Weka makes learning applied machine learning easy, efficient, and fun. It is a GUI tool that allows you to load datasets, run algorithms and design and run experiments with results statistically robust enough to publish.
I recommend Weka to beginners in machine learning because it lets them focus on learning the process of applied machine learning rather than getting bogged down by the mathematics and the programming — those can come later.
In this post, I want to show you how easy it is to load a dataset, run an advanced classification algorithm and review the results.
If you follow along, you will have machine learning results in under 5 minutes, and the knowledge and confidence to go ahead and try more datasets and more algorithms.
Kick-start your project with my new book Machine Learning Mastery With Weka, including step-by-step tutorials and clear screenshots for all examples.
1. Download Weka and Install
Visit the Weka Download page and locate a version of Weka suitable for your computer (Windows, Mac, or Linux).
Weka requires Java. You may already have Java installed and if not, there are versions of Weka listed on the download page (for Windows) that include Java and will install it for you. I’m on a Mac myself, and like everything else on Mac, Weka just works out of the box.
If you are interested in machine learning, then I know you can figure out how to download and install software into your own computer. If you need help installing Weka, see the following post that provides step-by-step instructions:
2. Start Weka
Start Weka. This may involve finding it in program launcher or double clicking on the weka.jar file. This will start the Weka GUI Chooser.
The Weka GUI Chooser lets you choose one of the Explorer, Experimenter, KnowledgeExplorer and the Simple CLI (command line interface).
Weka GUI Chooser
Click the “Explorer” button to launch the Weka Explorer.
This GUI lets you load datasets and run classification algorithms. It also provides other features, like data filtering, clustering, association rule extraction, and visualization, but we won’t be using these features right now.
Need more help with Weka for Machine Learning?
Take my free 14-day email course and discover how to use the platform step-by-step.
Click to sign-up and also get a free PDF Ebook version of the course.
3. Open the data/iris.arff Dataset
Click the “Open file…” button to open a data set and double click on the “data” directory.
Weka provides a number of small common machine learning datasets that you can use to practice on.
Select the “iris.arff” file to load the Iris dataset.
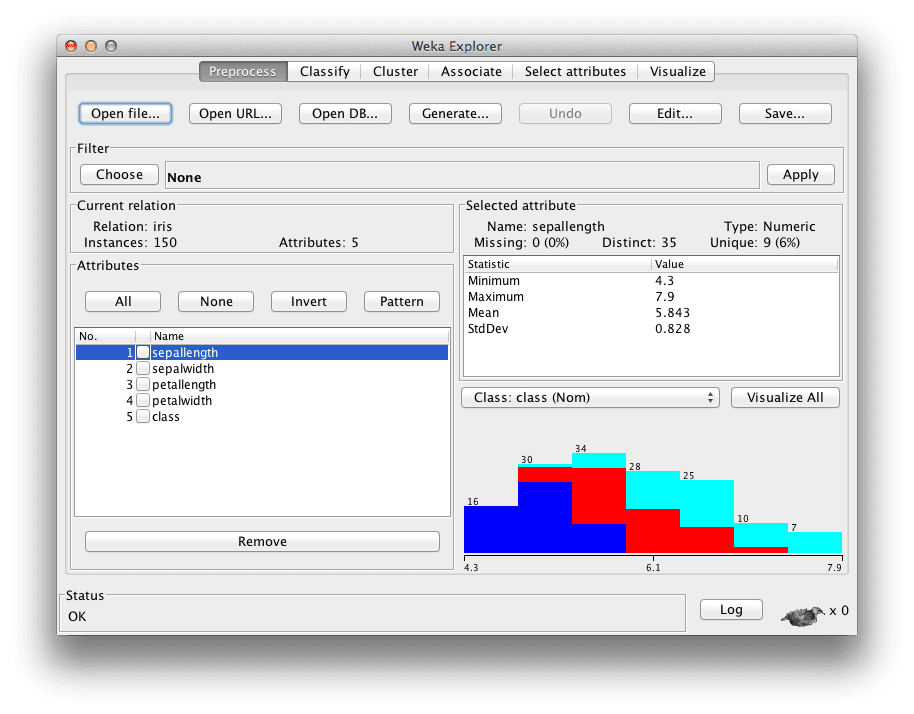
Weka Explorer Interface with the Iris dataset loaded
The Iris Flower dataset is a famous dataset from statistics and is heavily borrowed by researchers in machine learning. It contains 150 instances (rows) and 4 attributes (columns) and a class attribute for the species of iris flower (one of setosa, versicolor, and virginica). You can read more about Iris flower dataset on Wikipedia.
4. Select and Run an Algorithm
Now that you have loaded a dataset, it’s time to choose a machine learning algorithm to model the problem and make predictions.
Click the “Classify” tab. This is the area for running algorithms against a loaded dataset in Weka.
You will note that the “ZeroR” algorithm is selected by default.
Click the “Start” button to run this algorithm.
