Text summarization is a problem in natural language processing of creating a short, accurate, and fluent summary of a source document.
The Encoder-Decoder recurrent neural network architecture developed for machine translation has proven effective when applied to the problem of text summarization.
It can be difficult to apply this architecture in the Keras deep learning library, given some of the flexibility sacrificed to make the library clean, simple, and easy to use.
In this tutorial, you will discover how to implement the Encoder-Decoder architecture for text summarization in Keras.
After completing this tutorial, you will know:
- How text summarization can be addressed using the Encoder-Decoder recurrent neural network architecture.
- How different encoders and decoders can be implemented for the problem.
- Three models that you can use to implemented the architecture for text summarization in Keras.
Kick-start your project with my new book Deep Learning for Natural Language Processing, including step-by-step tutorials and the Python source code files for all examples.
Let’s get started.

Encoder-Decoder Models for Text Summarization in Keras
Photo by Diogo Freire, some rights reserved.
Tutorial Overview
This tutorial is divided into 5 parts; they are:
- Encoder-Decoder Architecture
- Text Summarization Encoders
- Text Summarization Decoders
- Reading Source Text
- Implementation Models
Need help with Deep Learning for Text Data?
Take my free 7-day email crash course now (with code).
Click to sign-up and also get a free PDF Ebook version of the course.
Encoder-Decoder Architecture
The Encoder-Decoder architecture is a way of organizing recurrent neural networks for sequence prediction problems that have a variable number of inputs, outputs, or both inputs and outputs.
The architecture involves two components: an encoder and a decoder.
- Encoder: The encoder reads the entire input sequence and encodes it into an internal representation, often a fixed-length vector called the context vector.
- Decoder: The decoder reads the encoded input sequence from the encoder and generates the output sequence.
For more about the Encoder-Decoder architecture, see the post:
Both the encoder and the decoder submodels are trained jointly, meaning at the same time.
This is quite a feat as traditionally, challenging natural language problems required the development of separate models that were later strung into a pipeline, allowing error to accumulate during the sequence generation process.
The entire encoded input is used as context for generating each step in the output. Although this works, the fixed-length encoding of the input limits the length of output sequences that can be generated.
An extension of the Encoder-Decoder architecture is to provide a more expressive form of the encoded input sequence and allow the decoder to learn where to pay attention to the encoded input when generating each step of the output sequence.
This extension of the architecture is called attention.
For more about Attention in the Encoder-Decoder architecture, see the post:
The Encoder-Decoder architecture with attention is popular for a suite of natural language processing problems that generate variable length output sequences, such as text summarization.
The application of architecture to text summarization is as follows:
- Encoder: The encoder is responsible for reading the source document and encoding it to an internal representation.
- Decoder: The decoder is a language model responsible for generating each word in the output summary using the encoded representation of the source document.
Text Summarization Encoders
The encoder is where the complexity of the model resides as it is responsible for capturing the meaning of the source document.
Different types of encoders can be used, although more commonly bidirectional recurrent neural networks, such as LSTMs, are used. In cases where recurrent neural networks are used in the encoder, a word embedding is used to provide a distributed representation of words.
Alexander Rush, et al. uses a simple bag-of-words encoder that discards word order and convolutional encoders that explicitly try to capture n-grams.
Our most basic model simply uses the bag-of-words of the input sentence embedded down to size H, while ignoring properties of the original order or relationships between neighboring words. […] To address some of the modelling issues with bag-of-words we also consider using a deep convolutional encoder for the input sentence.
— A Neural Attention Model for Abstractive Sentence Summarization, 2015.
Konstantin Lopyrev uses a deep stack of 4 LSTM recurrent neural networks as the encoder.
The encoder is fed as input the text of a news article one word of a time. Each word is first passed through an embedding layer that transforms the word into a distributed representation. That distributed representation is then combined using a multi-layer neural network
— Generating News Headlines with Recurrent Neural Networks, 2015.
Abigail See, et al. use a single-layer bidirectional LSTM as the encoder.
