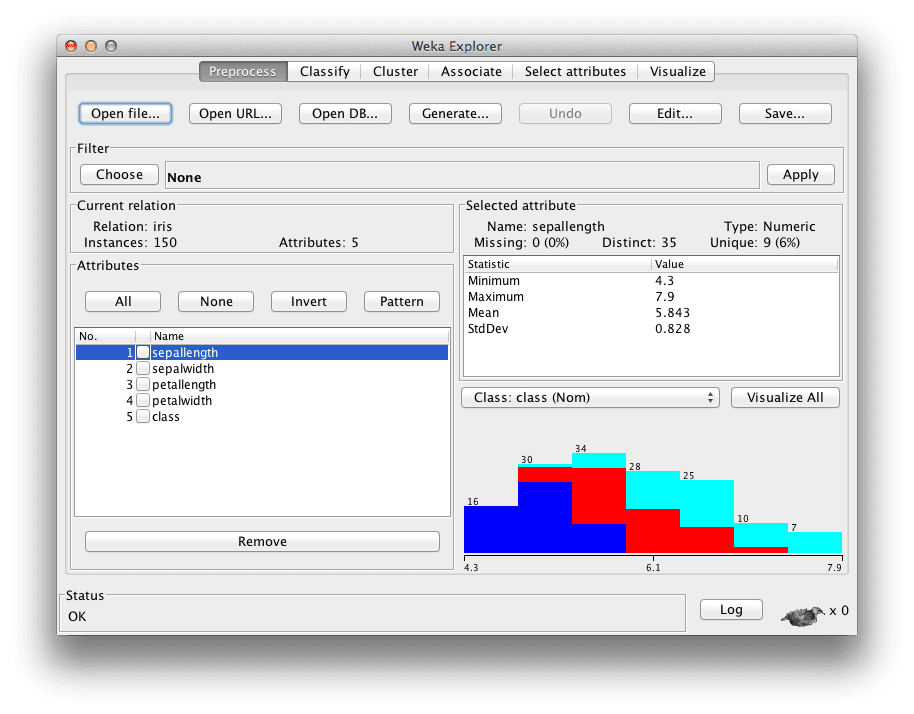
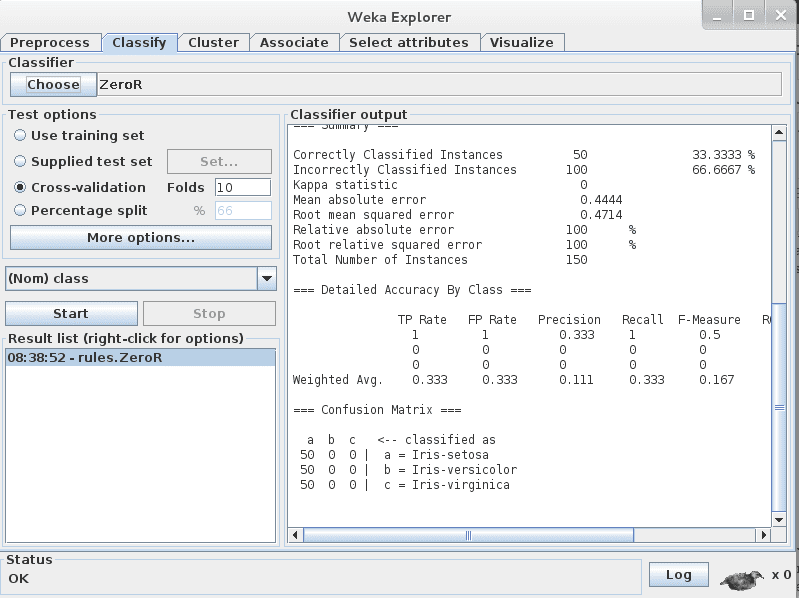
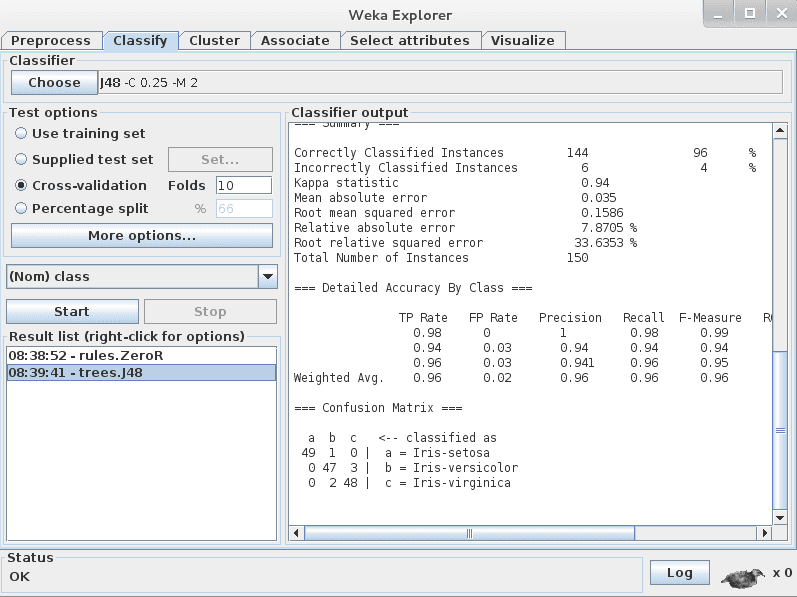
The test options you use when evaluating machine learning algorithms
can mean the difference between over-learning, a mediocre result and a
usable state-of-the-art result that you can confidently shout from the
roof tops (you really do feel like doing that sometimes).
