Time series prediction problems are a difficult type of predictive modeling problem.
Unlike regression predictive modeling, time series also adds the complexity of a sequence dependence among the input variables.
A powerful type of neural network designed to handle sequence dependence is called a recurrent neural network.
The Long Short-Term Memory network or LSTM network is a type of
recurrent neural network used in deep learning because very large
architectures can be successfully trained.
In this post, you will discover how to develop LSTM networks in
Python using the Keras deep learning library to address a demonstration
time-series prediction problem.
After completing this tutorial, you will know how to implement and
develop LSTM networks for your own time series prediction problems and
other more general sequence problems. You will know:
- About the International Airline Passengers time-series prediction problem
- How to develop LSTM networks for regression, window, and time-step-based framing of time series prediction problems
- How to develop and make predictions using LSTM networks that maintain state (memory) across very long sequences
In this tutorial, we will develop a number of LSTMs for a standard
time series prediction problem. The problem and the chosen configuration
for the LSTM networks are for demonstration purposes only; they are not
optimized.
These examples will show exactly how you can develop your own
differently structured LSTM networks for time series predictive modeling
problems.
Problem Description
The problem you will look at in this post is the International Airline Passengers prediction problem.
This is a problem where, given a year and a month, the task is to
predict the number of international airline passengers in units of
1,000. The data ranges from January 1949 to December 1960, or 12 years,
with 144 observations.
Below is a sample of the first few lines of the file.
"Month","Passengers" "1949-01",112 "1949-02",118 "1949-03",132 "1949-04",129 "1949-05",121 |
You can load this dataset easily using the Pandas library. You
are not interested in the date, given that each observation is separated
by the same interval of one month. Therefore, when you load the
dataset, you can exclude the first column.
Once loaded, you can easily plot the whole dataset. The code to load and plot the dataset is listed below.
import pandas import matplotlib.pyplot as plt dataset = pandas.read_csv('airline-passengers.csv', usecols=[1], engine='python') plt.plot(dataset) plt.show() |
You can see an upward trend in the dataset over time.
You can also see some periodicity in the dataset that probably corresponds to the Northern Hemisphere vacation period.
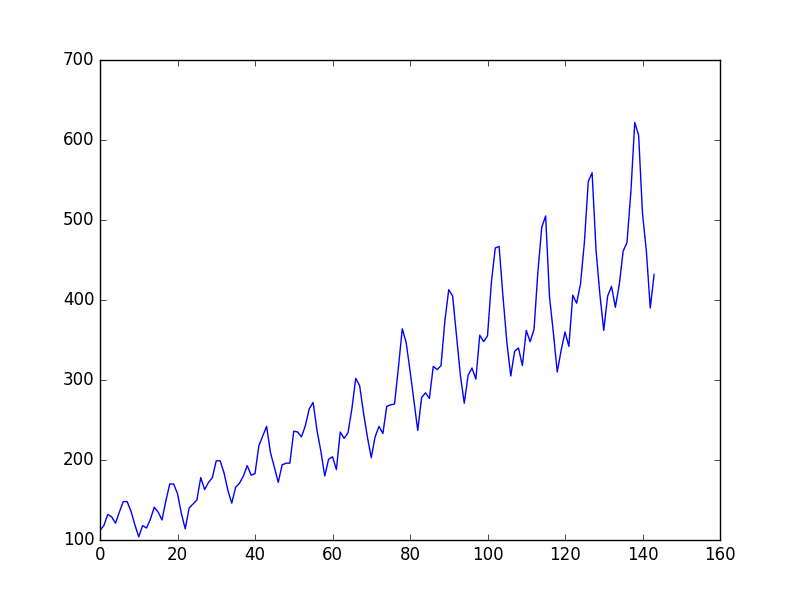
Plot of the airline passengers dataset
Let’s keep things simple and work with the data as-is.
Normally, it is a good idea to investigate various data preparation techniques to rescale the data and make it stationary.
Need help with Deep Learning for Time Series?
Take my free 7-day email crash course now (with sample code).
Click to sign-up and also get a free PDF Ebook version of the course.
Long Short-Term Memory Network
The Long Short-Term Memory network, or LSTM network, is a recurrent
neural network trained using Backpropagation Through Time that overcomes
the vanishing gradient problem.
As such, it can be used to create large recurrent networks that, in
turn, can be used to address difficult sequence problems in machine
learning and achieve state-of-the-art results.
Instead of neurons, LSTM networks have memory blocks connected through layers.
A block has components that make it smarter than a classical neuron
and a memory for recent sequences. A block contains gates that manage
the block’s state and output. A block operates upon an input sequence,
and each gate within a block uses the sigmoid activation units to
control whether it is triggered or not, making the change of state and
addition of information flowing through the block conditional.
There are three types of gates within a unit:
- Forget Gate: conditionally decides what information to throw away from the block
- Input Gate: conditionally decides which values from the input to update the memory state
- Output Gate: conditionally decides what to output based on input and the memory of the block
Each unit is like a mini-state machine where the gates of the units have weights that are learned during the training procedure.
You can see how you may achieve sophisticated learning and memory
from a layer of LSTMs, and it is not hard to imagine how higher-order
abstractions may be layered with multiple such layers.
LSTM Network for Regression
You can phrase the problem as a regression problem.
That is, given the number of passengers (in units of thousands) this month, what is the number of passengers next month?
You can write a simple function to convert the single column of data
into a two-column dataset: the first column containing this month’s (t)
passenger count and the second column containing next month’s (t+1)
passenger count to be predicted.