The tokens of the article w(i) are fed one-by-one into the encoder (a single-layer bidirectional LSTM), producing a sequence of encoder hidden states h(i).
— Get To The Point: Summarization with Pointer-Generator Networks, 2017.
Ramesh Nallapati, et al. use bidirectional GRU recurrent neural networks in their encoders and incorporate additional information about each word in the input sequence.
The encoder consists of a bidirectional GRU-RNN…
— Abstractive Text Summarization Using Sequence-to-Sequence RNNs and Beyond, 2016.
Text Summarization Decoders
The decoder must generate each word in the output sequence given two sources of information:
- Context Vector: The encoded representation of the source document provided by the encoder.
- Generated Sequence: The word or sequence of words already generated as a summary.
The context vector may be a fixed-length encoding as in the simple Encoder-Decoder architecture, or may be a more expressive form filtered via an attention mechanism.
The generated sequence is provided with little preparation, such as distributed representation of each generated word via a word embedding.
On each step t, the decoder (a single-layer unidirectional LSTM) receives the word embedding of the previous word (while training, this is the previous word of the reference summary; at test time it is the previous word emitted by the decoder)
— Get To The Point: Summarization with Pointer-Generator Networks, 2017.
Alexander Rush, et al. show this cleanly in a diagram where x is the source document, enc is the encoder providing internal representation of the source document, and yc is the sequence of previously generated words.
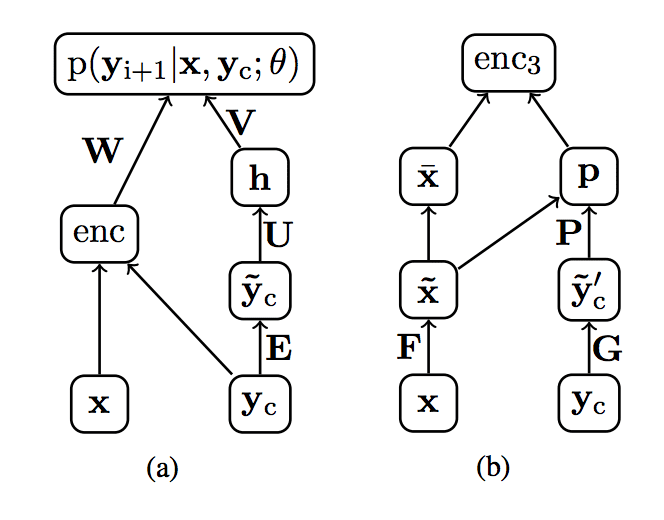
Example of inputs to the decoder for text summarization.
Taken from “A Neural Attention Model for Abstractive Sentence Summarization”, 2015.
Generating words one at a time requires that the model be run until some maximum number of summary words are generated or a special end-of-sequence token is reached.
The process must be started by providing the model with a special start-of-sequence token in order to generate the first word.
The decoder takes as input the hidden layers generated after feeding in the last word of the input text. First, an end-of-sequence symbol is fed in as input, again using an embedding layer to transform the symbol into a distributed representation. […]. After generating each word that same word is fed in as input when generating the next word.
— Generating News Headlines with Recurrent Neural Networks, 2015.
Ramesh Nallapati, et al. generate the output sequence using a GRU recurrent neural network.
… the decoder consists of a uni-directional GRU-RNN with the same hidden-state size as that of the encoder
Reading Source Text
There is flexibility in the application of this architecture depending on the specific text summarization problem being addressed.
Most studies focus on one or just a few source sentences in the encoder, but this does not have to be the case.
For example, the encoder could be configured to read and encode the source document in different sized chunks:
- Sentence.
- Paragraph.
- Page.
- Document.
Equally, the decoder can be configured to summarize each chunk or aggregate the encoded chunks and output a broader summary.
Some work has been done along this path, where Alexander Rush, et al. use a hierarchical encoder model with attention at both the word and the sentence level.
