Emotion recognition from EEG signals is a challenging task. Researchers over the past few years have been working extensively to achieve high accuracy in emotion recognition from physiological signals. Several feature extraction methods, as well as machine learning models, have been proposed by earlier studies. In this paper, we propose a hybrid CNN-LSTM model for multi-class emotion recognition from EEG signals. The experiment is conducted on the standard benchmark DEAP dataset. The proposed model gives test accuracies of 96.87% and 97.31% on valence and arousal dimensions, respectively. Furthermore, the proposed model also succeeds in achieving state-of-the-art accuracy in both valence and arousal dimensions.
What is an EEG?
An EEG is a test that detects abnormalities in your brain waves, or in the electrical activity of your brain. During the procedure, electrodes consisting of small metal discs with thin wires are pasted onto your scalp. The electrodes detect tiny electrical charges that result from the activity of your brain cells. The charges are amplified and appear as a graph on a computer screen, or as a recording that may be printed out on paper. Your healthcare provider then interprets the reading.
During an EEG, your healthcare provider typically evaluates about 100 pages, or computer screens, of activity. He or she pays special attention to the basic waveform, but also examines brief bursts of energy and responses to stimuli, such as flashing lights.
Evoked potential studies are related procedures that also may be done. These studies measure electrical activity in your brain in response to stimulation of sight, sound, or touch.
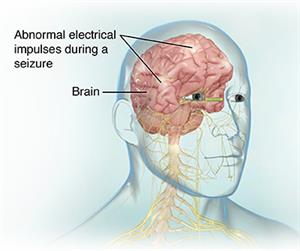
Why might I need an EEG?
The EEG is used to evaluate several types of brain disorders. When epilepsy is present, seizure activity will appear as rapid spiking waves on the EEG.
People with lesions of their brain, which can result from tumors or stroke, may have unusually slow EEG waves, depending on the size and the location of the lesion.
The test can also be used to diagnose other disorders that influence brain activity, such as Alzheimer's disease, certain psychoses, and a sleep disorder called narcolepsy.
The EEG may also be used to determine the overall electrical activity of the brain (for example, to evaluate trauma, drug intoxication, or extent of brain damage in comatose patients). The EEG may also be used to monitor blood flow in the brain during surgical procedures.
There may be other reasons for your healthcare provider to recommend an EEG.
What are the risks of an EEG?
The EEG has been used for many years and is considered a safe procedure. The test causes no discomfort. The electrodes record activity. They do not produce any sensation. In addition, there is no risk of getting an electric shock.
In rare instances, an EEG can cause seizures in a person with a seizure disorder. This is due to the flashing lights or the deep breathing that may be involved during the test. If you do get a seizure, your healthcare provider will treat it immediately.
Other risks may be present, depending on your specific medical condition. Be sure to discuss any concerns with your healthcare provider before the procedure.
Certain factors or conditions may interfere with the reading of an EEG test. These include:
- Low blood sugar (hypoglycemia) caused by fasting
- Body or eye movement during the tests (but this will rarely, if ever, significantly interfere with the interpretation of the test)
- Lights, especially bright or flashing ones
- Certain medicines, such as sedatives
- Drinks containing caffeine, such as coffee, cola, and tea (while these drinks can occasionally alter the EEG results, this almost never interferes significantly with the interpretation of the test)
- Oily hair or the presence of hair spray
How do I get ready for an EEG?
Ask your healthcare provider to tell you what you should do before your test. Below is a list of common steps that you may be asked to do.
- Your healthcare provider will explain the procedure to you and you can ask questions.
- You will be asked to sign a consent form that gives your permission to do the procedure. Read the form carefully and ask questions if something is not clear.
- Wash your hair with shampoo, but do not use a conditioner the night before the test. Do not use any hair care products, such as hairspray or gels.
- Tell your healthcare provider of all medicines (prescription and over-the-counter) and herbal supplements that you are taking.
- Discontinue using medicines that may interfere with the test if your healthcare provider has directed you to do so. Do not stop using medicines without first consulting your healthcare provider.
- Avoid consuming any food or drinks containing caffeine for 8 to 12 hours before the test.