Before you start, let’s first import all the functions and classes
you will use. This assumes a working SciPy environment with the Keras
deep learning library installed.
import numpy as np import matplotlib.pyplot as plt import pandas as pd import tensorflow as tf from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dense from tensorflow.keras.layers import LSTM from sklearn.preprocessing import MinMaxScaler from sklearn.metrics import mean_squared_error |
Before you do anything, it is a good idea to fix the random number seed to ensure your results are reproducible.
# fix random seed for reproducibility tf.random.set_seed(7) |
You can also use the code from the previous section to load the
dataset as a Pandas dataframe. You can then extract the NumPy array
from the dataframe and convert the integer values to floating point
values, which are more suitable for modeling with a neural network.
# load the dataset dataframe = pd.read_csv('airline-passengers.csv', usecols=[1], engine='python') dataset = dataframe.values dataset = dataset.astype('float32') |
LSTMs are sensitive to the scale of the input data,
specifically when the sigmoid (default) or tanh activation functions are
used. It can be a good practice to rescale the data to the range of
0-to-1, also called normalizing. You can easily normalize the dataset
using the MinMaxScaler preprocessing class from the scikit-learn library.
# normalize the dataset scaler = MinMaxScaler(feature_range=(0, 1)) dataset = scaler.fit_transform(dataset) |
After you model the data and estimate the skill of your model
on the training dataset, you need to get an idea of the skill of the
model on new unseen data. For a normal classification or regression
problem, you would do this using cross validation.
With time series data, the sequence of values is important. A simple
method that you can use is to split the ordered dataset into train and
test datasets. The code below calculates the index of the split point
and separates the data into the training datasets, with 67% of the
observations used to train the model, leaving the remaining 33% for
testing the model.
# split into train and test sets train_size = int(len(dataset) * 0.67) test_size = len(dataset) - train_size train, test = dataset[0:train_size,:], dataset[train_size:len(dataset),:] print(len(train), len(test)) |
Now, you can define a function to create a new dataset, as described above.
The function takes two arguments: the dataset, which is a NumPy array you want to convert into a dataset, and the look_back,
which is the number of previous time steps to use as input variables to
predict the next time period—in this case, defaulted to 1.
This default will create a dataset where X is the number of
passengers at a given time (t), and Y is the number of passengers at the
next time (t + 1).
It can be configured by constructing a differently shaped dataset in the next section.
# convert an array of values into a dataset matrix def create_dataset(dataset, look_back=1): dataX, dataY = [], [] for i in range(len(dataset)-look_back-1): a = dataset[i:(i+look_back), 0] dataX.append(a) dataY.append(dataset[i + look_back, 0]) return np.array(dataX), np.array(dataY) |
Let’s take a look at the effect of this function on the first rows of the dataset (shown in the unnormalized form for clarity).
X Y 112 118 118 132 132 129 129 121 121 135 |
If you compare these first five
rows to the original dataset sample listed in the previous section, you
can see the X=t and Y=t+1 pattern in the numbers.
Let’s use this function to prepare the train and test datasets for modeling.
# reshape into X=t and Y=t+1 look_back = 1 trainX, trainY = create_dataset(train, look_back) testX, testY = create_dataset(test, look_back) |
The LSTM network expects the input data (X) to be provided with a specific array structure in the form of [samples, time steps, features].
Currently, the data is in the form of [samples, features],
and you are framing the problem as one time step for each sample. You
can transform the prepared train and test input data into the expected
structure using numpy.reshape() as follows:
# reshape input to be [samples, time steps, features] trainX = np.reshape(trainX, (trainX.shape[0], 1, trainX.shape[1])) testX = np.reshape(testX, (testX.shape[0], 1, testX.shape[1])) |
You are now ready to design and fit your LSTM network for this problem.
The network has a visible layer with 1 input, a hidden layer with 4
LSTM blocks or neurons, and an output layer that makes a single value
prediction. The default sigmoid activation function is used for the LSTM
blocks. The network is trained for 100 epochs, and a batch size of 1 is
used.
# create and fit the LSTM network model = Sequential() model.add(LSTM(4, input_shape=(1, look_back))) model.add(Dense(1)) model.compile(loss='mean_squared_error', optimizer='adam') model.fit(trainX, trainY, epochs=100, batch_size=1, verbose=2) |
Once the model is fit, you can estimate the performance of the
model on the train and test datasets. This will give you a point of
comparison for new models.
Note that you will invert the predictions before calculating error
scores to ensure that performance is reported in the same units as the
original data (thousands of passengers per month).
# make predictions trainPredict = model.predict(trainX) testPredict = model.predict(testX) # invert predictions trainPredict = scaler.inverse_transform(trainPredict) trainY = scaler.inverse_transform([trainY]) testPredict = scaler.inverse_transform(testPredict) testY = scaler.inverse_transform([testY]) # calculate root mean squared error trainScore = np.sqrt(mean_squared_error(trainY[0], trainPredict[:,0])) print('Train Score: %.2f RMSE' % (trainScore)) testScore = np.sqrt(mean_squared_error(testY[0], testPredict[:,0])) print('Test Score: %.2f RMSE' % (testScore)) |
Finally, you can generate predictions using the model for both
the train and test dataset to get a visual indication of the skill of
the model.
Because of how the dataset was prepared, you must shift the
predictions so that they align on the x-axis with the original dataset.
Once prepared, the data is plotted, showing the original dataset in
blue, the predictions for the training dataset in green, and the
predictions on the unseen test dataset in red.
# shift train predictions for plotting trainPredictPlot = np.empty_like(dataset) trainPredictPlot[:, :] = np.nan trainPredictPlot[look_back:len(trainPredict)+look_back, :] = trainPredict # shift test predictions for plotting testPredictPlot = np.empty_like(dataset) testPredictPlot[:, :] = np.nan testPredictPlot[len(trainPredict)+(look_back*2)+1:len(dataset)-1, :] = testPredict # plot baseline and predictions plt.plot(scaler.inverse_transform(dataset)) plt.plot(trainPredictPlot) plt.plot(testPredictPlot) plt.show() |
You can see that the model did an excellent job of fitting both the training and the test datasets.