In this post you will discover the standard test options you can use
in your algorithm evaluation test harness and how to choose the right
options next time.
Randomness
The root of the difficulty in
choosing the right test options is randomness. Most (almost all) machine
learning algorithms use randomness in some way. The randomness may be
explicit in the algorithm or may be in the sample of the data selected
to train the algorithm.
This does not mean that the algorithms produce random results, it means that they produce results with some noise or variance. We call this type of limited variance, stochastic and the algorithms that exploit it, stochastic algorithms.
Train and Test on Same Data
If you have a dataset, you may want to train the model on the dataset
and then report the results of the model on that dataset. That’s how
good the model is, right?
The problem with this approach of evaluating algorithms is that you
indeed will know the performance of the algorithm on the dataset, but do
not have any indication of how the algorithm will perform on data that
the model was not trained on (so-called unseen data).
This matters, only if you want to use the model to make predictions on unseen data.
Split Test
A simple way to use one dataset to both train and estimate the
performance of the algorithm on unseen data is to split the dataset. You
take the dataset, and split it into a training dataset and a test
dataset. For example, you randomly select 66% of the instances for
training and use the remaining 34% as a test dataset.
The algorithm is run on the training dataset and a model is created
and assessed on the test dataset and you get a performance accuracy,
lets say 87% classification accuracy.
Spit tests are fast and great when you have a lot of data or when
training a model is expensive (it resources or time). A split test on a
very very large dataset can produce an accurate estimate of the actual
performance of the algorithm.
How good is the algorithm on the data? Can we confidently say it can achieve an accuracy of 87%?
A problem is that if we spit the training dataset again into a
different 66%/34% split, we would get a different result from our
algorithm. This is called model variance.
Multiple Split Tests
A solution to our problem with the split test getting different
results on different splits of the dataset is to reduce the variance of
the random process and do it many times. We can collect the results from
a fair number of runs (say 10) and take the average.
For example, let’s say we split our dataset 66%/34%, ran our
algorithm and got an accuracy and we did this 10 times with 10 different
splits. We might have 10 accuracy scores as follows: 87, 87, 88, 89,
88, 86, 88, 87, 88, 87.
The average performance of our model is 87.5, with a standard deviation of about 0.85.
A problem with multiple split tests is that it is possible that some
data instance are never included for training or testing, where as
others may be selected multiple times. The effect is that this may skew
results and may not give an meaningful idea of the accuracy of the
algorithm.
Cross Validation
A solution to the problem of
ensuring each instance is used for training and testing an equal number
of times while reducing the variance of an accuracy score is to use cross validation. Specifically k-fold cross validation, where k is the number of splits to make in the dataset.
For example, let’s choose a value of k=10 (very common). This will
split the dataset into 10 parts (10 folds) and the algorithm will be run
10 times. Each time the algorithm is run, it will be trained on 90% of
the data and tested on 10%, and each run of the algorithm will change
which 10% of the data the algorithm is tested on.
In this example, each data instance will be used as a training
instance exactly 9 times and as a test instance 1 time. The accuracy
will not be a mean and a standard deviation, but instead will be an
exact accuracy score of how many correct predictions were made.
The k-fold cross validation method is the go-to method for evaluating
the performance of an algorithm on a dataset. You want to choose
k-values that give you a good sized training and test dataset for your
algorithm. Not too disproportionate (too large or small for training or
test). If you have a lot of data, you may may have to resort to either
sampling the data or reverting to a split test.
Cross validation does give an unbiased estimation of the algorithms
performance on unseen data, but what if the algorithm itself uses
randomness. The algorithm would produce different results for the same
training data each time it was trained with a different random number
seed (start of the sequence of pseudo-randomness). Cross validation does
not account for variance in the algorithm’s predictions.
Another point of concern is that cross validation itself uses
randomness to decide how to split the dataset into k folds. Cross
validation does not estimate how the algorithm perform with different
sets of folds.
