Gradient boosting involves the creation and addition of decision trees sequentially, each attempting to correct the mistakes of the learners that came before it.
This raises the question as to how many trees (weak learners or estimators) to configure in your gradient boosting model and how big each tree should be.
In this post you will discover how to design a systematic experiment to select the number and size of decision trees to use on your problem.
Problem Description: Otto Dataset
In this tutorial we will use the Otto Group Product Classification Challenge dataset.
This dataset is available for free from Kaggle (you will need to sign-up to Kaggle to be able to download this dataset). You can download the training dataset train.csv.zip from the Data page and place the unzipped train.csv file into your working directory.
This dataset describes the 93 obfuscated details of more than 61,000 products grouped into 10 product categories (e.g. fashion, electronics, etc.). Input attributes are counts of different events of some kind.
The goal is to make predictions for new products as an array of probabilities for each of the 10 categories and models are evaluated using multiclass logarithmic loss (also called cross entropy).
This competition was completed in May 2015 and this dataset is a good challenge for XGBoost because of the nontrivial number of examples, the difficulty of the problem and the fact that little data preparation is required (other than encoding the string class variables as integers).
Tune the Number of Decision Trees in XGBoost
Most implementations of gradient boosting are configured by default with a relatively small number of trees, such as hundreds or thousands.
The general reason is that on most problems, adding more trees beyond a limit does not improve the performance of the model.
The reason is in the way that the boosted tree model is constructed, sequentially where each new tree attempts to model and correct for the errors made by the sequence of previous trees. Quickly, the model reaches a point of diminishing returns.
We can demonstrate this point of diminishing returns easily on the Otto dataset.
The number of trees (or rounds) in an XGBoost model is specified to the XGBClassifier or XGBRegressor class in the n_estimators argument. The default in the XGBoost library is 100.
Using scikit-learn we can perform a grid search of the n_estimators model parameter, evaluating a series of values from 50 to 350 with a step size of 50 (50, 150, 200, 250, 300, 350).
We can perform this grid search on the Otto dataset, using 10-fold cross validation, requiring 60 models to be trained (6 configurations * 10 folds).
The full code listing is provided below for completeness.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
Running this example prints the following results.
We can see that the cross validation log loss scores are negative. This is because the scikit-learn cross validation framework inverted them. The reason is that internally, the framework requires that all metrics that are being optimized are to be maximized, whereas log loss is a minimization metric. It can easily be made maximizing by inverting the scores.
The best number of trees was n_estimators=250 resulting in a log loss of 0.001152, but really not a significant difference from n_estimators=200. In fact, there is not a large relative difference in the number of trees between 100 and 350 if we plot the results.
Below is line graph showing the relationship between the number of trees and mean (inverted) logarithmic loss, with the standard deviation shown as error bars.
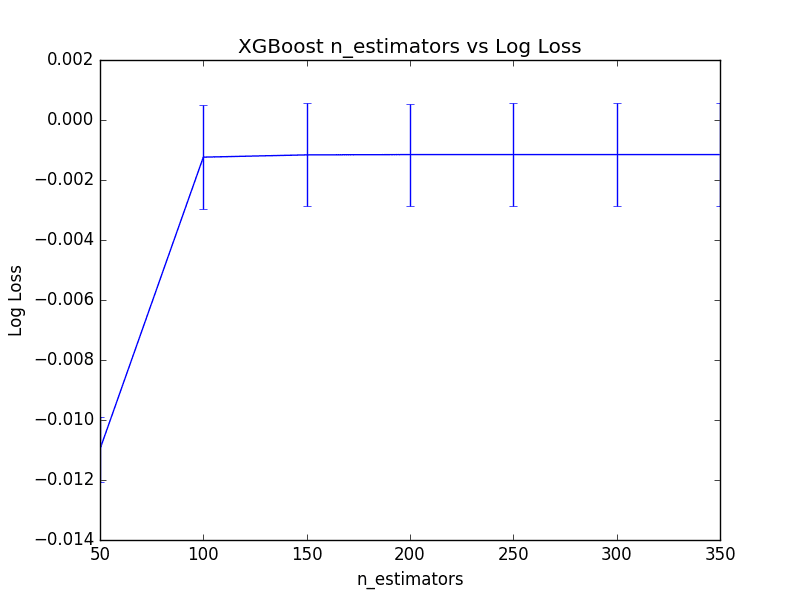
Tune The Number of Trees in XGBoost
Tune the Size of Decision Trees in XGBoost
In gradient boosting, we can control the size of decision trees, also called the number of layers or the depth.
Shallow trees are expected to have poor performance because they capture few details of the problem and are generally referred to as weak learners. Deeper trees generally capture too many details of the problem and overfit the training dataset, limiting the ability to make good predictions on new data.
Generally, boosting algorithms are configured with weak learners, decision trees with few layers, sometimes as simple as just a root node, also called a decision stump rather than a decision tree.
The maximum depth can be specified in the XGBClassifier and XGBRegressor wrapper classes for XGBoost in the max_depth parameter. This parameter takes an integer value and defaults to a value of 3.
We can tune this hyperparameter of XGBoost using the grid search infrastructure in scikit-learn on the Otto dataset. Below we evaluate odd values for max_depth between 1 and 9 (1, 3, 5, 7, 9).
Each of the 5 configurations is evaluated using 10-fold cross validation, resulting in 50 models being constructed. The full code listing is provided below for completeness.
Running this example prints the log loss for each max_depth.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
The optimal configuration was max_depth=5 resulting in a log loss of 0.001236.
Reviewing the plot of log loss scores, we can see a marked jump from max_depth=1 to max_depth=3 then pretty even performance for the rest the values of max_depth.
