How Santhosh Sharma Went From
Working in the Loans Department of a Bank to
Getting Hired as a Senior Data Scientist at Target.
Santhosh Sharma recently reached out to me to share his inspirational story and I want to share it with you.
His story shows how with enthusiasm for machine learning, taking the initiative, sharing your results and a little luck can change your career and throw you deep into applied machine learning.
After reading this interview, you will know:
- How Santhosh demonstrated is growing machine learning skills publicly on Kaggle.
- The technical details of the methodical thing that Santhosh did and why it is note worthy.
- How he used his public recognition to help get hired as a Data Scientist.
Let’s dive in.
Do you have your own success story?
Share it in the comments.
How to Go From Working in a Bank to Senior Data Scientist at Target
Q. Please Share a Little Background?
I have an M.Tech. in Computer Science and Engineering specializing in Parallel and Distributed Computing from IIT Kanpur, India.
Q. How and Why Did You Get Interested in Machine Learning?
I was working in the loans department of a bank.
The bank had developed software which used machine learning to predict whether it would be a good bet to sanction a loan application or not.
The results of the software in many cases were better than some of the credit officers.
I was impressed by this technology and started developing an interest in machine learning since then.
Q. How has Machine Learning Mastery Helped You on Your Journey?
Machine Learning Mastery helped me master machine learning. Period.
I don’t have a background in mathematics and statistics.
I was under the wrong assumption that I needed one.
I struggled for close to 3 years to get a good hold on ML algorithms. Lots of time got wasted in learning unnecessary things from many books which were theoretical in nature.
Progress made using Machine Learning Mastery books helped improve my skills by leaps and bounds in a very short span of time.
Q. Share your Experiences on Kaggle?
Kaggle is a great platform for learning Machine Learning.
The datasets hosted represent real-world observations. Experts all across the world post solutions to these problems. Learning from these solutions helped accelerate my learning.
It made learning machine learning fun and enjoyable.
Q. What is a Kaggle Dataset That You Worked On?
I worked on the Allstate Claims Severity dataset.
I did a spot-check using the popular regression algorithms such as LR, Ridge, Lasso, Elastic Net, etc.
I used the seaborn library for EDA and the scikit-learn library for modeling.
Q. Well done on your top-voted Kernel, how did it come to be?
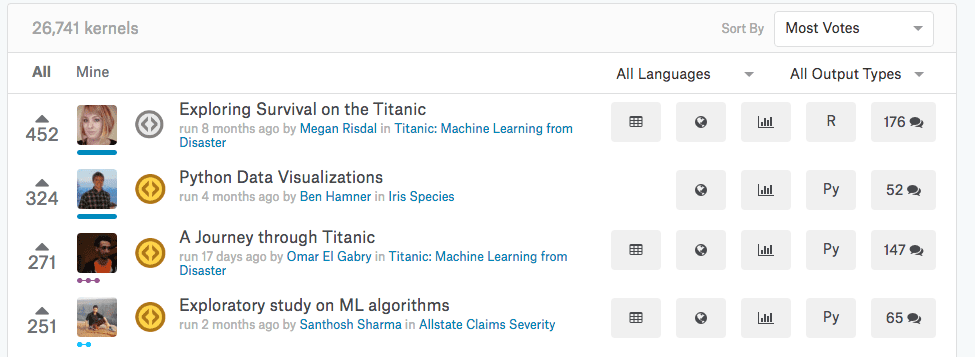
Santhosh Sharma Top Voted Kaggle Kernel
(currently the 4th most popular kernel by votes)
The approach followed is inspired by the recipes and the approach in ML Mastery Python books.
In the feedback received for this kernel, most of the users say that it is very easy to follow.
I am thankful to Machine Learning Mastery books which taught me how to approach a machine learning problem.
I have followed this in all of my kernels.
Q. Can You Walk Us Through The Steps In Your Popular Kernel?
The kernel can be accessed directly here.
The steps followed is in accordance with the approach mentioned in the Machine Learning Mastery books. The steps are mentioned below.
Santhosh Sharma Top Voted Kaggle Kernel
Data statistics
- Shape of the train and test dataset
- Peek – eyeball the data
- Description – min, max, avg, etc of each column
- Skew – of each numerical column to check if correction is necessary
Transformation
- Correction of skew – one of the columns needed correction – I used log transform
Data Interaction
- Correlation – I filtered out only highly correlated pairs
- Scatter plot – plotting using seaborn
Data Visualization
- Box and density plots – violin plot showed spectacular visualization
- Grouping of one hot encoded attributes – to show the count
Data Preparation
- One hot encoding of categorical data – many columns are categorical
- Test-train split – for model evaluation
Evaluation and analysis
- Linear Regression (Linear algo)
- Ridge Regression (Linear algo)
- LASSO Linear Regression (Linear algo)
- Elastic Net Regression (Linear algo)
- KNN (non-linear algo)
- CART (non-linear algo)
- SVM (Non-linear algo)
- Bagged Decision Trees (Bagging)
- Random Forest (Bagging)
- Extra Trees (Bagging)
- AdaBoost (Boosting)
- Stochastic Gradient Boosting (Boosting)
- MLP (Deep Learning)
- XGBoost
Prediction
- Using the best model (XGBRegressor)
- Surprising results : Simple linear models such as LR, Ridge, Lasso, and ElasticNet performed very well
Q. Congratulations On The New Job, How Did You Get It?
I showcased my top-voted kernel on Kaggle to the interviewer.
He was very impressed by the systematic approach and the results I got.
I will be working as a Senior Data Scientist with Target Corporation.
Q. Any Idea What You’ll Work on at Target?
I will be joining next week.
I’m looking forward to working with the team and make a small difference in the shopping experience of millions of customers of Target.
Q. What is Next?
I’m looking forward to the next book by Machine Learning Mastery on Time Series!
Summary
In this post, you discovered how a Santhosh went from working in a bank to getting a job as a Senior Data Scientist at Target.
You learned that:
- Santhosh applied the skills he learned to real datasets on a Kaggle problem.
- He shared his results publically, showing how others can do what he did and in turn gaining credibility with a top ranking Kaggle Kernel.
- The top voted Kernel helped Santhosh get a new job as a Data Scientist at Target.
So, what can you do?
- Are you practicing on real datasets?
- Are you sharing everything you’re learning publicly?
- Are you helping others?
What is your next step going to be?
Share it in the comments below.





No comments:
Post a Comment