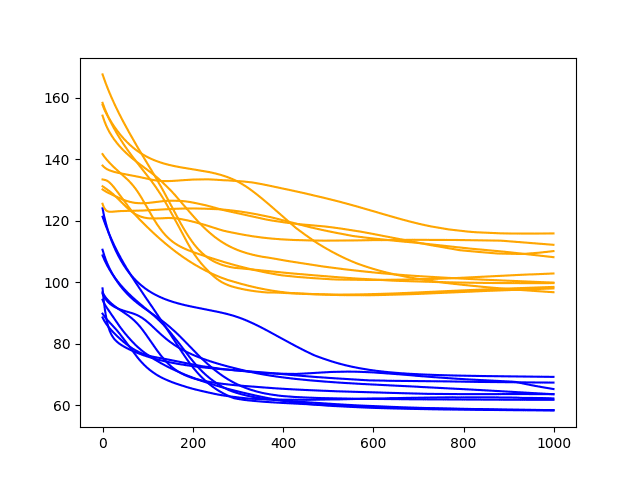
Diagnostic Results with 1000 Epochs and Batch Size of 2
Let’s try having the batch size again.
Diagnostic of 1000 Epochs and Batch Size of 1
A batch size of 1 is technically performing online learning.
That is where the network is updated after each training pattern. This can be contrasted with batch learning, where the weights are only updated at the end of each epoch.
We can change the n_batch parameter in the run() function; for example:
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
Again, running the example prints the RMSE scores from the final epoch of each run.
A line plot of the test and train RMSE scores each epoch is also created.
The plot suggests more variability in the test RMSE over time and perhaps a train RMSE that stabilizes sooner than with larger batch sizes. The increased variability in the test RMSE is to be expected given the large changes made to the network give so little feedback each update.
The graph also suggests that perhaps the decreasing trend in RMSE may continue if the configuration was afforded more training epochs.
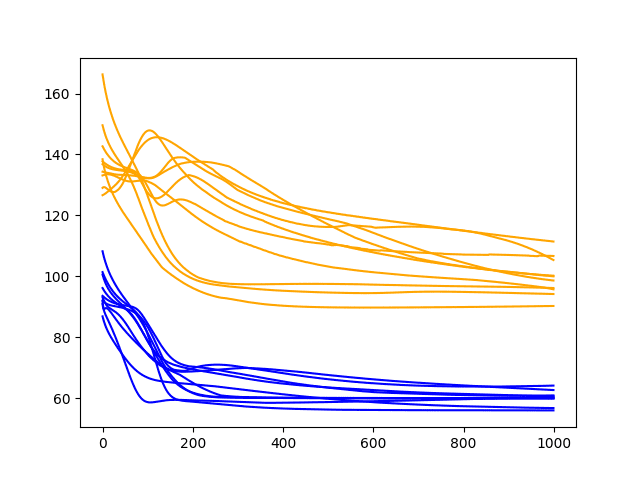
Diagnostic Results with 1000 Epochs and Batch Size of 1
Summary of Results
As with training epochs, we can objectively compare the performance of the network given different batch sizes.
Each configuration was run 30 times and summary statistics calculated on the final results.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
From the mean performance alone, the results suggest lower RMSE with a batch size of 1. As was noted in the previous section, this may be improved further with more training epochs.
A box and whisker plot of the data was also created to help graphically compare the distributions. The plot shows the median performance as a green line where a batch size of 4 shows both the largest variability and also the lowest median RMSE.
Tuning a neural network is a tradeoff of average performance and variability of that performance, with an ideal result having a low mean error with low variability, meaning that it is generally good and reproducible.
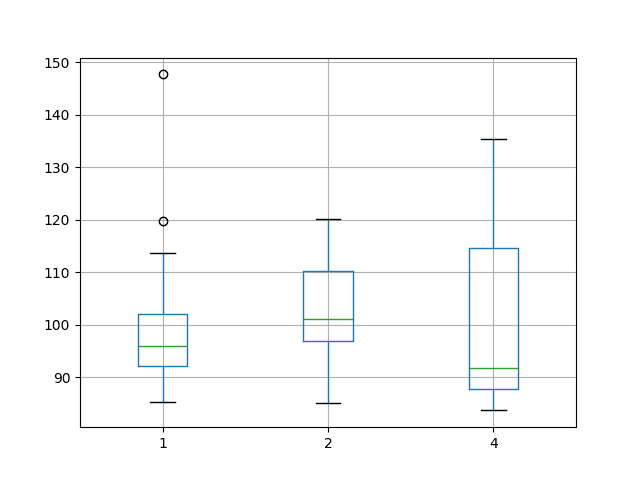
Box and Whisker Plot Summarizing Batch Size Results
Tuning the Number of Neurons
In this section, we will investigate the effect of varying the number of neurons in the network.
