Machine learning algorithms make assumptions about the dataset you are modeling.
Often, raw data is comprised of attributes with varying scales. For example, one attribute may be in kilograms and another may be a count. Although not required, you can often get a boost in performance by carefully choosing methods to rescale your data.
In this post you will discover how you can rescale your data so that all of the data has the same scale.
After reading this post you will know:
- How to normalize your numeric attributes between the range of 0 and 1.
- How to standardize your numeric attributes to have a 0 mean and unit variance.
- When to choose normalization or standardization.
Predict the Onset of Diabetes
The dataset used for this example is the Pima Indians onset of diabetes dataset.
It is a classification problem where each instance represents medical details for one patient and the task is to predict whether the patient will have an onset of diabetes within the next five years.
This is a good dataset to practice scaling as the 8 input variables all have varying scales, such as the count of the number of times the patient was pregnant (preg) and the calculation of the patients body mass index (mass).
Download the dataset and place it in your current working directory.
You can also access this dataset in your Weka installation, under the data/ directory in the file called diabetes.arff.
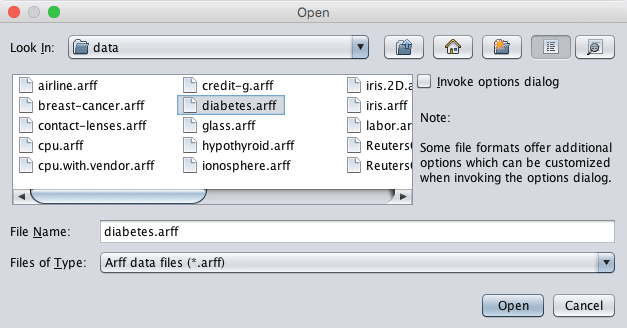
Weka Load Diabetes Dataset
About Data Filters in Weka
Weka provides filters for transforming your dataset. The best way to see what filters are supported and to play with them on your dataset is to use the Weka Explorer.
The “Filter” pane allows you to choose a filter.

Weka Filter Pane for Choosing Data Filters
Filters are divided into two types:
- Supervised Filters: That can be applied but require user control in some way. Such as rebalancing instances for a class.
- Unsupervised Filters: That can be applied in an undirected manner. For example, rescale all values to the range 0-to-1.
Personally, I think the distinction between these two types of filters is a little arbitrary and confusing. Nevertheless, that is how they are laid out.
Within these two groups, filters are further divided into filters for Attributes and Instances:
- Attribute Filters: Apply an operation on attributes or one attribute at a time.
- Instance Filters: Apply an operation on instance or one instance at a time.
This distinction makes a lot more sense.
After you have selected a filter, its name will appear in the box next to the “Choose” button.
You can configure a filter by clicking its name which will open the configuration window. You can change the parameters of the filter and even save or load the configuration of the filter itself. This is great for reproducibility.
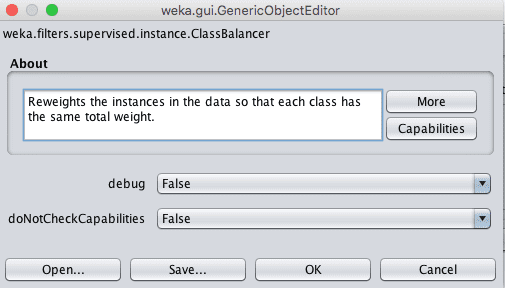
Weka Data Filter Configuration
You can learn more about each configuration option by hovering over it and reading the tooltip.
You can also read all of the details about the filter including the configuration, papers and books for further reading and more information about the filter works by clicking the “More” button.

Weka Data Filter More Information
You can close the help and apply the configuration by clicking the “OK” button.
You can apply a filter to your loaded dataset by clicking the “Apply” button next to the filter name.
Need more help with Weka for Machine Learning?
Take my free 14-day email course and discover how to use the platform step-by-step.
Click to sign-up and also get a free PDF Ebook version of the course.