- Follow any directions your healthcare provider gives you about reducing your sleep the night before the test. Some EEG tests require that you sleep through the procedure, and some do not. If the EEG is to be done during sleep, adults may not be allowed to sleep more than 4 or 5 hours the night before the test. Children may not be allowed to sleep for more than 5 to 7 hours the night before.
- Avoid fasting the night before or the day of the procedure. Low blood sugar may influence the results.
- Based on your medical condition, your healthcare provider may request other specific preparations.
What happens during an EEG?
An EEG may be done on an outpatient basis, or as part of your stay in a hospital. Procedures may vary depending on your condition and your healthcare provider's practices. Talk with your healthcare provider about what you will experience during your test.
Generally, an EEG procedure follows this process:
- You will be asked to relax in a reclining chair or lie on a bed.
- Between 16 and 25 electrodes will be attached to your scalp with a special paste, or a cap containing the electrodes will be used.
- You will be asked to close your eyes, relax, and be still.
- Once the recording begins, you will need to remain still throughout the test. Your healthcare provider may monitor you through a window in an adjoining room to observe any movements that can cause an inaccurate reading, such as swallowing or blinking. The recording may be stopped periodically to let you rest or reposition yourself.
- After your healthcare provider does the initial recording while you are at rest, he or she may test you with various stimuli to produce brain wave activity that does not show up while you are resting. For example, you may be asked to breathe deeply and rapidly for 3 minutes, or you may be exposed to a bright flashing light.
- This study is generally done by an EEG technician and may take approximately 45 minutes to 2 hours.
- If you are being evaluated for a sleep disorder, the EEG may be done while you are asleep.
- If you need to be monitored for a longer period of time, you may also be admitted to the hospital for prolonged EEG (24-hour EEG) monitoring.
- In cases where prolonged inpatient monitoring is not possible, your doctor may consider doing an ambulatory EEG.
What happens after an EEG?
Once the test is completed, the electrodes will be removed and the electrode paste will be washed off with warm water, acetone, or witch hazel. In some cases, you may need to wash your hair again at home.
If you took any sedatives for the test, you may be required to rest until the sedatives have worn off. You will need to have someone drive you home.
Skin irritation or redness may be present at the locations where the electrodes were placed, but this will wear off in a few hours.
Your healthcare provider will inform you when you may resume any medicines you stopped taking before the test.
Your healthcare provider may give you additional or alternate instructions after the procedure, depending on your particular situation.
Next steps
Before you agree to the test or the procedure make sure you know:
- The name of the test or procedure
- The reason you are having the test or procedure
- What results to expect and what they mean
- The risks and benefits of the test or procedure
- What the possible side effects or complications are
- When and where you are to have the test or procedure
- Who will do the test or procedure and what that person’s qualifications are
- What would happen if you did not have the test or procedure
- Any alternative tests or procedures to think about
- When and how will you get the results
- Who to call after the test or procedure if you have questions or problems
- How much will you have to pay for the test or procedure
Emotional state classification from EEG data using machine learning approach
Introduction
Emotion plays an important role in human–human communication and interaction. The ability to recognize the emotional states of people surrounding us is an important part of natural communication. Considering the explosion of machines in our commonness, emotion interaction between humans and machines has been one of the most important issues in advanced human–machine interaction and brain–computer interface today [1]. To approach the affective human–machine interaction, one of the most important prerequisites is to develop a reliable emotion recognition system, which can guarantee acceptable recognition accuracy, robustness against any artifacts, and adaptability to practical applications.
Numerous studies on engineering approaches to automatic emotion recognition have been performed in the past few decades. They can be categorized into three main approaches. The first kind of approaches focuses on the analysis of facial expressions or speech [2], [3], [4]. These audio-visual based techniques allow noncontact detection of emotion, so they do not give the subject any discomfort. However, these techniques might be more prone to deception, and the parameters easily vary in different situations. The second kind of approaches focuses on periphery physiological signals. Various studies show that peripheral physiological signals changing in different emotional states can be observed on changes of autonomic nervous system in the periphery, such as electrocardiogram (ECG), skin conductance (SC), respiration, and pulse [5], [6], [7]. In comparison with audio-visual based methods, the responses of peripheral physiological signals tend to provide more detailed and complex information as an indicator for estimating emotional states.