The number of neurons affects the learning capacity of the network. Generally, more neurons would be able to learn more structure from the problem at the cost of longer training time. More learning capacity also creates the problem of potentially overfitting the training data.
We will use a batch size of 4 and 1000 training epochs.
Diagnostic of 1000 Epochs and 1 Neuron
We will start with 1 neuron.
As a reminder, this is the second configuration tested from the epochs experiments.
Diagnostic Results with 1000 Epochs
Diagnostic of 1000 Epochs and 2 Neurons
We can increase the number of neurons from 1 to 2. This would be expected to improve the learning capacity of the network.
We can do this by changing the n_neurons variable in the run() function.
Running this configuration prints the RMSE scores from the final epoch of each run.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
The results suggest a good, but not great, general performance.
A line plot of the test and train RMSE scores each epoch is also created.
This is more telling. It shows a rapid decrease in test RMSE to about epoch 500-750 where an inflection point shows a rise in test RMSE almost across the board on all runs. Meanwhile, the training dataset shows a continued decrease to the final epoch.
These are good signs of overfitting of the training dataset.
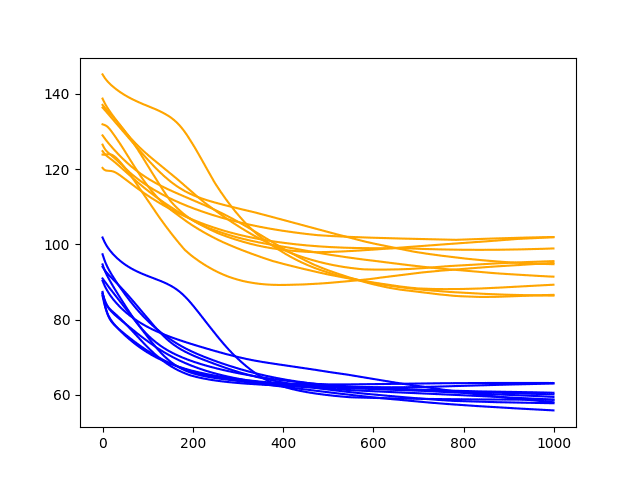
Diagnostic Results with 1000 Epochs and 2 Neurons
Let’s see if this trend continues with even more neurons.
Diagnostic of 1000 Epochs and 3 Neurons
This section looks at the same configuration with the number of neurons increased to 3.
We can do this by setting the n_neurons variable in the run() function.
Running this configuration prints the RMSE scores from the final epoch of each run.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
The results are similar to the previous section; we do not see much general difference between the final epoch test scores for 2 or 3 neurons. The final train scores do appear to be lower with 3 neurons, perhaps showing an acceleration of overfitting.
The inflection point in the training dataset seems to be happening sooner than the 2 neurons experiment, perhaps at epoch 300-400.
These increases in the number of neurons may benefit from additional changes to slowing down the rate of learning. Such as the use of regularization methods like dropout, decrease to the batch size, and decrease to the number of training epochs.
A line plot of the test and train RMSE scores each epoch is also created.
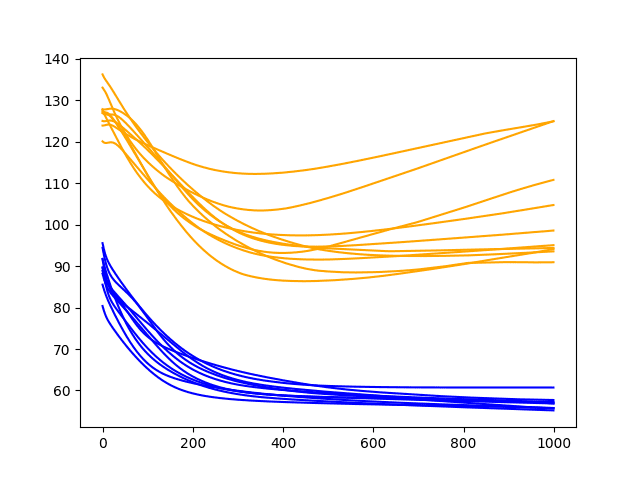
Diagnostic Results with 1000 Epochs and 3 Neurons
Summary of Results
Again, we can objectively compare the impact of increasing the number of neurons while keeping all other network configurations fixed.