Normalize Your Numeric Attributes
Data normalization is the process of rescaling one or more attributes to the range of 0 to 1. This means that the largest value for each attribute is 1 and the smallest value is 0.
Normalization is a good technique to use when you do not know the distribution of your data or when you know the distribution is not Gaussian (a bell curve).
You can normalize all of the attributes in your dataset with Weka by choosing the Normalize filter and applying it to your dataset.
You can use the following recipe to normalize your dataset:
1. Open the Weka Explorer.
2. Load your dataset.
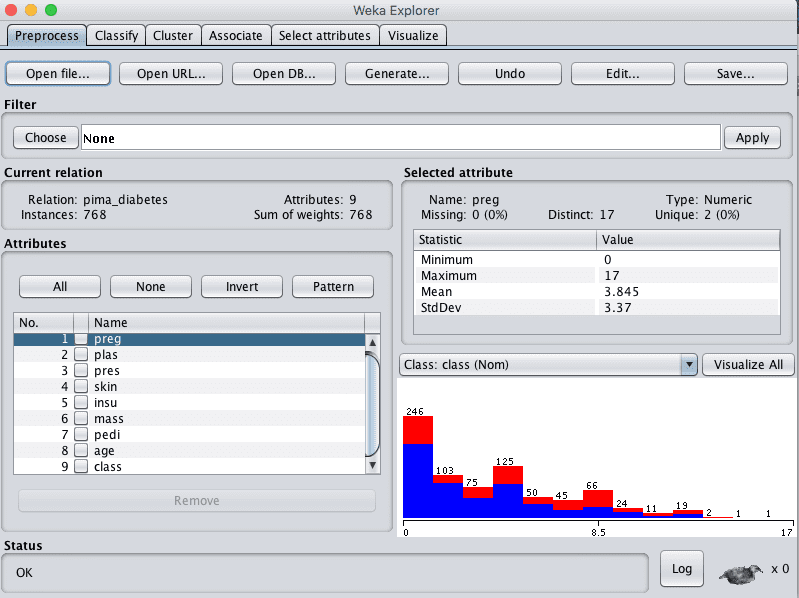
Weka Explorer Loaded Diabetes Dataset
3. Click the “Choose” button to select a Filter and select unsupervised.attribute.Normalize.
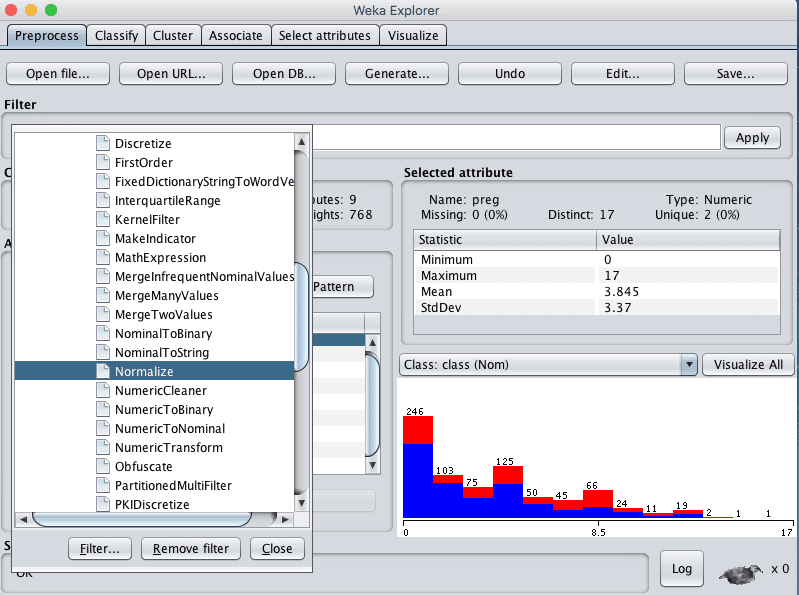
Weka Select Normalize Data Filter
4. Click the “Apply” button to normalize your dataset.
5. Click the “Save” button and type a filename to save the normalized copy of your dataset.
Reviewing the details of each attribute in the “Selected attribute” window will give you confidence that the filter was successful and that each attribute was rescaled to the range of 0 to 1.