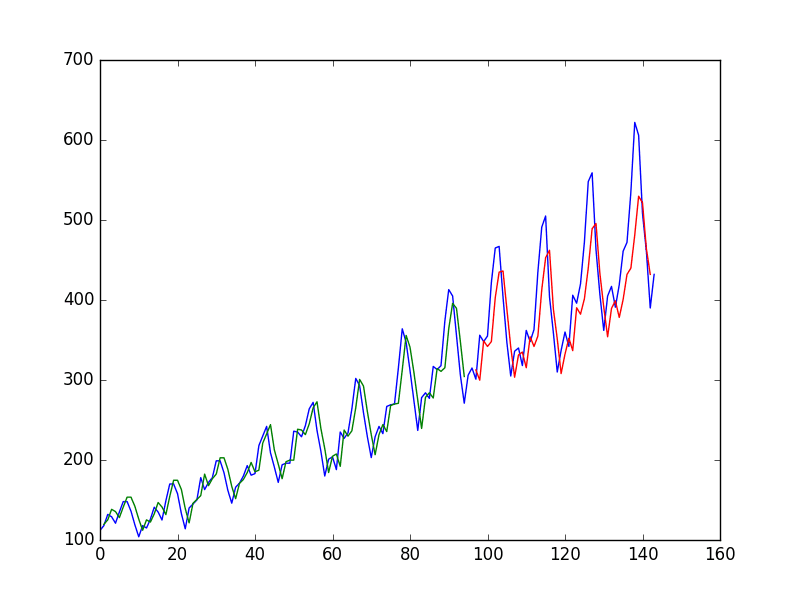
LSTM trained on regression formulation of passenger prediction problem
For completeness, below is the entire code example.
# LSTM for international airline passengers problem with regression framing import numpy as np import matplotlib.pyplot as plt from pandas import read_csv import math import tensorflow as tf from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dense from tensorflow.keras.layers import LSTM from sklearn.preprocessing import MinMaxScaler from sklearn.metrics import mean_squared_error # convert an array of values into a dataset matrix def create_dataset(dataset, look_back=1): dataX, dataY = [], [] for i in range(len(dataset)-look_back-1): a = dataset[i:(i+look_back), 0] dataX.append(a) dataY.append(dataset[i + look_back, 0]) return np.array(dataX), np.array(dataY) # fix random seed for reproducibility tf.random.set_seed(7) # load the dataset dataframe = read_csv('airline-passengers.csv', usecols=[1], engine='python') dataset = dataframe.values dataset = dataset.astype('float32') # normalize the dataset scaler = MinMaxScaler(feature_range=(0, 1)) dataset = scaler.fit_transform(dataset) # split into train and test sets train_size = int(len(dataset) * 0.67) test_size = len(dataset) - train_size train, test = dataset[0:train_size,:], dataset[train_size:len(dataset),:] # reshape into X=t and Y=t+1 look_back = 1 trainX, trainY = create_dataset(train, look_back) testX, testY = create_dataset(test, look_back) # reshape input to be [samples, time steps, features] trainX = np.reshape(trainX, (trainX.shape[0], 1, trainX.shape[1])) testX = np.reshape(testX, (testX.shape[0], 1, testX.shape[1])) # create and fit the LSTM network model = Sequential() model.add(LSTM(4, input_shape=(1, look_back))) model.add(Dense(1)) model.compile(loss='mean_squared_error', optimizer='adam') model.fit(trainX, trainY, epochs=100, batch_size=1, verbose=2) # make predictions trainPredict = model.predict(trainX) testPredict = model.predict(testX) # invert predictions trainPredict = scaler.inverse_transform(trainPredict) trainY = scaler.inverse_transform([trainY]) testPredict = scaler.inverse_transform(testPredict) testY = scaler.inverse_transform([testY]) # calculate root mean squared error trainScore = np.sqrt(mean_squared_error(trainY[0], trainPredict[:,0])) print('Train Score: %.2f RMSE' % (trainScore)) testScore = np.sqrt(mean_squared_error(testY[0], testPredict[:,0])) print('Test Score: %.2f RMSE' % (testScore)) # shift train predictions for plotting trainPredictPlot = np.empty_like(dataset) trainPredictPlot[:, :] = np.nan trainPredictPlot[look_back:len(trainPredict)+look_back, :] = trainPredict # shift test predictions for plotting testPredictPlot = np.empty_like(dataset) testPredictPlot[:, :] = np.nan testPredictPlot[len(trainPredict)+(look_back*2)+1:len(dataset)-1, :] = testPredict # plot baseline and predictions plt.plot(scaler.inverse_transform(dataset)) plt.plot(trainPredictPlot) plt.plot(testPredictPlot) plt.show() |
Note: Your results may vary
given the stochastic nature of the algorithm or evaluation procedure,
or differences in numerical precision. Consider running the example a
few times and compare the average outcome.
Running the example produces the following output.
... Epoch 95/100 94/94 - 0s - loss: 0.0021 - 37ms/epoch - 391us/step Epoch 96/100 94/94 - 0s - loss: 0.0020 - 37ms/epoch - 398us/step Epoch 97/100 94/94 - 0s - loss: 0.0020 - 37ms/epoch - 396us/step Epoch 98/100 94/94 - 0s - loss: 0.0020 - 37ms/epoch - 391us/step Epoch 99/100 94/94 - 0s - loss: 0.0020 - 37ms/epoch - 394us/step Epoch 100/100 94/94 - 0s - loss: 0.0020 - 36ms/epoch - 382us/step 3/3 [==============================] - 0s 490us/step 2/2 [==============================] - 0s 461us/step Train Score: 22.68 RMSE Test Score: 49.34 RMSE |
You can see that the model has an average error of about 23
passengers (in thousands) on the training dataset and about 49
passengers (in thousands) on the test dataset. Not that bad.