The third kind of approaches focuses on brain signals captured from central nervous system such as electroencephalograph (EEG), electrocorticography (ECoG), and functional magnetic resonance imaging (fMRI). Among these brain signals, EEG signals have been proven to provide informative characteristics in responses to the emotional states [8], [9], [10]. Since Davidson et al. [11] suggested that frontal brain electrical activity was associated with the experience of positive and negative emotions, the studies of associations between EEG asymmetry and emotions have been received much attention [12], [13], [14]. Besides the EEG asymmetry for the study of emotion, event-related potentials indexing a relatively small proportion of mean EEG activity were also been used to study the association with EEG and emotion [15], [16], [17]. However, these approaches still suffer from two problems. The first one is that the existing approaches need to make an average of EEG features. This makes them need longer time windows to recognize the emotion state based on EEG signals. The other one is that only the relatively small percentage of EEG activity that can be captured. These limitations make the existing methods inappropriate or insufficient for assessing emotion states for real-world applications.
With the rapid development of dry electrode, digital signal processing, machine learning, and various real-world applications of brain–computer interface for normal people, more and more researchers focused on EEG-based emotion recognition in recent years, and various approaches have been developed. However, there still exist some limitations on traditional EEG-based emotion recognition framework. One of the major limitations is that almost all existing approaches do not consider the characteristics of EEG and emotion. As EEG is an unsteady voltage signal, the feature extracted from EEG usually changes dramatically, whereas emotion states change gradually. This leads to bigger differences among EEG features, even with the same emotion state in adjacent time. Moreover, existing studies can only predict the labels of emotion samples, but could not reflect the trend of emotion changes. To overcome these shortcomings, in this paper, we introduce a feature smoothing method and an approach to tracking the trajectory of emotion changes. To validate the effectiveness of the proposed methods, we compare three kinds of EEG emotion-specific features, and evaluate the performance of classification of two emotion states from EEG data of six subjects.
The rest of this paper is structured as follows. In Section 2, we give a brief overview of related work on emotion models, effect of movie in emotion induction, and various methods for EEG-based emotion classification. Section 3 gives the motivation and rationale for our experimental setting of emotion induction. A systematic description of feature extraction, feature smoothing, feature dimensionality reduction, classification, and trajectory of emotion changes is given in Section 4. In Section 5, we present experimental results that we achieved, and conclusions and feature work are presented at the end.
Section snippets
Models of emotions
As all people express their emotions differently, it is not an easy task to judge and model human emotions. Researchers often use two different methods to model emotions. One approach is to organize emotion as a set of diverse discrete emotions. In this model, there is a set of emotions which are more basic than others, and these basic emotions can be seen as prototypes from which other emotions are derived. The problem with this method is that there is still little agreement among scientists
Stimulus material and presentation
To stimulate subject's emotions, we used a set of movie clips that was mainly extracted from Oscar films as elicitors. As shown in Table 1, the movie clips set includes six clips for each of two target emotional states: positive and negative emotions. The selection criteria for movie clips were as follows: (a) the length of the scene should be relatively short; (b) the scene is to be understood without explanation; and (c) the scene should elicit single desired target emotion of subjects. To
Methods
The EEG data we got from the experiments were analyzed through several procedures, including signal preprocessing, feature extraction, feature smoothing, feature dimensionality reduction, emotional state classification and trajectory of emotion changes, as shown in Fig. 4.
Experimental results and discussions
In order to perform a more reliable classification process, we constructed a training set and a test set for each subject. The training set was formed by the former four sessions of EEG data for each emotional state. The test set was formed by the last two sessions of EEG data for each emotional state. The number of feature dimension equals the product of the number of features obtained for each trial of the EEG signal and the number of scalp electrodes.
Conclusions
In this paper, we have investigated the characteristics of EEG features for emotion classification and technique for tracking the trajectory of emotion changes. A series of experiments of using movie clips are designed to arouse emotion of subjects and an EEG data set of six subjects is collected. Three kinds of features, namely power spectrum, wavelet and nonlinear dynamical analysis, are extracted to assess the association between the EEG data and emotional states. All of these features are
Acknowledgments
This work was supported partially by the National Basic Research Program of China (Grant no. 2013CB329401 and Grant no. 2009CB320901), the National Natural Science Foundation of China (Grant no. 61272248), and the Science and Technology Commission of Shanghai Municipality (Grant no. 13511500200).
