The encoder-decoder architecture for recurrent neural networks is achieving state-of-the-art results on standard machine translation benchmarks and is being used in the heart of industrial translation services.
The model is simple, but given the large amount of data required to train it, tuning the myriad of design decisions in the model in order get top performance on your problem can be practically intractable. Thankfully, research scientists have used Google-scale hardware to do this work for us and provide a set of heuristics for how to configure the encoder-decoder model for neural machine translation and for sequence prediction generally.
In this post, you will discover the details of how to best configure an encoder-decoder recurrent neural network for neural machine translation and other natural language processing tasks.
After reading this post, you will know:
- The Google study that investigated each model design decision in the encoder-decoder model to isolate their effects.
- The results and recommendations for design decisions like word embeddings, encoder and decoder depth, and attention mechanisms.
- A set of base model design decisions that can be used as a starting point on your own sequence-to-sequence projects.
Kick-start your project with my new book Deep Learning for Natural Language Processing, including step-by-step tutorials and the Python source code files for all examples.
Let’s get started.

How to Configure an Encoder-Decoder Model for Neural Machine Translation
Photo by Sporting Park, some rights reserved.
Encoder-Decoder Model for Neural Machine Translation
The Encoder-Decoder architecture for recurrent neural networks is displacing classical phrase-based statistical machine translation systems for state-of-the-art results.
As evidence, by their 2016 paper “Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation,” Google now uses the approach in their core of their Google Translate service.
A problem with this architecture is that the models are large, in turn requiring very large datasets on which to train. This has the effect of model training taking days or weeks and requiring computational resources that are generally very expensive. As such, little work has been done on the impact of different design choices on the model and their impact on model skill.
This problem is addressed explicitly by Denny Britz, et al. in their 2017 paper “Massive Exploration of Neural Machine Translation Architectures.” In the paper, they design a baseline model for a standard English-to-German translation task and enumerate a suite of different model design choices and describe their impact on the skill of the model. They claim that the complete set of experiments consumed more than 250,000 GPU compute hours, which is impressive, to say the least.
We report empirical results and variance numbers for several hundred experimental runs, corresponding to over 250,000 GPU hours on the standard WMT English to German translation task. Our experiments lead to novel insights and practical advice for building and extending NMT architectures.
In this post, we will look at some of the findings from this paper that we can use to tune our own neural machine translation models, as well as sequence-to-sequence models in general.
For more background on the Encoder-Decoder architecture and the attention mechanism, see the posts:
- Encoder-Decoder Long Short-Term Memory Networks
- Attention in Long Short-Term Memory Recurrent Neural Networks
Need help with Deep Learning for Text Data?
Take my free 7-day email crash course now (with code).
Click to sign-up and also get a free PDF Ebook version of the course.
Baseline Model
We can start-off by describing the baseline model used as the starting point for all experiments.
A baseline model configuration was chosen such that the model would perform reasonably well on the translation task.
- Embedding: 512-dimensions
- RNN Cell: Gated Recurrent Unit or GRU
- Encoder: Bidirectional
- Encoder Depth: 2-layers (1 layer in each direction)
- Decoder Depth: 2-layers
- Attention: Bahdanau-style
- Optimizer: Adam
- Dropout: 20% on input
Each experiment started with the baseline model and varied one element in an attempt to isolate the impact of the design decision on the model skill, in this case, BLEU scores.