LSTM for Regression Using the Window Method
You can also phrase the problem so that multiple, recent time steps can be used to make the prediction for the next time step.
This is called a window, and the size of the window is a parameter that can be tuned for each problem.
For example, given the current time (t) to predict the value at the
next time in the sequence (t+1), you can use the current time (t), as
well as the two prior times (t-1 and t-2) as input variables.
When phrased as a regression problem, the input variables are t-2, t-1, and t, and the output variable is t+1.
The create_dataset() function created in the previous section allows you to create this formulation of the time series problem by increasing the look_back argument from 1 to 3.
A sample of the dataset with this formulation is as follows:
X1 X2 X3 Y 112 118 132 129 118 132 129 121 132 129 121 135 129 121 135 148 121 135 148 148 |
You can re-run the example in the previous section with the
larger window size. The whole code listing with just the window size
change is listed below for completeness.
# LSTM for international airline passengers problem with window regression framing import numpy as np import matplotlib.pyplot as plt import tensorflow as tf from pandas import read_csv from keras.models import Sequential from keras.layers import Dense from keras.layers import LSTM from sklearn.preprocessing import MinMaxScaler from sklearn.metrics import mean_squared_error # convert an array of values into a dataset matrix def create_dataset(dataset, look_back=1): dataX, dataY = [], [] for i in range(len(dataset)-look_back-1): a = dataset[i:(i+look_back), 0] dataX.append(a) dataY.append(dataset[i + look_back, 0]) return np.array(dataX), np.array(dataY) # fix random seed for reproducibility tf.random.set_seed(7) # load the dataset dataframe = read_csv('airline-passengers.csv', usecols=[1], engine='python') dataset = dataframe.values dataset = dataset.astype('float32') # normalize the dataset scaler = MinMaxScaler(feature_range=(0, 1)) dataset = scaler.fit_transform(dataset) # split into train and test sets train_size = int(len(dataset) * 0.67) test_size = len(dataset) - train_size train, test = dataset[0:train_size,:], dataset[train_size:len(dataset),:] # reshape into X=t and Y=t+1 look_back = 3 trainX, trainY = create_dataset(train, look_back) testX, testY = create_dataset(test, look_back) # reshape input to be [samples, time steps, features] trainX = np.reshape(trainX, (trainX.shape[0], 1, trainX.shape[1])) testX = np.reshape(testX, (testX.shape[0], 1, testX.shape[1])) # create and fit the LSTM network model = Sequential() model.add(LSTM(4, input_shape=(1, look_back))) model.add(Dense(1)) model.compile(loss='mean_squared_error', optimizer='adam') model.fit(trainX, trainY, epochs=100, batch_size=1, verbose=2) # make predictions trainPredict = model.predict(trainX) testPredict = model.predict(testX) # invert predictions trainPredict = scaler.inverse_transform(trainPredict) trainY = scaler.inverse_transform([trainY]) testPredict = scaler.inverse_transform(testPredict) testY = scaler.inverse_transform([testY]) # calculate root mean squared error trainScore = np.sqrt(mean_squared_error(trainY[0], trainPredict[:,0])) print('Train Score: %.2f RMSE' % (trainScore)) testScore = np.sqrt(mean_squared_error(testY[0], testPredict[:,0])) print('Test Score: %.2f RMSE' % (testScore)) # shift train predictions for plotting trainPredictPlot = np.empty_like(dataset) trainPredictPlot[:, :] = np.nan trainPredictPlot[look_back:len(trainPredict)+look_back, :] = trainPredict # shift test predictions for plotting testPredictPlot = np.empty_like(dataset) testPredictPlot[:, :] = np.nan testPredictPlot[len(trainPredict)+(look_back*2)+1:len(dataset)-1, :] = testPredict # plot baseline and predictions plt.plot(scaler.inverse_transform(dataset)) plt.plot(trainPredictPlot) plt.plot(testPredictPlot) plt.show() |
Note: Your results may vary
given the stochastic nature of the algorithm or evaluation procedure,
or differences in numerical precision. Consider running the example a
few times and compare the average outcome.
Running the example provides the following output:
Epoch 95/100 92/92 - 0s - loss: 0.0023 - 35ms/epoch - 384us/step Epoch 96/100 92/92 - 0s - loss: 0.0023 - 36ms/epoch - 389us/step Epoch 97/100 92/92 - 0s - loss: 0.0024 - 37ms/epoch - 404us/step Epoch 98/100 92/92 - 0s - loss: 0.0023 - 36ms/epoch - 392us/step Epoch 99/100 92/92 - 0s - loss: 0.0022 - 36ms/epoch - 389us/step Epoch 100/100 92/92 - 0s - loss: 0.0022 - 35ms/epoch - 384us/step 3/3 [==============================] - 0s 514us/step 2/2 [==============================] - 0s 533us/step Train Score: 24.86 RMSE Test Score: 70.48 RMSE |
You can see that the error was increased slightly compared to
that of the previous section. The window size and the network
architecture were not tuned: This is just a demonstration of how to
frame a prediction problem.