Xiaowei Wang received his B.S. degree and the M.S. degree in computer science from Qingdao University, Qingdao, China, in 2002 and 2005, respectively. He is currently a Ph.D. candidate in the Brain-like Computing and Machine Intelligence Group, Shanghai Jiao Tong University. His research interests included biomedical engineering, biomechanical signal processing, machine learning and the development of brain–computer interface (BCI).
Detection of Monkeypox Among Different Pox Diseases with Different Pre-Trained Deep Learning Models
Monkeypox is a viral disease that has recently rapidly spread. Experts have trouble diagnosing the disease because it is similar to other smallpox diseases. For this reason, researchers are working on artificial intelligence-based computer vision systems for the diagnosis of monkeypox to make it easier for experts, but a professional dataset has not yet been created. Instead, studies have been carried out on datasets obtained by collecting informal images from the Internet. The accuracy of state-of-the-art deep learning models on these datasets is unknown. Therefore, in this study, monkeypox disease was detected in cowpox, smallpox, and chickenpox diseases using the pre-trained deep learning models VGG-19, VGG-16, MobileNet V2, GoogLeNet, and EfficientNet-B0. In experimental studies on the original and augmented datasets, MobileNet V2 achieved the highest classification accuracy of 99.25% on the augmented dataset. In contrast, the VGG-19 model achieved the highest classification accuracy with 78.82% of the original data. Considering these results, the shallow model yielded better results for the datasets with fewer images. When the amount of data increased, the success of deep networks was better because the weights of the deep models were updated at the desired level.An increasing amount of research has recentlyfocused on representing affective states as
continuous numerical values on multiple di-
mensions, such as the valence-arousal (VA)
space. Compared to the categorical approach
that represents affective states as several clas-
ses (e.g., positive and negative), the dimen-
sional approach can provide more fine-
grained sentiment analysis. However, affec-
tive resources with valence-arousal ratings are
still very rare, especially for the Chinese lan-
guage. Therefore, this study builds 1) an af-
fective lexicon called Chinese valence-arousal
words (CVAW) containing 1,653 words, and 2)
an affective corpus called Chinese valence-
arousal text (CVAT) containing 2,009 sen-
tences extracted from web texts. To improve
the annotation quality, a corpus cleanup pro-
cedure is used to remove outlier ratings and
improper texts. Experiments using CVAW
words to predict the VA ratings of the CVAT
corpus show results comparable to those ob-
tained using English affective resources.
1 Introduction
Sentiment analysis has emerged as a leading tech-
nique to automatically identify affective infor-
mation from texts (Pang and Lee, 2008; Calvo and
D'Mello, 2010; Liu, 2012; Feldman, 2013). In sen-
timent analysis, affective states are generally rep-
resented using either categorical or dimensional
approaches.
The categorical approach represents affective
states as several discrete classes such as positive,
neutral, negative, and Ekman’s six basic emotions
(e.g., anger, happiness, fear, sadness, disgust and
surprise) (Ekman, 1992). Based on this representa-
tion, various practical applications have been de-
veloped such as aspect-based sentiment analysis
(Schouten and Frasincar, 2016; Pontiki et al.,
2015), Twitter sentiment analysis (Saif et al., 2013;
Rosenthal et al., 2015), deceptive opinion spam de-
tection (Li et al., 2014), and cross-lingual portabil-
ity (Banea et al., 2013; Xu et al., 2015).
The dimensional approach represents affective
states as continuous numerical values in multiple
dimensions, such as valence-arousal (VA) space
(Russell, 1980), as shown in Fig. 1. The valence
represents the degree of pleasant and unpleasant
(i.e., positive and negative) feelings, while the
arousal represents the degree of excitement and
calm. Based on this representation, any affective
state can be represented as a point in the VA coor-
dinate plane. For many application domains (e.g.,
product reviews, political stance detection, etc.), it
can be useful to identify highly negative-arousing
and highly positive-arousing texts because they are
usually of interest to many users and should be
given a higher priority. Dimensional sentiment
540analysis can accomplish this by recognizing the va-
lence-arousal ratings of texts and ranking them ac-
cordingly to provide more intelligent and fine-
grained services.