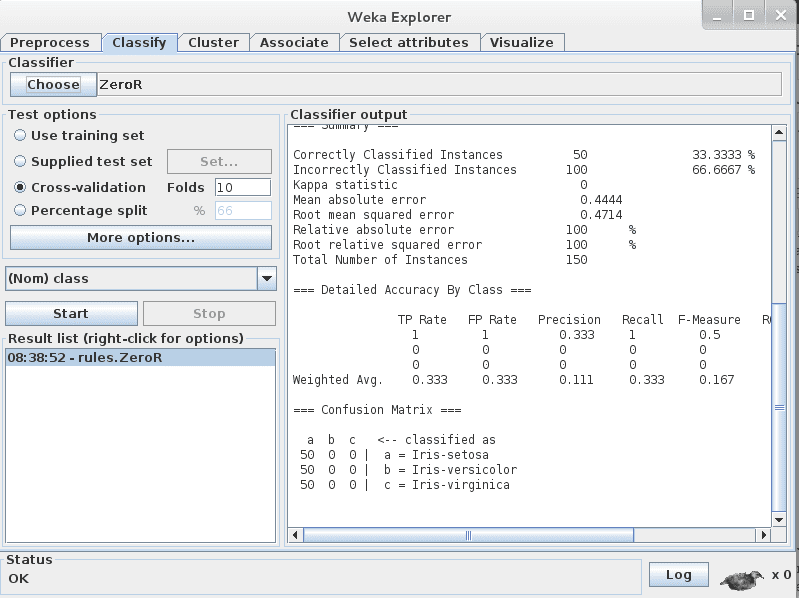
Weka Results for the ZeroR algorithm on the Iris flower dataset
The ZeroR algorithm selects the majority class in the dataset (all three species of iris are equally present in the data, so it picks the first one: setosa) and uses that to make all predictions. This is the baseline for the dataset and the measure by which all algorithms can be compared. The result is 33%, as expected (3 classes, each equally represented, assigning one of the three to each prediction results in 33% classification accuracy).
You will also note that the test options selects Cross Validation by default with 10 folds. This means that the dataset is split into 10 parts: the first 9 are used to train the algorithm, and the 10th is used to assess the algorithm. This process is repeated, allowing each of the 10 parts of the split dataset a chance to be the held-out test set. You can read more about cross validation here.
The ZeroR algorithm is important, but boring.
Click the “Choose” button in the “Classifier” section and click on “trees” and click on the “J48” algorithm.
This is an implementation of the C4.8 algorithm in Java (“J” for Java, 48 for C4.8, hence the J48 name) and is a minor extension to the famous C4.5 algorithm. You can read more about the C4.5 algorithm here.
Click the “Start” button to run the algorithm.
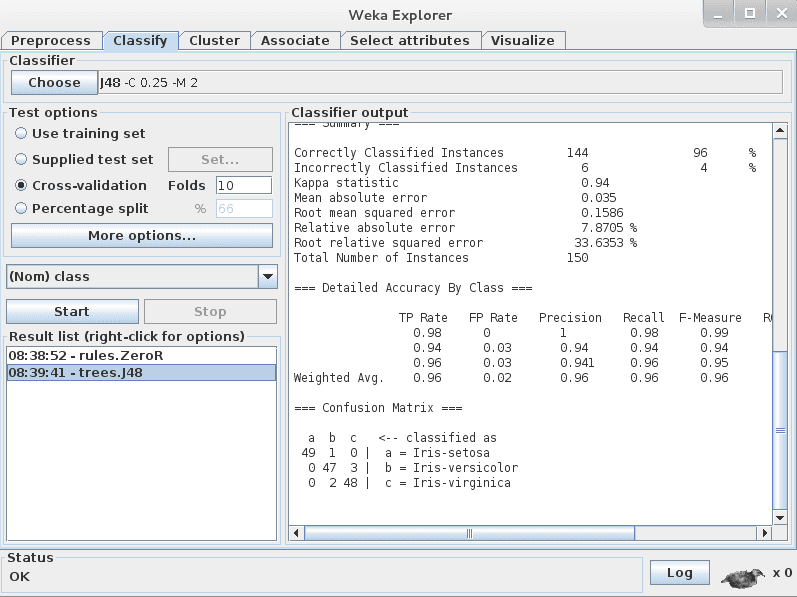
Weka J48 algorithm results on the Iris flower dataset
5. Review Results
After running the J48 algorithm, you can note the results in the “Classifier output” section.
The algorithm was run with 10-fold cross-validation: this means it was given an opportunity to make a prediction for each instance of the dataset (with different training folds) and the presented result is a summary of those predictions.

Just the results of the J48 algorithm on the Iris flower dataset in Weka
Firstly, note the Classification Accuracy. You can see that the model achieved a result of 144/150 correct or 96%, which seems a lot better than the baseline of 33%.
Secondly, look at the Confusion Matrix. You can see a table of actual classes compared to predicted classes and you can see that there was 1 error where an Iris-setosa was classified as an Iris-versicolor, 2 cases where Iris-virginica was classified as an Iris-versicolor, and 3 cases where an Iris-versicolor was classified as an Iris-setosa (a total of 6 errors). This table can help to explain the accuracy achieved by the algorithm.
Summary
In this post, you loaded your first dataset and ran your first machine learning algorithm (an implementation of the C4.8 algorithm) in Weka. The ZeroR algorithm doesn’t really count: it’s just a useful baseline.
You now know how to load the datasets that are provided with Weka and how to run algorithms: go forth and try different algorithms and see what you come up with.
Leave a note in the comments if you can achieve better than 96% accuracy on the Iris dataset.





No comments:
Post a Comment