The scikit-learn library is one of the most popular platforms for everyday machine learning and data science. The reason is because it is built upon Python, a fully featured programming language.
But how do you get started with machine learning with scikit-learn.
Kevin Markham is a data science trainer who created a series of 9 videos that show you exactly how to get started in machine learning with scikit-learn.
In this post you will discover this series of videos and exactly what is covered, step-by-step to help you decide if the material will be useful to you.
Kick-start your project with my new book Machine Learning Mastery With Python, including step-by-step tutorials and the Python source code files for all examples.
Let’s get started.
Video Series Overview
Kevin Markham is a data science trainer, formally from General Assembly, the computer programming coding bootcamp.
Kevin founded his own training website called Data School and share training on data science and machine learning. He is knowledgeable in machine learning and a clear presenter in the video format.
In 2015 Mark collaborated with the machine learning competition website Kaggle and created a series of 9 videos and blog posts providing a gentle introduction to machine learning using scikit-learn.
The topics of the 9 videos were:
- What is machine learning, and how does it work?
- Setting up Python for machine learning: scikit-learn and IPython Notebook
- Getting started in scikit-learn with the famous iris dataset
- Training a machine learning model with scikit-learn
- Comparing machine learning models in scikit-learn
- Data science in Python: pandas, seaborn, scikit-learn
- Selecting the best model in scikit-learn using cross-validation
- How to find the best model parameters in scikit-learn
- How to evaluate a classifier in scikit-learn
You can review blog posts for each video on Kaggle. There is also a YouTube playlist where you can watch all 9 of the videos one after the other. You can also access IPython notebooks with the code and presentation material used in each of the 9 videos.
Next we will review the 9 videos in the series.
Need help with Machine Learning in Python?
Take my free 2-week email course and discover data prep, algorithms and more (with code).
Click to sign-up now and also get a free PDF Ebook version of the course.
Video 1: How Do Computers Learn From Data?
In this first video, Mark points out that the focus of the series is on scikit-learn for Python programmers. It also does not assume any prior knowledge or familiarity with machine learning, but he is quick to point out that you cannot effectively use scikit-learn without knowledge of machine learning.
This video covers:
- What is machine learning?
- What are the two main categories of machine learning? (supervised and unsupervised)
- What are some examples of machine learning? (passenger survival on the sinking of the Titanic)
- How does machine learning work? (learn from examples to make predictions on new data)
He defines machine learning as:
Machine learning is the semi-automated extraction of knowledge from data
He provides a nice image overview of the applied machine learning process.

Data School Machine Learning Process (Taken From Here)
Video 2: Setting up Python for Machine Learning
This second video is mainly a tutorial on how to use IPython notebooks (now probably superseded as Jupyter notebooks).
The topics covered are:
- What are the benefits and drawbacks of scikit-learn?
- How do I install scikit-learn?
- How do I use the IPython Notebook?
- What are some good resources for learning Python?
Mark spends some time on the benefits of scikit-learn, suggesting:
- It provides a consistent interface for machine learning algorithms.
- It offers many tuning parameters for each algorithm and uses sensible defaults.
- It has excellent documentation.
- It has rich functionality for tasks related to machine learning.
- It has an active community of developers on StackOverflow and the mailing list.
Comparing scikit-learn to R, he suggests R is faster to get going for machine learning in the beginning, but that you can go deeper with scikit-learn in the long run.
He also suggests that R has a statistical learning focus with an interest in model interpretability whereas scikit-learn has a machine learning focus with an interest in predictive accuracy.
I would suggest that caret in R is a powerful and perhaps unrivaled tool.
Video 3: Machine Learning First Steps With scikit-learn
This video focuses on the “hello world” of machine learning, the iris flowers dataset. This includes loading the data and reviewing the data.
The topics covered in this video are:
- What is the famous iris dataset, and how does it relate to machine learning?
- How do we load the iris dataset into scikit-learn?
- How do we describe a dataset using machine learning terminology?
- What are scikit-learn’s four key requirements for working with data?
Mark summarizes the 4 requirements for your data if you wish to work with it in scikit-learn:
- Input and response variables must separate objects (X and y).
- Input and response variables must be numeric.
- Input and response variables must be numpy arrays (ndarray).
- Input and response variables must have consistent shapes (rows and columns).
Video 4: Making Predictions with scikit-learn
This video focuses on building your first machine learning model in scikit-learn. The K-Nearest Neighbors model.
Topics covered include:
- What is the K-nearest neighbors classification model?
- What are the four steps for model training and prediction in scikit-learn?
- How can I apply this pattern to other machine learning models?
Mark summarizes the 4 steps that you must follow when working with any model (estimator as they are called in the API) in scikit-learn:
- Import class you plan to use.
- Instantiate the estimator (models are estimators).
- Fit the model with data (train the model) by calling the .fit() function.
- Predict the response for new observation (out of sample) by calling the .predict() function.
Video 5: Choosing a Machine Learning Model
This video focuses on comparing machine learning models in scikit-learn.