This only matters if you want to understand how robust the algorithm is on the dataset.
Multiple Cross Validation
A way to account for the variance in the algorithm itself is to run
cross validation multiple times and take the mean and the standard
deviation of the algorithm accuracy from each run.
This will will give you an an estimate of the performance of the
algorithm on the dataset and an estimation of how robust (the size of
the standard deviation) the performance is.
If you have one mean and standard deviation for algorithm A and
another mean and standard deviation for algorithm B and they differ (for
example, algorithm A has a higher accuracy), how do you know if the
difference is meaningful?
This only matters if you want to compare the results between algorithms.
Statistical Significance
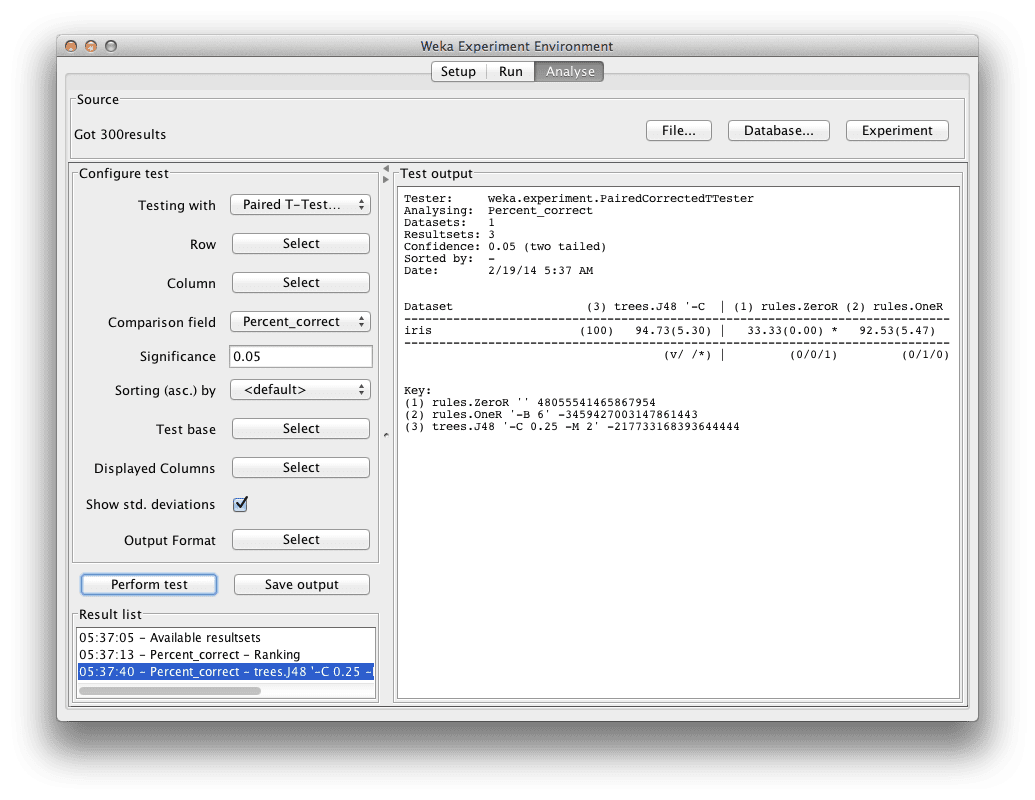
A solution to comparing algorithm performance measures when using multiple runs of k-fold cross validation is to use statistical significance tests (like the Student’s t-test).
The results from multiple runs of k-fold cross validation is a list
of numbers. We like to summarize these numbers using the mean and
standard deviation. You can think of these numbers as a sample from an
underlying population. A statistical significance test answers the
question: are two samples drawn from the same population? (no
difference). If the answer is “yes”, then, even if the mean and standard
deviations differ, the difference can be said to be not statistically
significant.
We can use statistical significance tests to give meaning to the
differences (or lack there of) between algorithm results when using
multiple runs (like multiple runs of k-fold cross validation with
different random number seeds). This can when we want to make accurate
claims about results (algorithm A was better than algorithm B and the
difference was statistically significant)
This is not the end of the story, because there are different
statistical significance tests (parametric and nonparametric) and
parameters to those tests (p-value). I’m going to draw the line here
because if you have followed me this far, you now know enough about
selecting test options to produce rigorous (publishable!) results.
Summary
In this post you have discovered the difference between the main test
options available to you when designing a test harness to evaluate
machine learning algorithms.
Specifically, you learned the utility and problems with:
- Training and testing on the same dataset
- Split tests
- Multiple split tests
- Cross validation
- Multiple cross validation
- Statistical significance
When in doubt, use k-fold cross validation (k=10) and use multiple
runs of k-fold cross validation with statistical significance tests when
you want to meaningfully compare algorithms on your dataset.