In developing dimensional sentiment applica-
tions, affective lexicons and corpora with valence-
arousal ratings are useful resources but few exist,
especially for the Chinese language. Therefore, this
study focuses on building Chinese valence-arousal
resources, including an affective lexicon called the
Chinese valence-arousal words (CVAW) and an
affective corpus called the Chinese valence-arousal
text (CVAT). The CVAW contains 1,653 affective
words annotated with valence-arousal ratings by
five annotators. The CVAT contains 2,009 sen-
tences extracted from web texts annotated with
crowd-sourced valence-arousal ratings. To further
demonstrate the feasibility of the constructed re-
sources, we conduct an experiment to predict the
VA ratings of the CVAT corpus using CVAW
words, and compare its performance to a similar
evaluation of English affective resources.
To our best knowledge, only one previous study
has manually created a small number (162) of Chi-
nese VA words (Wei et al, 2011), and none have
focused on creating Chinese VA corpora. This pi-
lot study thus aims to build such resources to en-
rich the research and development of multi-lingual
sentiment analysis in VA dimensions.
The rest of this paper is organized as follows.
Section 2 introduces existing affective lexicons and
corpora. Section 3 describes the process of build-
ing the Chinese affective resource. Section 4 pre-
sents the analysis results and feasibility evaluation.
Conclusions are finally drawn in Section 5.
2 Related Work
Affective resources are usually obtained by either
self-labeling or manual annotation. In the self-
labeling approach, users proactively provide their
feelings and opinions after browsing the web con-
tent. For example, users may read a news article
and then offer comments. A user can also review
the products available for sale in online stores. In
the manual annotation method, trained annotators
are asked to create affective annotations for specif-
ic language resources for research purposes. Sev-
eral well-known affective resources are introduced
as follows.
SentiWordNet is a lexical resource for opinion
mining, which assigns to each synset of WordNet
three sentiment ratings: positive, negative, and ob-
jective (Esuli and Sebastiani, 2006). Linguistic In-
quiry and Word Count (LIWC) calculates the de-
gree to which people use different categories of
words across a broad range of texts (Pennebaker et
al., 2007). In the LIWC 2007 version, the annota-
tors were asked to note their emotions and thoughts
about personally relevant topics. The Affective
Norms for English Words (ANEW) provides 1,034
English words with ratings in the dimensions of
pleasure, arousal and dominance (Bradley and
Lang, 1999). In addition to these English-language
sentiment lexicons, a few Chinese lexicons have
been constructed. The Chinese LIWC (C-LIWC)
dictionary is a Chinese translation of the LIWC
with manual revisions to fit the practical character-
istics of Chinese usages (Huang et al., 2012). The
NTU Sentiment dictionary (NTUSD) has adopted a
combination of manual and automatic methods to
include positive and negative emotional words (Ku
and Chen, 2007). Among the above affective lexi-
cons, only ANEW is dimensional, providing real-
valued scores for three dimensions, and the others
are categorical, providing information related to
sentiment polarity or intensity.
In addition to lexicon resources, several English-
language affective corpora have been proposed,
such as Movie Review Data (Pang et al. 2002), the
MPQA Opinion Corpus (Wiebe et al., 2005), and
Affective Norms for English Text (ANET) (Brad-
ley and Lang, 2007). In addition, only ANET pro-
vides VA ratings. The above dimensional affective
resources ANEW and ANET have been used for
both word- and sentence-level VA prediction in
neutral positivenegative
Excited
Arousal
Valence
I
High-Arousal,
Positive-Valence
II
High-Arousal,
Negative-Valence
III
Low-Arousal,
Negative-Valence
IV
Low-Arousal,
Positive-Valence
low
high
Delighted
Happy
Content
Relaxed
CalmTired
Bored
Depressed
Tense
Angry
Frustrated
Figure 1: Two-dimensional valence-arousal space.541previous studies (Wei et al., 2011; Gökçay et al.,
2012; Malandrakis et al., 2013; Paltoglou et al.,
2013; Yu et al., 2015). In this study, we follow the
manual annotation approach to build a Chinese af-
fective lexicon and corpus in the VA dimensions.
3 Affective Resource Construction
This section describes the process of building Chi-
nese affective resources with valence-arousal rat-
ings, including the CVAW and CAVT.