Mark points out that the goal of building a supervised machine learning models is to generalize to out of sample data, that is make accurate predictions on new data in the future.
The topics covered include:
- How do I choose which model to use for my supervised learning task?
- How do I choose the best tuning parameters for that model?
- How do I estimate the likely performance of my model on out-of-sample data?
This video starts to look at ways of estimating the performance of the model using a single dataset, starting with test accuracy then looks at using a train/test split and looking at test accuracy.
Video 6: Data science in Python: pandas and scikit-learn
This video looks at a related libraries that are useful when working with scikit-learn, specifically the pandas library for loading and working with data and the seaborn library for simple and clean data visualization.
This video also moves away from classification and looks at regression problems, the prediction of real valued data. Linear regression models are built and different performance metrics are reviewed for evaluating constructed models.
Below is a list of topics covered in this longer video:
- How do I use the pandas library to read data into Python?
- How do I use the seaborn library to visualize data?
- What is linear regression, and how does it work?
- How do I train and interpret a linear regression model in scikit-learn?
- What are some evaluation metrics for regression problems?
- How do I choose which features to include in my model?
Video 7: Introduction to Cross Validaiton
This video dives into the standard way for evaluating the performance of a machine learning algorithm on unseen data, by using k-fold cross validation.
Mark points out that using training accuracy alone will overfit the known data and the model will not generalize well. That using test data alone in a train/test split will have high variance, meaning it will be sensitive to the specifics of the train and test sets. He suggests that cross validation provides a good balance between these concerns.
This video covers the following topics:
- What is the drawback of using the train/test split procedure for model evaluation?
- How does K-fold cross-validation overcome this limitation?
- How can cross-validation be used for selecting tuning parameters, choosing between models, and selecting features?
- What are some possible improvements to cross-validation?
Cross validation is demonstrated for model selection, for tuning model parameters and for feature selection.
Mark lists three tips for getting the most from cross validation:
- Use repeated 10-fold cross validation to further reduce the variance of the estimated performance.
- Use a held-out validation dataset to confirm the estimates seen from cross validation and catch any data leakage errors.
- Perform all feature selection and engineering within the cross validation folds to avoid data leakage errors.
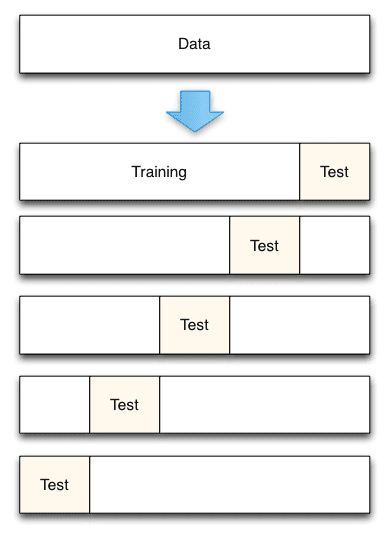
Data School K-fold Cross Validation (from here)
Video 8: Finding the Best Model Parameters
This video focuses on techniques that you can use to tune the parameters of machine learning algorithms (called hyper parameters).
Mark introduces cross validation for algorithm tuning, how to use grid search to try combinations of parameters and random search parameter combinations to improve efficiency.
This video covers the following topics:
- How can K-fold cross-validation be used to search for an optimal tuning parameter?
- How can this process be made more efficient?
- How do you search for multiple tuning parameters at once?
- What do you do with those tuning parameters before making real predictions?
- How can the computational expense of this process be reduced?
Video 9: How to evaluate a classifier in scikit-learn
This is the final video in the series and the longest.
In this video Mark covers a lot of material focusing on techniques that you can use to evaluate machine learning models on classification problems.
The topics covered in this video are:
- What is the purpose of model evaluation, and what are some common evaluation procedures?
- What is the usage of classification accuracy, and what are its limitations?
- How does a confusion matrix describe the performance of a classifier?
- What metrics can be computed from a confusion matrix?
- How can you adjust classifier performance by changing the classification threshold?
- What is the purpose of an ROC curve?
- How does Area Under the Curve (AUC) differ from classification accuracy?
Mark takes his time and carefully describes the confusion matrix, the details of sensitivity and specificity and ROC curves.
Summary
In this post you discovered Kevin Markham’s video series titled “Introduction to Machine Learning with scikit-learn“.
You learned that it is comprised of 9 videos:
- What is machine learning, and how does it work?
- Setting up Python for machine learning: scikit-learn and IPython Notebook
- Getting started in scikit-learn with the famous iris dataset
- Training a machine learning model with scikit-learn
- Comparing machine learning models in scikit-learn
- Data science in Python: pandas, seaborn, scikit-learn
- Selecting the best model in scikit-learn using cross-validation
- How to find the best model parameters in scikit-learn
- How to evaluate a classifier in scikit-learn
Mark has put together a fantastic video series that introduces you to machine learning with scikit-learn. I highly recommend watching all of it.
Have you watched some or all of these videos? What did you think? Share your thoughts in the comments.





{kind=link}
{kind=link}
No comments:
Post a Comment