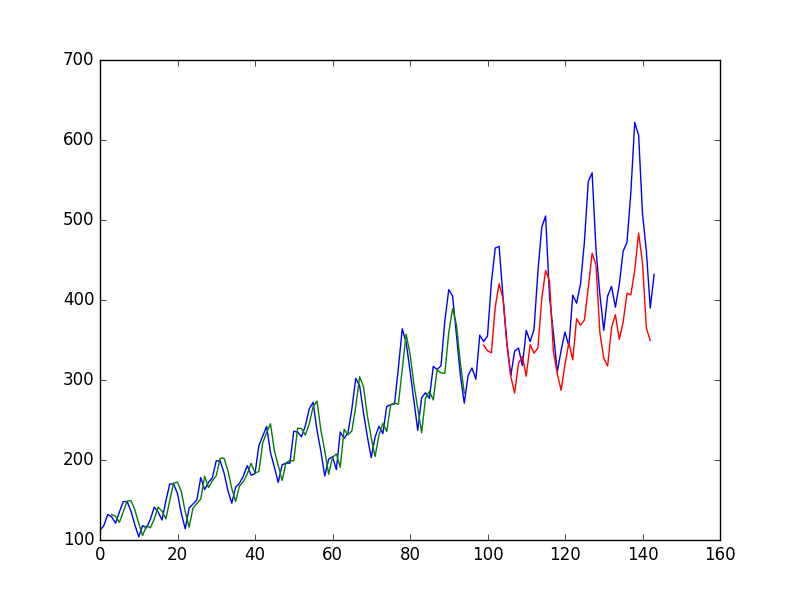
LSTM trained on window method formulation of passenger prediction problem
LSTM for Regression with Time Steps
You may have noticed that the data preparation for the LSTM network includes time steps.
Some sequence problems may have a varied number of time steps per
sample. For example, you may have measurements of a physical machine
leading up to the point of failure or a point of surge. Each incident
would be a sample of observations that lead up to the event, which would
be the time steps, and the variables observed would be the features.
Time steps provide another way to phrase your time series problem.
Like above in the window example, you can take prior time steps in your
time series as inputs to predict the output at the next time step.
Instead of phrasing the past observations as separate input features,
you can use them as time steps of the one input feature, which is
indeed a more accurate framing of the problem.
You can do this using the same data representation as in the previous
window-based example, except when you reshape the data, you set the
columns to be the time steps dimension and change the features dimension
back to 1. For example:
# reshape input to be [samples, time steps, features] trainX = np.reshape(trainX, (trainX.shape[0], trainX.shape[1], 1)) testX = np.reshape(testX, (testX.shape[0], testX.shape[1], 1)) |
The entire code listing is provided below for completeness.
# LSTM for international airline passengers problem with time step regression framing import numpy as np import matplotlib.pyplot as plt from pandas import read_csv import tensorflow as tf from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dense from tensorflow.keras.layers import LSTM from sklearn.preprocessing import MinMaxScaler from sklearn.metrics import mean_squared_error # convert an array of values into a dataset matrix def create_dataset(dataset, look_back=1): dataX, dataY = [], [] for i in range(len(dataset)-look_back-1): a = dataset[i:(i+look_back), 0] dataX.append(a) dataY.append(dataset[i + look_back, 0]) return np.array(dataX), np.array(dataY) # fix random seed for reproducibility tf.random.set_seed(7) # load the dataset dataframe = read_csv('airline-passengers.csv', usecols=[1], engine='python') dataset = dataframe.values dataset = dataset.astype('float32') # normalize the dataset scaler = MinMaxScaler(feature_range=(0, 1)) dataset = scaler.fit_transform(dataset) # split into train and test sets train_size = int(len(dataset) * 0.67) test_size = len(dataset) - train_size train, test = dataset[0:train_size,:], dataset[train_size:len(dataset),:] # reshape into X=t and Y=t+1 look_back = 3 trainX, trainY = create_dataset(train, look_back) testX, testY = create_dataset(test, look_back) # reshape input to be [samples, time steps, features] trainX = np.reshape(trainX, (trainX.shape[0], trainX.shape[1], 1)) testX = np.reshape(testX, (testX.shape[0], testX.shape[1], 1)) # create and fit the LSTM network model = Sequential() model.add(LSTM(4, input_shape=(look_back, 1))) model.add(Dense(1)) model.compile(loss='mean_squared_error', optimizer='adam') model.fit(trainX, trainY, epochs=100, batch_size=1, verbose=2) # make predictions trainPredict = model.predict(trainX) testPredict = model.predict(testX) # invert predictions trainPredict = scaler.inverse_transform(trainPredict) trainY = scaler.inverse_transform([trainY]) testPredict = scaler.inverse_transform(testPredict) testY = scaler.inverse_transform([testY]) # calculate root mean squared error trainScore = np.sqrt(mean_squared_error(trainY[0], trainPredict[:,0])) print('Train Score: %.2f RMSE' % (trainScore)) testScore = np.sqrt(mean_squared_error(testY[0], testPredict[:,0])) print('Test Score: %.2f RMSE' % (testScore)) # shift train predictions for plotting trainPredictPlot = np.empty_like(dataset) trainPredictPlot[:, :] = np.nan trainPredictPlot[look_back:len(trainPredict)+look_back, :] = trainPredict # shift test predictions for plotting testPredictPlot = np.empty_like(dataset) testPredictPlot[:, :] = np.nan testPredictPlot[len(trainPredict)+(look_back*2)+1:len(dataset)-1, :] = testPredict # plot baseline and predictions plt.plot(scaler.inverse_transform(dataset)) plt.plot(trainPredictPlot) plt.plot(testPredictPlot) plt.show() |
Note: Your results may vary
given the stochastic nature of the algorithm or evaluation procedure,
or differences in numerical precision. Consider running the example a
few times and compare the average outcome.