Although the best score was observed for max_depth=5, it is interesting to note that there was practically little difference between using max_depth=3 or max_depth=7.
This suggests a point of diminishing returns in max_depth on a problem that you can tease out using grid search. A graph of max_depth values is plotted against (inverted) logarithmic loss below.
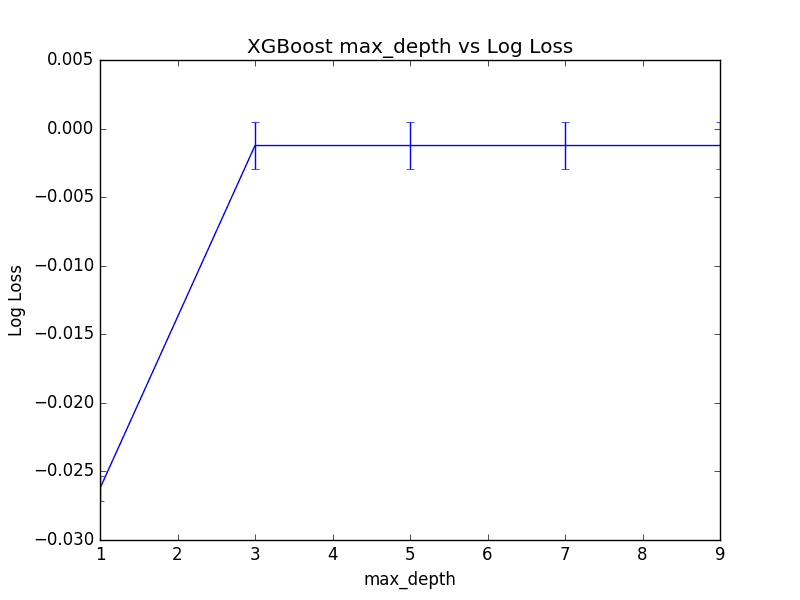
Tune Max Tree Depth in XGBoost
Tune The Number of Trees and Max Depth in XGBoost
There is a relationship between the number of trees in the model and the depth of each tree.
We would expect that deeper trees would result in fewer trees being required in the model, and the inverse where simpler trees (such as decision stumps) require many more trees to achieve similar results.
We can investigate this relationship by evaluating a grid of n_estimators and max_depth configuration values. To avoid the evaluation taking too long, we will limit the total number of configuration values evaluated. Parameters were chosen to tease out the relationship rather than optimize the model.
We will create a grid of 4 different n_estimators values (50, 100, 150, 200) and 4 different max_depth values (2, 4, 6, 8) and each combination will be evaluated using 10-fold cross validation. A total of 4*4*10 or 160 models will be trained and evaluated.
The full code listing is provided below.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
Running the code produces a listing of the logloss for each parameter pair.
We can see that the best result was achieved with a n_estimators=200 and max_depth=4, similar to the best values found from the previous two rounds of standalone parameter tuning (n_estimators=250, max_depth=5).
We can plot the relationship between each series of max_depth values for a given n_estimators.
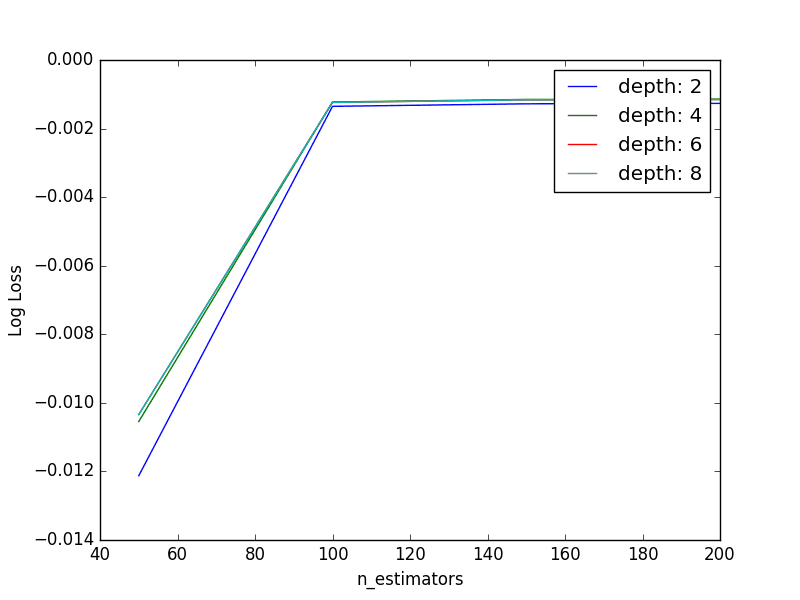
Tune The Number of Trees and Max Tree Depth in XGBoost
The lines overlap making it hard to see the relationship, but generally we can see the interaction we expect. Fewer boosted trees are required with increased tree depth.
Further, we would expect the increase complexity provided by deeper individual trees to result in greater overfitting of the training data which would be exacerbated by having more trees, in turn resulting in a lower cross validation score. We don’t see this here as our trees are not that deep nor do we have too many. Exploring this expectation is left as an exercise you could explore yourself.
Summary
In this post, you discovered how to tune the number and depth of decision trees when using gradient boosting with XGBoost in Python.
Specifically, you learned:
- How to tune the number of decision trees in an XGBoost model.
- How to tune the depth of decision trees in an XGBoost model.
- How to jointly tune the number of trees and tree depth in an XGBoost model
Do you have any questions about the number or size of decision trees in your gradient boosting model or about this post? Ask your questions in the comments and I will do my best to answer.





No comments:
Post a Comment