Weka is the perfect platform for learning machine learning. It provides a graphical user interface for exploring and experimenting with machine learning algorithms on datasets, without you having to worry about the mathematics or the programming.
A powerful feature of Weka is the Weka Experimenter interface. Unlike the Weka Explorer that is for filtering data and trying out different algorithms, the Experimenter is for designing and running experiments. The experimental results it produces are robust and are good enough to be published (if you know what you are doing).
In a previous post you learned how to run your first classifier in the Weka Explorer.
In this post you will discover the power of the Weka Experimenter. If you follow along the step-by-step instructions, you will design an run your first machine learning experiment in under five minutes.
Kick-start your project with my new book Machine Learning Mastery With Weka, including step-by-step tutorials and clear screenshots for all examples.

First Experiment
Photo by mhofstrand, some rights reserved
1. Download and Install Weka
Visit the Weka Download page and locate a version of Weka suitable for your computer (Windows, Mac or Linux).
Weka requires Java. You may already have Java installed and if not, there are versions of Weka listed on the download page (for Windows) that include Java and will install it for you. I’m on a Mac myself, and like everything else on Mac, Weka just works out of the box.
If you are interested in machine learning, then I know you can figure out how to download and install software into your own computer.
Need more help with Weka for Machine Learning?
Take my free 14-day email course and discover how to use the platform step-by-step.
Click to sign-up and also get a free PDF Ebook version of the course.
2. Start Weka
Start Weka. This may involve finding it in program launcher or double clicking on the weka.jar file. This will start the Weka GUI Chooser.
Weka GUI Chooser
The Weka GUI Chooser lets you choose one of the Explorer, Experimenter, KnowledgeExplorer and the Simple CLI (command line interface).
Click the “Experimenter” button to launch the Weka Experimenter.
The Weka Experimenter allows you to design your own experiments of running algorithms on datasets, run the experiments and analyze the results. It’s a powerful tool.
3. Design Experiment
Click the “New” button to create a new experiment configuration.
Weka Experimenter
Start a new Experiment
Test Options
The experimenter configures the test options for you with sensible defaults. The experiment is configured to use Cross Validation with 10 folds. It is a “Classification” type problem and each algorithm + dataset combination is run 10 times (iteration control).
Iris flower Dataset
Let’s start out by selecting the dataset.
- In the “Datasets” select click the “Add new…” button.
- Open the “data“directory and choose the “iris.arff” dataset.
The Iris flower dataset is a famous dataset from statistics and is heavily borrowed by researchers in machine learning. It contains 150 instances (rows) and 4 attributes (columns) and a class attribute for the species of iris flower (one of setosa, versicolor, virginica). You can read more about Iris flower dataset on Wikipedia.
Let’s choose 3 algorithms to run our dataset.
ZeroR
- Click “Add new…” in the “Algorithms” section.
- Click the “Choose” button.
- Click “ZeroR” under the “rules” selection.
ZeroR is the simplest algorithm we can run. It picks the class value that is the majority in the dataset and gives that for all predictions. Given that all three class values have an equal share (50 instances), it picks the first class value “setosa” and gives that as the answer for all predictions. Just off the top of our head, we know that the best result ZeroR can give is 33.33% (50/150). This is good to have as a baseline that we demand algorithms to outperform.
OneR
- Click “Add new…” in the “Algorithms” section.
- Click the “Choose” button.
- Click “OneR” under the “rules” selection.
OneR is like our second simplest algorithm. It picks one attribute that best correlates with the class value and splits it up to get the best prediction accuracy it can. Like the ZeroR algorithm, the algorithm is so simple that you could implement it by hand and we would expect that more sophisticated algorithms out perform it.
J48
- Click “Add new…” in the “Algorithms” section.
- Click the “Choose” button.
- Click “J48” under the “trees” selection.
J48 is decision tree algorithm. It is an implementation of the C4.8 algorithm in Java (“J” for Java and 48 for C4.8). The C4.8 algorithm is a minor extension to the famous C4.5 algorithm and is a very powerful prediction algorithm.
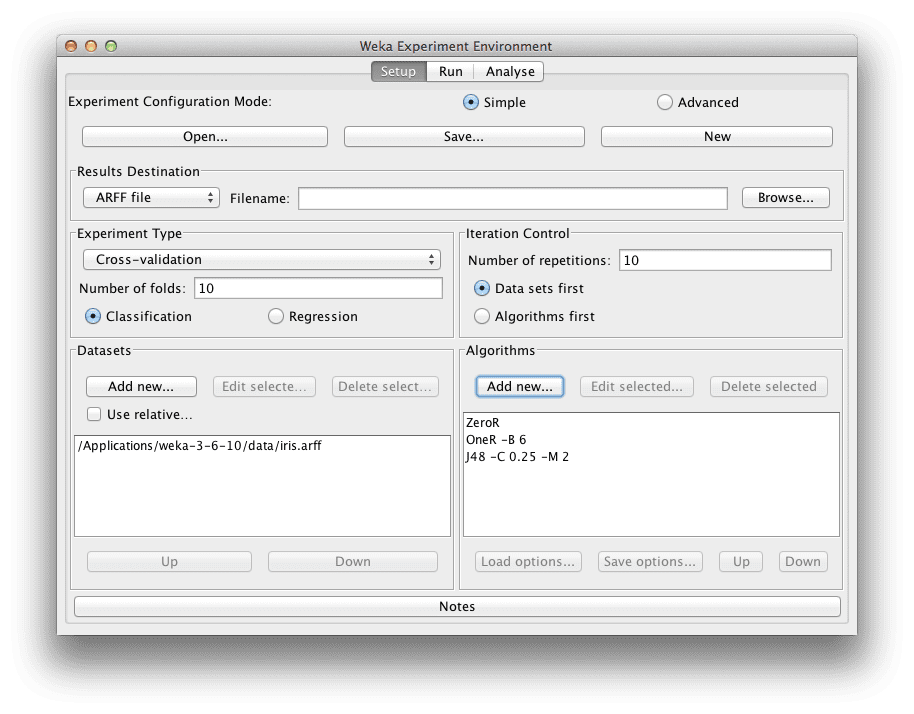
Weka Experimenter
Configure the experiment
We are ready to run our experiment.
4. Run Experiment
Click the “Run” tab at the top of the screen.
This tab is the control panel for running the currently configured experiment.
Click the big “Start” button to start the experiment and watch the “Log” and “Status” sections to keep an eye on how it is doing.