The CVAW is built on the Chinese affective
lexicon C-LIWC, and then annotated with VA rat-
ings for each word. Five annotators were trained to
rate each word in the valence and arousal dimen-
sions using the Self Assessment Manikin (SAM)
model (Lang, 1980). The SAM model provides af-
fective pictures, which can help annotators in de-
termining more precise labels when rating the
words. The valence dimension uses a nine degree
scale. Values 1 and 9 respectively denote the most
negative and positive degrees of affect. Point 5
means a neutral emotion without specific tendency.
The arousal dimension uses a similar scale to de-
note calm and excitement Using this approach,
each affective word can be annotated with VA rat-
ings (determined by the average rating values pro-
vided by the annotators) to form the CVAW.
To build the CVAT, we first collected 720 web
texts from six different categories: news articles,
political discussion forums, car discussion forums,
hotel reviews, book reviews, and laptop reviews. A
total of 2,009 sentences containing the greatest
number of affective words found in the C-
LIWC lexicon were selected for VA rating. The
Google app engine was then used to implement a
crowdsourcing annotation platform using the SAM
annotation scheme. Volunteer annotators were
asked to rate individual sentences from 1 to 9 in
terms of valence and arousal. Each sentence was
rated by at least 10 annotations. Once the rating
process was finished, a corpus cleanup procedure
was performed to remove outlier ratings and im-
proper sentences (e.g., those containing abusive or
vulgar language). The outlier ratings were identi-
fied if they did not fall into the interval of the mean
plus/minus 1.5 standard deviations. They were then
excluded from the calculation of the average VA
ratings for each sentence.
4 Results
4.1 Analysis Results of CVAW
A total of 1,653 words along with the annotated
VA ratings were included in the CVAW lexicon,
yielding the (mean, standard deviation) = (4.49,
1.81) for valence and (5.48, 1.26) for arousal. To
analyze differences between the annotations, we
compared the VA values rated by each annotator
against their corresponding means across the five
annotators to calculate the error rates using the fol-
lowing metrics.
Mean Absolute Error (MAE):
1
1 | |
n
i i
i
MAE A A
n =
= −∑ ,
Root Mean Square Error (RMSE):
( ) 2
1
n
i i
i
RMSE A A n
=
= −∑ ,
where Ai denotes the valence or arousal value of
word i rated by an annotator, iA denotes the mean
valence or arousal of word i calculated over the
five annotators, and n is the total number of words
in the CVAW.
MAE RMSE
Valence Arousal Valence Arousal
Annotator A 0.4934 1.3479 0.6372 1.6411
Annotator B 0.5972 0.7821 0.7488 0.9929
Annotator C 0.5817 1.1393 0.7423 1.4302
Annotator D 0.5188 0.8226 0.6614 1.0374
Annotator E 0.6258 1.0200 0.7970 1.2700
(Mean, SD) (0.56,0.05) (1.02, 0.21) (0.72, 0.06) (1.27, 0.24)
Table 1: Analysis of error rates of different annotators for building the Chinese VA lexicon.542Table 1 shows the error rates of the annotators
in rating the VA values of words in the CVAW.
Overall, for all metrics the error rates of arousal
ratings were greater than those of valence ratings.
In addition, the annotators produced more con-
sistent error rates (around 0.49~0.63 for MAE and
0.64~0.80 for RMSE) in the valence dimension
than those (around 0.78~1.35 for MAE and
0.99~1.64 for RMSE) in the arousal dimension.
These findings indicate that the degree of arousal
was more difficult to distinguish than valence.
Figure 2 shows a scatter plot of words in the
CVAW, where each point represents the mean of
the VA values as rated by the annotators. Several
words (translated from Chinese) were marked in
the VA space for reference, e.g., victory (7.8, 7.2),
trust (7.8, 5.8), pain (2.4, 6.8), kill (1.6, 7.8), tedi-
ous (3.4, 3), fault (3.6, 4.6), agree (6.4, 4.4) and re-
laxed (6.2, 2.0).