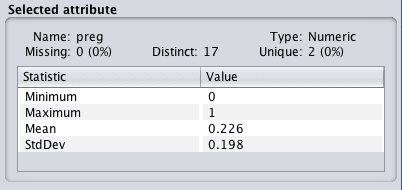
Weka Normalized Data Distribution
You can use other scales such as -1 to 1, which is useful when using support vector machines and adaboost.
Normalization is useful when your data has varying scales and the algorithm you are using does not make assumptions about the distribution of your data, such as k-nearest neighbors and artificial neural networks.
Standardize Your Numeric Attributes
Data standardization is the process of rescaling one or more attributes so that they have a mean value of 0 and a standard deviation of 1.
Standardization assumes that your data has a Gaussian (bell curve) distribution. This does not strictly have to be true, but the technique is more effective if your attribute distribution is Gaussian.
You can standardize all of the attributes in your dataset with Weka by choosing the Standardize filter and applying it your dataset.
You can use the following recipe to standardize your dataset:
1. Open the Weka Explorer
2. Load your dataset.
3. Click the “Choose” button to select a Filter and select unsupervised.attribute.Standardize.
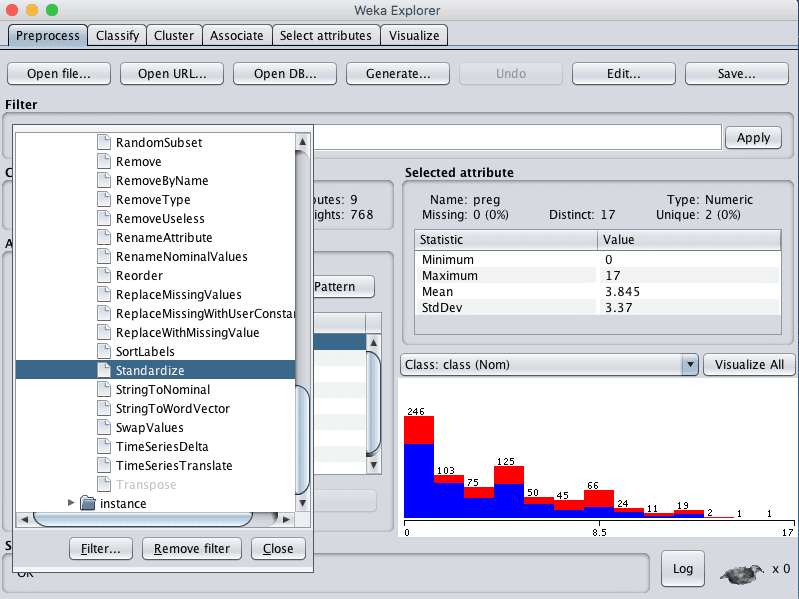
Weka Select Standardize Data Filter
4. Click the “Apply” button to normalize your dataset.
5. Click the “Save” button and type a filename to save the standardized copy of your dataset.
Reviewing the details of each attribute in the “Selected attribute” window will give you confidence that the filter was successful and that each attribute has a mean of 0 and a standard deviation of 1.
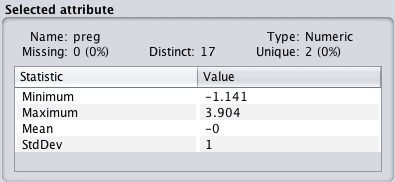
Weka Standardized Data Distribution
Standardization is useful when your data has varying scales and the algorithm you are using does make assumptions about your data having a Gaussian distribution, such as linear regression, logistic regression and linear discriminant analysis.
Summary
In this post you discovered how to rescale your dataset in Weka.
Specifically, you learned:
- How to normalize your dataset to the range 0 to 1.
- How to standardize your data to have a mean of 0 and a standard deviation of 1.
- When to use normalization and standardization.
Do you have any questions about scaling your data or about this post? Ask your questions in the comments and I will do my best to answer.





No comments:
Post a Comment