Weka Experimenter
Run the experiment
Given that the dataset is small and the algorithms are fast, the experiment should complete in seconds.
5. Review Results
Click the “Analyse” tab at the top of the screen.
This will open up the experiment results analysis panel.

Weka Experimenter
Load the experiment results
Click the “Experiment” button in the “Source” section to load the results from the current experiment.
Algorithm Rank
The first thing we want to know is which algorithm was the best. We can do that by ranking the algorithms by the number of times a given algorithm beat the other algorithms.
- Click the “Select” button for the “Test base” and choose “Ranking“.
- Now Click the “Perform test” button.

Weka Experimenter
Rank the algorithms in the experiment results
The ranking table shows the number of statistically significant wins each algorithm has had against all other algorithms on the dataset. A win, means an accuracy that is better than the accuracy of another algorithm and that the difference was statistically significant.
We can see that both J48 and OneR have one win each and that ZeroR has two losses. This is good, it means that OneR and J48 are both potentially contenders outperforming out baseline of ZeroR.
Algorithm Accuracy
Next we want to know what scores the algorithms achieved.
- Click the “Select” button for the “Test base” and choose the “ZeroR” algorithm in the list and click the “Select” button.
- Click the check-box next to “Show std. deviations“.
- Now click the “Perform test” button.