In this section, we repeat each experiment 30 times and compare the average test RMSE performance with the number of neurons ranging from 1 to 5.
Running the experiment prints the summary statistics for each configuration.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
From the mean performance alone, the results suggest a network configuration with 1 neuron as having the best performance over 1000 epochs with a batch size of 4. This configuration also shows the tightest variance.
The box and whisker plot shows a clear trend in the median test set performance where the increase in neurons results in a corresponding increase in the test RMSE.
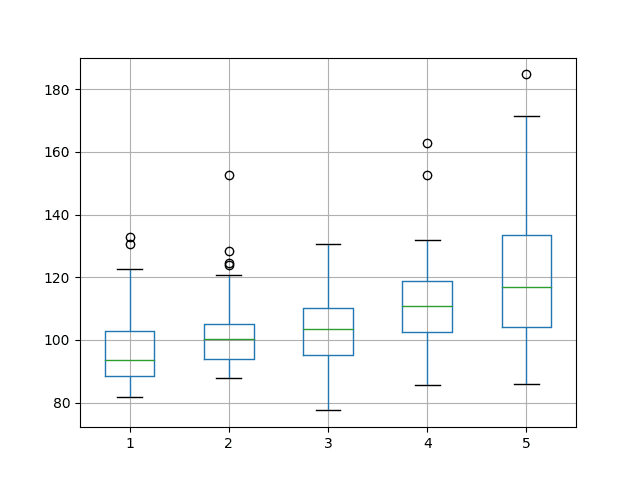
Box and Whisker Plot Summarizing Neuron Results
Summary of All Results
We completed quite a few LSTM experiments on the Shampoo Sales dataset in this tutorial.
Generally, it seems that a stateful LSTM configured with 1 neuron, a batch size of 4, and trained for 1000 epochs might be a good configuration.
The results also suggest that perhaps this configuration with a batch size of 1 and fit for more epochs may be worthy of further exploration.
Tuning neural networks is difficult empirical work, and LSTMs are proving to be no exception.
This tutorial demonstrated the benefit of both diagnostic studies of configuration behavior over time, as well as objective studies of test RMSE.
Nevertheless, there are always more studies that could be performed. Some ideas are listed in the next section.
Extensions
This section lists some ideas for extensions to the experiments performed in this tutorial.
If you explore any of these, report your results in the comments; I’d love to see what you come up with.
- Dropout. Slow down learning with regularization methods like dropout on the recurrent LSTM connections.
- Layers. Explore additional hierarchical learning capacity by adding more layers and varied numbers of neurons in each layer.
- Regularization. Explore how weight regularization, such as L1 and L2, can be used to slow down learning and overfitting of the network on some configurations.
- Optimization Algorithm. Explore the use of alternate optimization algorithms, such as classical gradient descent, to see if specific configurations to speed up or slow down learning can lead to benefits.
- Loss Function. Explore the use of alternative loss functions to see if these can be used to lift performance.
- Features and Timesteps. Explore the use of lag observations as input features and input time steps of the feature to see if their presence as input can improve learning and/or predictive capability of the model.
- Larger Batch Size. Explore larger batch sizes than 4, perhaps requiring further manipulation of the size of the training and test datasets.
Summary
In this tutorial, you discovered how you can systematically investigate the configuration for an LSTM network for time series forecasting.
Specifically, you learned:
- How to design a systematic test harness for evaluating model configurations.
- How to use model diagnostics over time, as well as objective prediction error to interpret model behavior.
- How to explore and interpret the effects of the number of training epochs, batch size, and number of neurons.
Do you have any questions about tuning LSTMs, or about this tutorial?
Ask your questions in the comments below and I will do my best to answer.





No comments:
Post a Comment