It is really important to have a performance baseline on your machine learning problem.
It will give you a point of reference to which you can compare all other models that you construct.
In this post you will discover how to develop a baseline of performance for a machine learning problem using Weka.
After reading this post you will know:
- The importance in establishing a baseline of performance for your machine learning problem.
- How to calculate a baseline performance using the Zero Rule method on a regression problem.
- How to calculate a baseline performance using the Zero Rule method on a classification problem.
Importance of Baseline Results
You cannot know which algorithm will perform the best for your problem before hand so you must try a suite of algorithms and see what works best, then double down on it.
As such, it is critically important to develop a baseline of performance when working on a machine learning problem.
A baseline provides a point of reference from which to compare other machine learning algorithms.
You can get an idea of both the absolute performance increases you can achieve over the baseline as well as lift ratios that show you relatively how much better you are doing.
Without a baseline you do not know how well you are doing on your problem. You have no point of reference to consider whether or not you have or are continuing to add value. The baseline defines the hurdle that all other machine learning algorithms must cross to demonstrate “skill” on the problem.
Need more help with Weka for Machine Learning?
Take my free 14-day email course and discover how to use the platform step-by-step.
Click to sign-up and also get a free PDF Ebook version of the course.
Zero Rule For Baseline Performance
The baseline for both classification and regression problems is called the Zero Rule algorithm. Also called ZeroR or 0-R.
Let’s take a closer look at how the Zero Rule algorithm can be used on classification and regression problems with some examples.
Baseline Performance For Regression Problems
For a regression predictive modeling problem where a numeric value is predicted, the Zero Rule algorithm predicts the mean of the training dataset.
For example, let’s demonstrate the Zero Rule algorithm on the Boston House Price prediction problem. You can download the ARFF for the Boston House Price prediction dataset from the Weka datasets webpage. It is located in the datasets-numeric.jar package in the file housing.arff.
- Start the Weka GUI Chooser.
- Click the “Explorer” button to open the Weka Explorer interface.
- Load the Boston house price dataset housing.arff file.
- Click the “Classify” tab to open the classification tab.
- Select the ZeroR algorithm (it should be selected by default).
- Select the “Cross-validation” Test options (it should be selected by default).
- Click the “Start” button to evaluate the algorithm on the dataset.
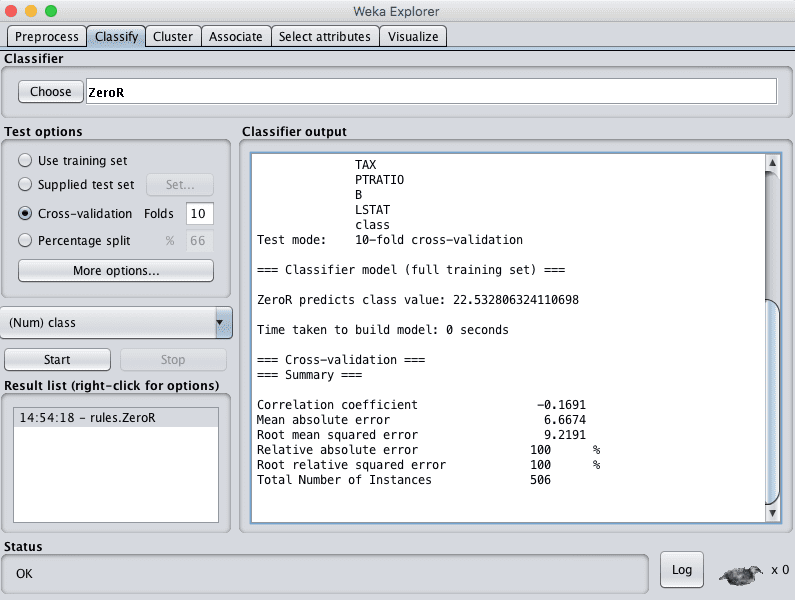
Weka Baseline Performance For a Regression Problem
The ZeroR algorithm predicts the mean Boston House price value of 22.5 (in thousands of dollars) and achieves a RMSE of 9.21.
For any machine learning algorithm to demonstrate that it has skill on this problem, it must achieve an RMSE better than this value.
Baseline Performance for Classification Problems
For a classification predictive modeling problem where a categorical value is predicted, the Zero Rule algorithm predicts the class value that has the most observations in the training dataset.
For example, let’s demonstrate the Zero Rule algorithm on the Pima Indians onset of diabetes problem. This dataset should be located in your data/ directory of your Weka installation. If not, you can download the default Weka installation from the Weka Download webpage targeted for “Other platforms” with a .zip extension, unzip it and locate the diabetes.arff file.
- Start the Weka GUI Chooser.
- Click the “Explorer” button to open the Weka Explorer interface.
- Load the Pima Indians dataset diabetes.arff file.
- Click the “Classify” tab to open the classification tab.
- Select the ZeroR algorithm (it should be selected by default).
- Select the “Cross-validation” Test options (it should be selected by default).
- Click the “Start” button to evaluate the algorithm on the dataset.
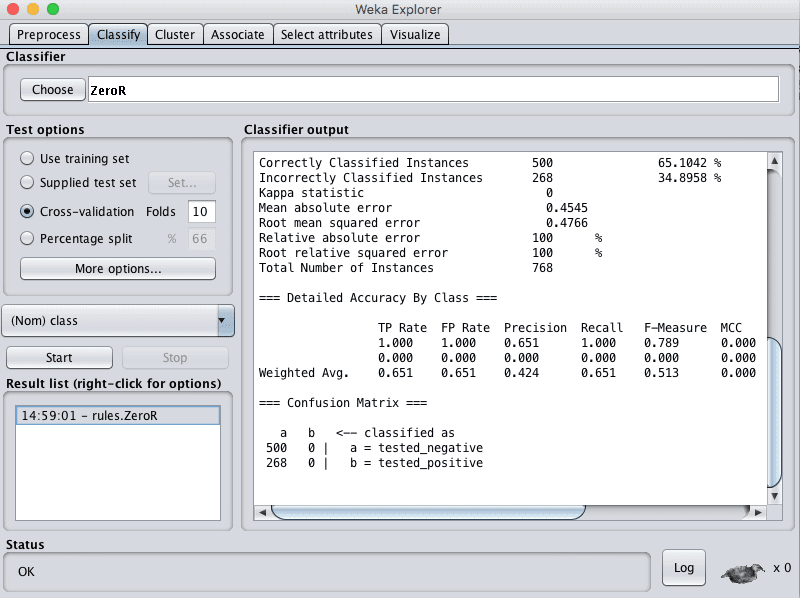
Weka Baseline Performance For a Classification Problem
The ZeroR algorithm predicts the tested_negative value for all instances as it is the majority class, and achieves an accuracy of 65.1%.
For any machine learning algorithm to demonstrate that it has skill on this problem, it must achieve an accuracy better than this value.
Summary
In this post you have discovered how to calculate a baseline performance for your machine learning problems using Weka.
Specifically, you learned:
- The importance of calculating a baseline of performance on your problem.
- How to calculate a baseline performance for a regression problem using the Zero Rule algorithm.
- How to calculate a baseline performance for a classification problem using the Zero Rule algorithm.
Do you have any questions about calculating a baseline of performance or about this post? Ask your questions in the comments and I will do my best to answer them.





No comments:
Post a Comment