Weka Experimenter
Algorithm accuracy compared to ZeroR
In the “Test output” we can see a table with the results for 3 algorithms. Each algorithm was run 10 times on the dataset and the accuracy reported is the mean and the standard deviation in rackets of those 10 runs.
We can see that both the OneR and J48 algorithms have a little “v” next to their results. This means that the difference in the accuracy for these algorithms compared to ZeroR is statistically significant. We can also see that the accuracy for these algorithms compared to ZeroR is high, so we can say that these two algorithms achieved a statistically significantly better result than the ZeroR baseline.
The score for J48 is higher than the score for OneR, so next we want to see if the difference between these two accuracy scores is significant.
- Click the “Select” button for the “Test base” and choose the “J48” algorithm in the list and click the “Select” button.
- Now click the “Perform test” button.
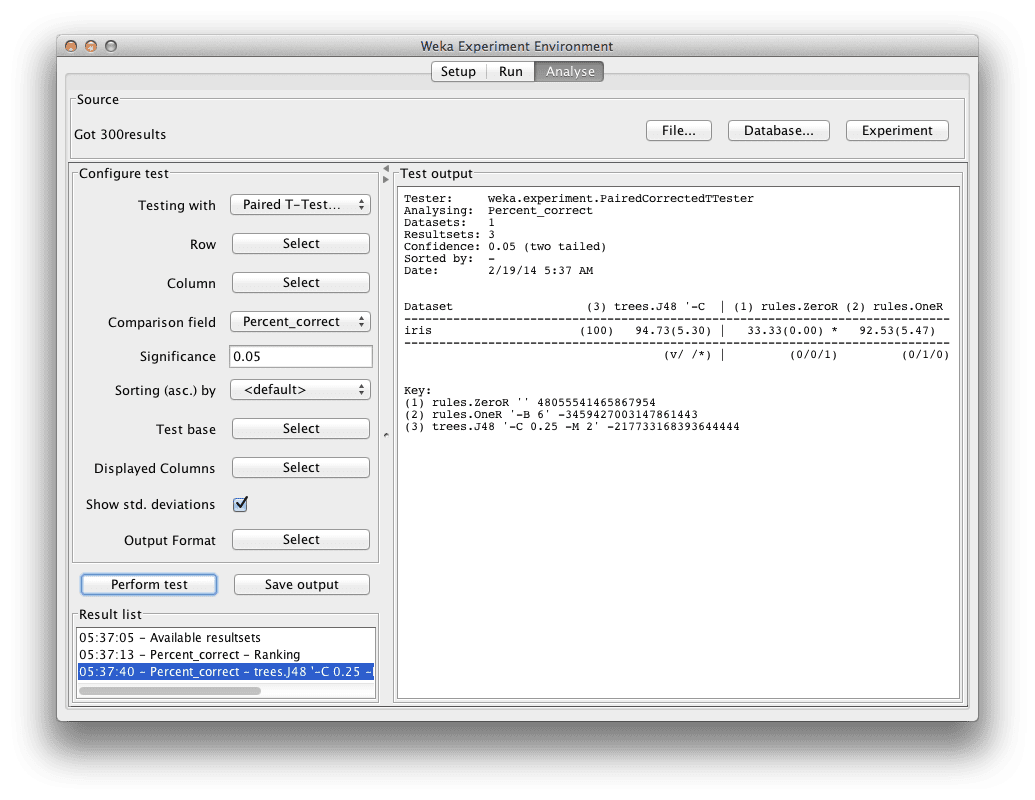
Weka Experimenter
Algorithm accuracy compared to J48
We can see that the ZeroR has a “*” next to its results, indicating that its results compared to the J48 are statistically different. But we already knew this. We do not see a “*” next to the results for the OneR algorithm. This tells us that although the mean accuracy between J48 and OneR is different, the differences is not statistically significant.
All things being equal, we would choose the OneR algorithm to make predictions on this problem because it is the simpler of the two algorithms.
If we wanted to report the results, we would say that the OneR algorithm achieved a classification accuracy of 92.53% (+/- 5.47%) which is statistically significantly better than ZeroR at 33.33% (+/- 5.47%).
Summary
You discovered how to configure a machine learning experiment with one dataset and three algorithms in Weka. You also learned about how to analyse the results from an experiment and the importance of statistical significance when interpreting results.
You now have the skill to design and run experiments with any algorithms provided by Weka on datasets of your choosing and meaningfully and confidently report results that you achieve.





No comments:
Post a Comment