Running the example provides the following output:
... Epoch 95/100 92/92 - 0s - loss: 0.0023 - 45ms/epoch - 484us/step Epoch 96/100 92/92 - 0s - loss: 0.0023 - 45ms/epoch - 486us/step Epoch 97/100 92/92 - 0s - loss: 0.0024 - 44ms/epoch - 479us/step Epoch 98/100 92/92 - 0s - loss: 0.0022 - 45ms/epoch - 489us/step Epoch 99/100 92/92 - 0s - loss: 0.0022 - 45ms/epoch - 485us/step Epoch 100/100 92/92 - 0s - loss: 0.0021 - 45ms/epoch - 490us/step 3/3 [==============================] - 0s 635us/step 2/2 [==============================] - 0s 616us/step Train Score: 24.84 RMSE Test Score: 60.98 RMSE |
You can see that the results are slightly better than the
previous example, although the structure of the input data makes a lot
more sense.
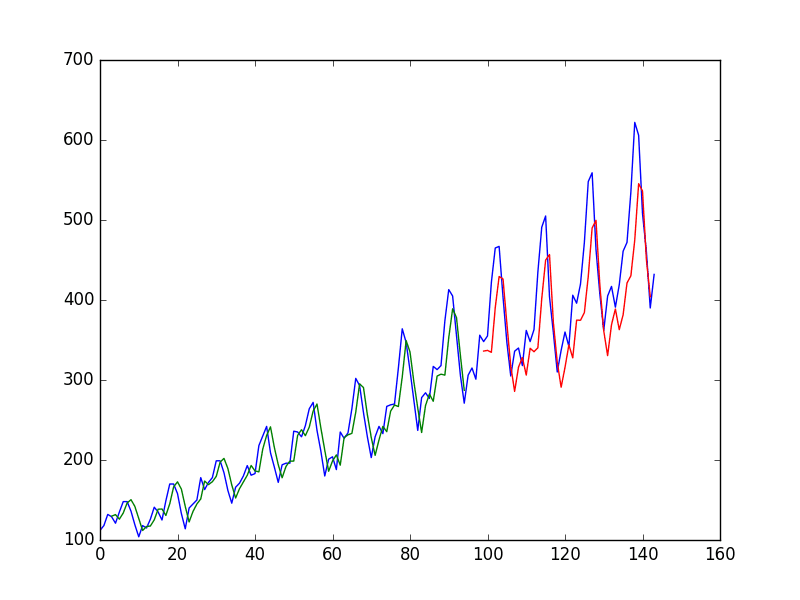
LSTM trained on time step formulation of passenger prediction problem
LSTM with Memory Between Batches
The LSTM network has memory capable of remembering across long sequences.
Normally, the state within the network is reset after each training batch when fitting the model, as well as each call to model.predict() or model.evaluate().
You can gain finer control over when the internal state of the LSTM
network is cleared in Keras by making the LSTM layer “stateful.” This
means it can build a state over the entire training sequence and even
maintain that state if needed to make predictions.
It requires that the training data not be shuffled when fitting the
network. It also requires explicit resetting of the network state after
each exposure to the training data (epoch) by calls to model.reset_states(). This means that you must create your own outer loop of epochs and within each epoch call model.fit() and model.reset_states(). For example:
for i in range(100): model.fit(trainX, trainY, epochs=1, batch_size=batch_size, verbose=2, shuffle=False) model.reset_states() |
Finally, when the LSTM layer is constructed, the stateful parameter must be set to True. Instead
of specifying the input dimensions, you must hard code the number of
samples in a batch, the number of time steps in a sample, and the number
of features in a time step by setting the batch_input_shape parameter. For example:
model.add(LSTM(4, batch_input_shape=(batch_size, time_steps, features), stateful=True)) |
This same batch size must then be used later when evaluating the model and making predictions. For example:
model.predict(trainX, batch_size=batch_size) |
You can adapt the previous time step example to use a stateful LSTM. The full code listing is provided below.
# LSTM for international airline passengers problem with memory import numpy as np import matplotlib.pyplot as plt from pandas import read_csv import tensorflow as tf from keras.models import Sequential from keras.layers import Dense from keras.layers import LSTM from sklearn.preprocessing import MinMaxScaler from sklearn.metrics import mean_squared_error # convert an array of values into a dataset matrix def create_dataset(dataset, look_back=1): dataX, dataY = [], [] for i in range(len(dataset)-look_back-1): a = dataset[i:(i+look_back), 0] dataX.append(a) dataY.append(dataset[i + look_back, 0]) return np.array(dataX), np.array(dataY) # fix random seed for reproducibility tf.random.set_seed(7) # load the dataset dataframe = read_csv('airline-passengers.csv', usecols=[1], engine='python') dataset = dataframe.values dataset = dataset.astype('float32') # normalize the dataset scaler = MinMaxScaler(feature_range=(0, 1)) dataset = scaler.fit_transform(dataset) # split into train and test sets train_size = int(len(dataset) * 0.67) test_size = len(dataset) - train_size train, test = dataset[0:train_size,:], dataset[train_size:len(dataset),:] # reshape into X=t and Y=t+1 look_back = 3 trainX, trainY = create_dataset(train, look_back) testX, testY = create_dataset(test, look_back) # reshape input to be [samples, time steps, features] trainX = np.reshape(trainX, (trainX.shape[0], trainX.shape[1], 1)) testX = np.reshape(testX, (testX.shape[0], testX.shape[1], 1)) # create and fit the LSTM network batch_size = 1 model = Sequential() model.add(LSTM(4, batch_input_shape=(batch_size, look_back, 1), stateful=True)) model.add(Dense(1)) model.compile(loss='mean_squared_error', optimizer='adam') for i in range(100): model.fit(trainX, trainY, epochs=1, batch_size=batch_size, verbose=2, shuffle=False) model.reset_states() # make predictions trainPredict = model.predict(trainX, batch_size=batch_size) model.reset_states() testPredict = model.predict(testX, batch_size=batch_size) # invert predictions trainPredict = scaler.inverse_transform(trainPredict) trainY = scaler.inverse_transform([trainY]) testPredict = scaler.inverse_transform(testPredict) testY = scaler.inverse_transform([testY]) # calculate root mean squared error trainScore = np.sqrt(mean_squared_error(trainY[0], trainPredict[:,0])) print('Train Score: %.2f RMSE' % (trainScore)) testScore = np.sqrt(mean_squared_error(testY[0], testPredict[:,0])) print('Test Score: %.2f RMSE' % (testScore)) # shift train predictions for plotting trainPredictPlot = np.empty_like(dataset) trainPredictPlot[:, :] = np.nan trainPredictPlot[look_back:len(trainPredict)+look_back, :] = trainPredict # shift test predictions for plotting testPredictPlot = np.empty_like(dataset) testPredictPlot[:, :] = np.nan testPredictPlot[len(trainPredict)+(look_back*2)+1:len(dataset)-1, :] = testPredict # plot baseline and predictions plt.plot(scaler.inverse_transform(dataset)) plt.plot(trainPredictPlot) plt.plot(testPredictPlot) plt.show() |
Note: Your results may vary
given the stochastic nature of the algorithm or evaluation procedure,
or differences in numerical precision. Consider running the example a
few times and compare the average outcome.