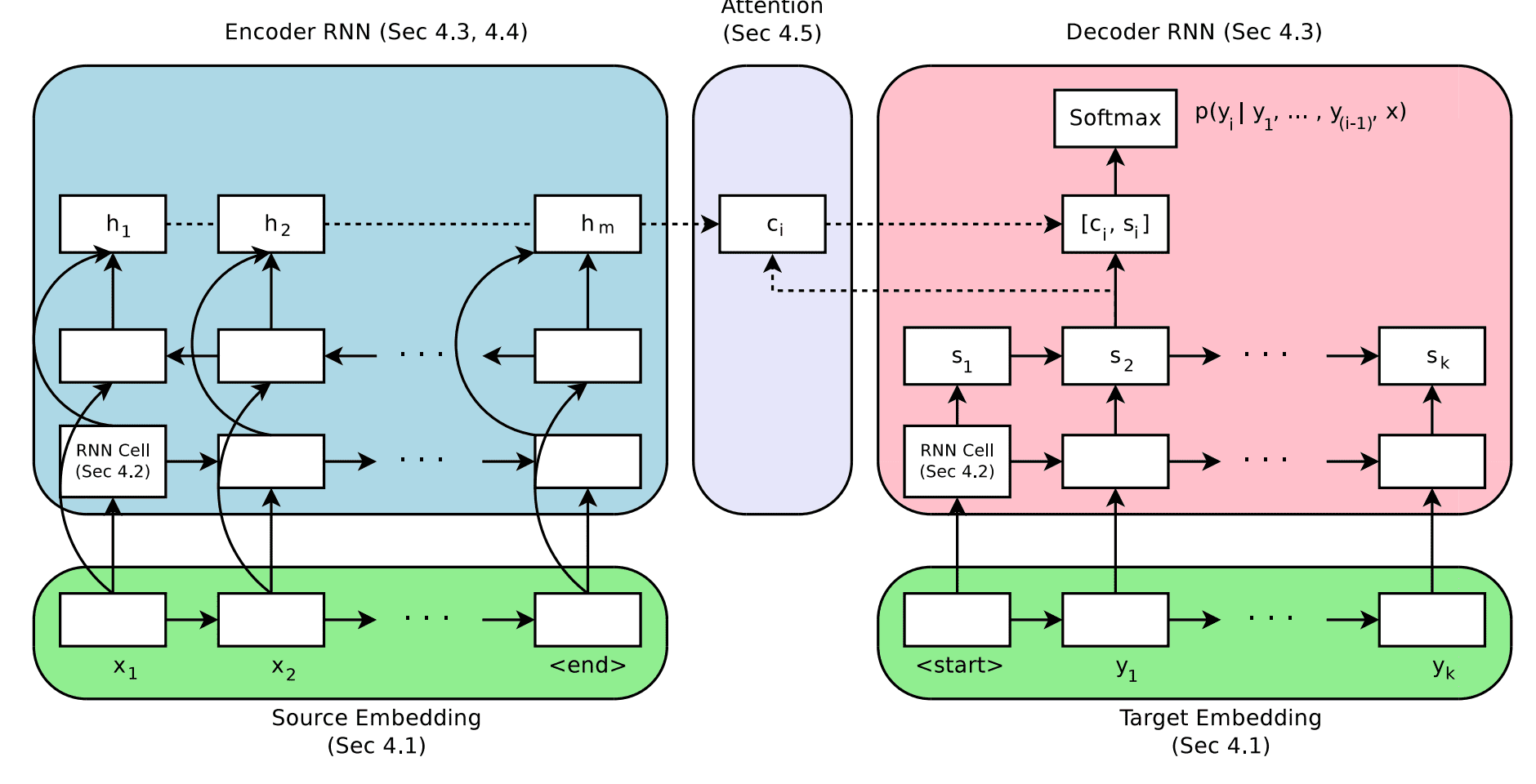
Encoder-Decoder Architecture for Neural Machine Translation
Taken from “Massive Exploration of Neural Machine Translation Architectures.”
Embedding Size
A word-embedding is used to represent words input to the encoder.
This is a distributed representation where each word is mapped to a fixed-sized vector of continuous values. The benefit of this approach is that different words with similar meaning will have a similar representation.
This distributed representation is often learned while fitting the model on the training data. The embedding size defines the length of the vectors used to represent words. It is generally believed that a larger dimensionality will result in a more expressive representation, and in turn, better skill.
Interestingly, the results show that the largest size tested did achieve the best results, but the benefit of increasing the size was minor overall.
[results show] that 2048-dimensional embeddings yielded the overall best result, they only did so by a small margin. Even small 128-dimensional embeddings performed surprisingly well, while converging almost twice as quickly.
Recommendation: Start with a small embedding, such as 128, perhaps increase the size later for a minor lift in skill.
RNN Cell Type
There are generally three types of recurrent neural network cells that are commonly used:
- Simple RNN.
- Long Short-Term Memory or LSTM.
- Gated Recurrent Unit or GRU.
The LSTM was developed to address the vanishing gradient problem of the Simple RNN that limited the training of deep RNNs. The GRU was developed in an attempt to simplify the LSTM.
Results showed that both the GRU and LSTM were significantly better than the Simple RNN, but the LSTM was generally better overall.
In our experiments, LSTM cells consistently outperformed GRU cells
Recommendation: Use LSTM RNN units in your model.
Encoder-Decoder Depth
Generally, deeper networks are believed to achieve better performance than shallow networks.
The key is to find a balance between network depth, model skill, and training time. This is because we generally do not have infinite resources to train very deep networks if the benefit to skill is minor.
The authors explore the depth of both the encoder and decoder models and the impact on model skill.
When it comes to encoders, it was found that depth did not have a dramatic impact on skill and more surprisingly, a 1-layer unidirectional model performs only slightly worse than a 4-layer unidirectional configuration. A two-layer bidirectional encoder performed slightly better than other configurations tested.