4.2 Analysis Results of CVAT
A total of 2,009 sentences with VA ratings were
included in the CVAT corpus, yielding the (mean,
standard deviation) = (4.83, 1.37) for valence and
(5.05, 0.95) for arousal. The distribution of the six
categories and their word counts in CVAT are
shown in Table 2. The largest category was News
(27%), while the smallest one was Laptop (9%).
Figure 3 shows a scatter plot of VA ratings for all
sentences in CVAT. It is similar with the plot of
the CVAW, indicating that annotators followed
similar guidelines for rating affective words and
sentences.
Figure 2: Scatter plot of the CVAW lexicon. Figure 3: Scatter plot of the CVAT corpus.
Num. of
texts
Num. of
tokens
Avg.
tokens
Valence Arousal
MAE RMSE r MAE RMSE r
ANEW vs Forum 20 15,035 751.75 1.20 1.55 0.77 0.72 0.85 0.27
CVAW vs CVAT 2,009 70,456 35.07 1.20 1.52 0.54 1.01 1.28 0.16
Book Review 287(14%) 8,217 28.63 1.00 1.31 0.41 0.89 1.11 0.21
Car Forum 257 (13%) 12,261 47.71 1.48 1.77 0.30 0.92 1.15 0.10
Laptop Review 183 (9%) 5,374 29.37 0.95 1.21 0.55 1.07 1.40 0.04
Hotel Review 301 (15%) 7,268 24.15 1.35 1.73 0.59 0.93 1.17 0.22
News Article 542(27%) 21,923 40.45 1.11 1.40 0.61 1.11 1.40 0.17
Politics Forum 439 (22%) 15,413 35.11 1.28 1.61 0.51 1.04 1.32 0.19
Table 2: Results of using the CVAW lexicon to predict the VA ratings of the CVAT corpus.5434.3 Results of Using CVAW to Predict the VA
Ratings of CVAT
To demonstrate the application of the constructed
affective resources, this experiment adopted a sim-
ple aggregate-and-average method (Taboada et al.
2011) to predict the VA ratings of the CVAT cor-
pus using CVAW words. In this approach, the va-
lence (or arousal) rating of a given sentence was
calculated by averaging the valence (or arousal)
ratings of the words matched in the CVAW in that
sentence. Once the predicted values of the VA rat-
ings for the sentences were obtained, they were
compared to the corresponding actual values in the
CVAT to calculate MAE, RMSE and Pearson cor-
relation coefficient r, as shown in Table 2. Notice
that the sentences which contain no affective
words in the CVAW were not included for perfor-
mance calculation (herein 30 sentences). The re-
sults using ANEW to predict the VA rating of 20
English forum discussions were also included for
comparison (Paltoglou et al., 2013).
The results show that the average tokens of the
CVAT sentences are around 35 which is much
smaller than those of the English forum discus-
sions (long texts). Both English and Chinese re-
sources had a similar error rates (MAE and RMSE)
for valence, while the English resource outper-
formed the Chinese resource in terms of arousal
rates. In addition, both the English and Chinese re-
sources had a lower correlation for arousal than for
valence, indicating again that the arousal dimen-
sion is more difficult to predict. Table 2 also shows
the performance for each category in CVAT. For
valence, Laptop achieved the lowest error rate,
while News and Hotel had a higher correlation.
The respective ranges of MAE, RMSE and r are
0.95~1.48, 1.21~1.77 and 0.30~0.61. For arousal,
Book yielded the lowest error rate, while Hotel and
Book yielded a better correlation. The respective
ranges of MAE, RMSE and r are 0.89~1.11,
1.11~1.40 and 0.04~0.22.
5 Conclusions and Future Work
This study presents a Chinese affective lexicon
with 1,653 words and a corpus of 2,009 sentences
with six different categories, both annotated with
valence-arousal values. A corpus cleanup proce-
dure was used to remove outlier ratings and im-
proper texts to improve quality. Experimental re-
sults provided a feasibility evaluation and baseline
performance for VA prediction using the con-
structed resources. Future work will focus on
building useful dimensional sentiment applications
based on the constructed resources.
Acknowledgments
This work was supported by the Ministry of Sci-
ence and Technology, Taiwan, ROC, under Grant
No. NSC102-2221-E-155-029-MY3. The authors
would like to thank the anonymous reviewers and
the area chairs for their constructive comments.







No comments:
Post a Comment