Running the example provides the following output:
... 92/92 - 0s - loss: 0.0024 - 46ms/epoch - 502us/step 92/92 - 0s - loss: 0.0023 - 49ms/epoch - 538us/step 92/92 - 0s - loss: 0.0023 - 47ms/epoch - 514us/step 92/92 - 0s - loss: 0.0023 - 48ms/epoch - 526us/step 92/92 - 0s - loss: 0.0022 - 48ms/epoch - 517us/step 92/92 - 0s - loss: 0.0022 - 48ms/epoch - 521us/step 92/92 - 0s - loss: 0.0022 - 47ms/epoch - 512us/step 92/92 - 0s - loss: 0.0021 - 50ms/epoch - 540us/step 92/92 - 0s - loss: 0.0021 - 47ms/epoch - 512us/step 92/92 - 0s - loss: 0.0021 - 52ms/epoch - 565us/step 92/92 [==============================] - 0s 448us/step 44/44 [==============================] - 0s 383us/step Train Score: 24.48 RMSE Test Score: 49.55 RMSE |
You do see that results are better than some, worse than
others. The model may need more modules and may need to be trained for
more epochs to internalize the structure of the problem.
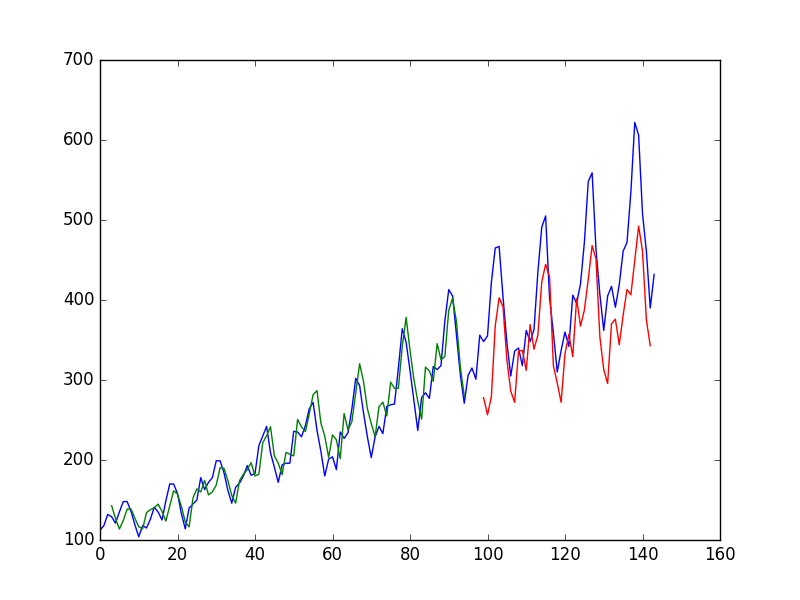
Stateful LSTM trained on regression formulation of passenger prediction problem
Stacked LSTMs with Memory Between Batches
Finally, let’s take a look at one of the big benefits of LSTMs: the
fact that they can be successfully trained when stacked into deep
network architectures.
LSTM networks can be stacked in Keras in the same way that other
layer types can be stacked. One addition to the configuration that is
required is that an LSTM layer prior to each subsequent LSTM layer must
return the sequence. This can be done by setting the return_sequences parameter on the layer to True.
You can extend the stateful LSTM in the previous section to have two layers, as follows:
model.add(LSTM(4, batch_input_shape=(batch_size, look_back, 1), stateful=True, return_sequences=True)) model.add(LSTM(4, batch_input_shape=(batch_size, look_back, 1), stateful=True)) |
The entire code listing is provided below for completeness.