We found no clear evidence that encoder depth beyond two layers is necessary.
Recommendation: Use a 1-layer bidirectional encoder and extend to 2 bidirectional layers for a small lift in skill.
A similar story was seen when it came to decoders. The skill between decoders with 1, 2, and 4 layers was different by a small amount where a 4-layer decoder was slightly better. An 8-layer decoder did not converge under the test conditions.
On the decoder side, deeper models outperformed shallower ones by a small margin.
Recommendation: Use a 1-layer decoder as a starting point and use a 4-layer decoder for better results.
Direction of Encoder Input
The order of the sequence of source text can be provided to the encoder a number of ways:
- Forward or as-normal.
- Reversed.
- Both forward and reversed at the same time.
The authors explored the impact of the order of the input sequence on model skill comparing various unidirectional and bidirectional configurations.
Generally, they confirmed previous findings that a reversed sequence is better than a forward sequence and that bidirectional is slightly better than a reversed sequence.
… bidirectional encoders generally outperform unidirectional encoders, but not by a large margin. The encoders with reversed source consistently outperform their non-reversed counterparts.
Recommendation: Use a reversed order input sequence or move to bidirectional for a small lift in model skill.
Attention Mechanism
A problem with the naive Encoder-Decoder model is that the encoder maps the input to a fixed-length internal representation from which the decoder must produce the entire output sequence.
Attention is an improvement to the model that allows the decoder to “pay attention” to different words in the input sequence as it outputs each word in the output sequence.
The authors look at a few variations on simple attention mechanisms. The results show that having attention results in dramatically better performance than not having attention.
While we did expect the attention-based models to significantly outperform those without an attention mechanism, we were surprised by just how poorly the [no attention] models fared.
The simple weighted average style attention described by Bahdanau, et al. in their 2015 paper “Neural machine translation by jointly learning to align and translate” was found to perform the best.
Recommendation: Use attention and prefer the Bahdanau-style weighted average style attention.
Inference
It is common in neural machine translation systems to use a beam-search to sample the probabilities for the words in the sequence output by the model.
The wider the beam width, the more exhaustive the search, and, it is believed, the better the results.
The results showed that a modest beam-width of 3-5 performed the best, which could be improved only very slightly through the use of length penalties. The authors generally recommend tuning the beam width on each specific problem.
We found that a well-tuned beam search is crucial to achieving good results, and that it leads to consistent gains of more than one BLEU point.
Recommendation: Start with a greedy search (beam=1) and tune based on your problem.
Final Model
The authors pull together their findings into a single “best model” and compare the results of this model to other well-performing models and state-of-the-art results.
The specific configurations of this model are summarized in the table below, taken from the paper. These parameters may be taken as a good or best starting point when developing your own encoder-decoder model for an NLP application.

Summary of Model Configuration for the Final NMT Model
Taken from “Massive Exploration of Neural Machine Translation Architectures.”
The results of the system were shown to be impressive and achieve skill close to state-of-the-art with a simpler model, which was not the goal of the paper.
… we do show that through careful hyperparameter tuning and good initialization, it is possible to achieve state-of-the-art performance on standard WMT benchmarks
Importantly, the authors provide all of their code as an open source project called tf-seq2seq. Because two of the authors were members of the Google Brain residency program, their work was announced on the Google Research blog with the title “Introducing tf-seq2seq: An Open Source Sequence-to-Sequence Framework in TensorFlow“, 2017.
Further Reading
This section provides more resources on the topic if you are looking to go deeper.
- Massive Exploration of Neural Machine Translation Architectures, 2017.
- Denny Britz Homepage
- WildML Blog
- Introducing tf-seq2seq: An Open Source Sequence-to-Sequence Framework in TensorFlow, 2017.
- tf-seq2seq: A general-purpose encoder-decoder framework for Tensorflow
- tf-seq2seq Project Documentation
- tf-seq2seq Tutorial: Neural Machine Translation Background
- Neural machine translation by jointly learning to align and translate, 2015.
Summary
In this post, you discovered how to best configure an encoder-decoder recurrent neural network for neural machine translation and other natural language processing tasks.
Specifically, you learned:
- The Google study that investigated each model design decision in the encoder-decoder model to isolate their effects.
- The results and recommendations for design decisions like word embeddings, encoder and decoder depth, and attention mechanisms.
- A set of base model design decisioning that can be used as a starting point on your own sequence to sequence projects.
Do you have any questions?
Ask your questions in the comments below and I will do my best to answer.





No comments:
Post a Comment