# Stacked LSTM for international airline passengers problem with memory import numpy as np import matplotlib.pyplot as plt from pandas import read_csv import tensorflow as tf from keras.models import Sequential from keras.layers import Dense from keras.layers import LSTM from sklearn.preprocessing import MinMaxScaler from sklearn.metrics import mean_squared_error # convert an array of values into a dataset matrix def create_dataset(dataset, look_back=1): dataX, dataY = [], [] for i in range(len(dataset)-look_back-1): a = dataset[i:(i+look_back), 0] dataX.append(a) dataY.append(dataset[i + look_back, 0]) return np.array(dataX), np.array(dataY) # fix random seed for reproducibility tf.random.set_seed(7) # load the dataset dataframe = read_csv('airline-passengers.csv', usecols=[1], engine='python') dataset = dataframe.values dataset = dataset.astype('float32') # normalize the dataset scaler = MinMaxScaler(feature_range=(0, 1)) dataset = scaler.fit_transform(dataset) # split into train and test sets train_size = int(len(dataset) * 0.67) test_size = len(dataset) - train_size train, test = dataset[0:train_size,:], dataset[train_size:len(dataset),:] # reshape into X=t and Y=t+1 look_back = 3 trainX, trainY = create_dataset(train, look_back) testX, testY = create_dataset(test, look_back) # reshape input to be [samples, time steps, features] trainX = np.reshape(trainX, (trainX.shape[0], trainX.shape[1], 1)) testX = np.reshape(testX, (testX.shape[0], testX.shape[1], 1)) # create and fit the LSTM network batch_size = 1 model = Sequential() model.add(LSTM(4, batch_input_shape=(batch_size, look_back, 1), stateful=True, return_sequences=True)) model.add(LSTM(4, batch_input_shape=(batch_size, look_back, 1), stateful=True)) model.add(Dense(1)) model.compile(loss='mean_squared_error', optimizer='adam') for i in range(100): model.fit(trainX, trainY, epochs=1, batch_size=batch_size, verbose=2, shuffle=False) model.reset_states() # make predictions trainPredict = model.predict(trainX, batch_size=batch_size) model.reset_states() testPredict = model.predict(testX, batch_size=batch_size) # invert predictions trainPredict = scaler.inverse_transform(trainPredict) trainY = scaler.inverse_transform([trainY]) testPredict = scaler.inverse_transform(testPredict) testY = scaler.inverse_transform([testY]) # calculate root mean squared error trainScore = np.sqrt(mean_squared_error(trainY[0], trainPredict[:,0])) print('Train Score: %.2f RMSE' % (trainScore)) testScore = np.sqrt(mean_squared_error(testY[0], testPredict[:,0])) print('Test Score: %.2f RMSE' % (testScore)) # shift train predictions for plotting trainPredictPlot = np.empty_like(dataset) trainPredictPlot[:, :] = np.nan trainPredictPlot[look_back:len(trainPredict)+look_back, :] = trainPredict # shift test predictions for plotting testPredictPlot = np.empty_like(dataset) testPredictPlot[:, :] = np.nan testPredictPlot[len(trainPredict)+(look_back*2)+1:len(dataset)-1, :] = testPredict # plot baseline and predictions plt.plot(scaler.inverse_transform(dataset)) plt.plot(trainPredictPlot) plt.plot(testPredictPlot) plt.show() |
Note: Your results may vary
given the stochastic nature of the algorithm or evaluation procedure,
or differences in numerical precision. Consider running the example a
few times and compare the average outcome.
Running the example produces the following output.
... 92/92 - 0s - loss: 0.0016 - 78ms/epoch - 849us/step 92/92 - 0s - loss: 0.0015 - 80ms/epoch - 874us/step 92/92 - 0s - loss: 0.0015 - 78ms/epoch - 843us/step 92/92 - 0s - loss: 0.0015 - 78ms/epoch - 845us/step 92/92 - 0s - loss: 0.0015 - 79ms/epoch - 859us/step 92/92 - 0s - loss: 0.0015 - 78ms/epoch - 848us/step 92/92 - 0s - loss: 0.0015 - 78ms/epoch - 844us/step 92/92 - 0s - loss: 0.0015 - 78ms/epoch - 852us/step 92/92 [==============================] - 0s 563us/step 44/44 [==============================] - 0s 453us/step Train Score: 20.58 RMSE Test Score: 55.99 RMSE |
The predictions on the test dataset are again worse. This is more evidence to suggest the need for additional training epochs.
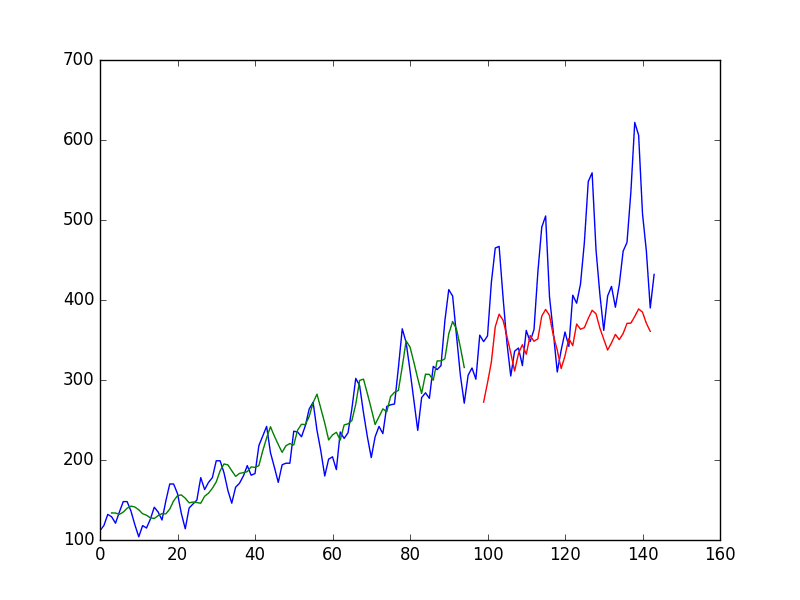
Stacked stateful LSTMs trained on regression formulation of passenger prediction problem
Summary
In this post, you discovered how to develop LSTM recurrent neural
networks for time series prediction in Python with the Keras deep
learning network.
Specifically, you learned:
- About the international airline passenger time series prediction problem
- How to create an LSTM for a regression and a window formulation of the time series problem
- How to create an LSTM with a time step formulation of the time series problem
- How to create an LSTM with state and stacked LSTMs with state to learn long sequences
Do you have any questions about LSTMs for time series prediction or about this post?
Ask your questions in the comments below, and I will do my best to answer.





No comments:
Post a Comment