This model aims to capture this notion of two levels of importance using two bi-directional RNNs on the source side, one at the word level and the other at the sentence level. The attention mechanism operates at both levels simultaneously
— A Neural Attention Model for Abstractive Sentence Summarization, 2015.
Implementation Models
In this section, we will look at how to implement the Encoder-Decoder architecture for text summarization in the Keras deep learning library.
General Model
A simple realization of the model involves an Encoder with an Embedding input followed by an LSTM hidden layer that produces a fixed-length representation of the source document.
The Decoder reads the representation and an Embedding of the last generated word and uses these inputs to generate each word in the output summary.
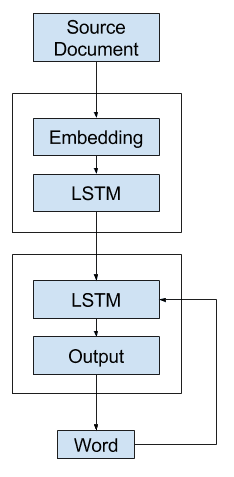
General Text Summarization Model in Keras
There is a problem.
Keras does not allow recursive loops where the output of the model is fed as input to the model automatically.
This means the model as described above cannot be directly implemented in Keras (but perhaps could in a more flexible platform like TensorFlow).
Instead, we will look at three variations of the model that we can implement in Keras.
Alternate 1: One-Shot Model
The first alternative model is to generate the entire output sequence in a one-shot manner.
That is, the decoder uses the context vector alone to generate the output sequence.
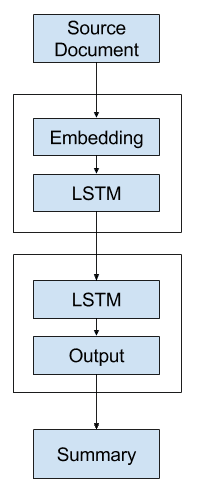
Alternate 1 – One-Shot Text Summarization Model
Here is some sample code for this approach in Keras using the functional API.
This model puts a heavy burden on the decoder.
It is likely that the decoder will not have sufficient context for generating a coherent output sequence as it must choose the words and their order.
Alternate 2: Recursive Model A
A second alternative model is to develop a model that generates a single word forecast and call it recursively.
That is, the decoder uses the context vector and the distributed representation of all words generated so far as input in order to generate the next word.
A language model can be used to interpret the sequence of words generated so far to provide a second context vector to combine with the representation of the source document in order to generate the next word in the sequence.
The summary is built up by recursively calling the model with the previously generated word appended (or, more specifically, the expected previous word during training).
The context vectors could be concentrated or added together to provide a broader context for the decoder to interpret and output the next word.
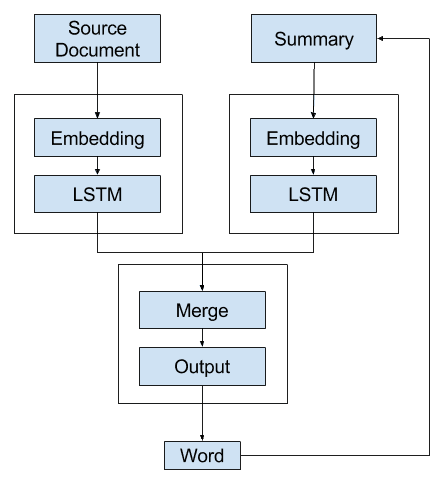
Alternate 2 – Recursive Text Summarization Model A
Here is some sample code for this approach in Keras using the functional API.
This is better as the decoder is given an opportunity to use the previously generated words and the source document as a context for generating the next word.
It does put a burden on the merge operation and decoder to interpret where it is up to in generating the output sequence.
Alternate 3: Recursive Model B
In this third alternative, the Encoder generates a context vector representation of the source document.
This document is fed to the decoder at each step of the generated output sequence. This allows the decoder to build up the same internal state as was used to generate the words in the output sequence so that it is primed to generate the next word in the sequence.
This process is then repeated by calling the model again and again for each word in the output sequence until a maximum length or end-of-sequence token is generated.
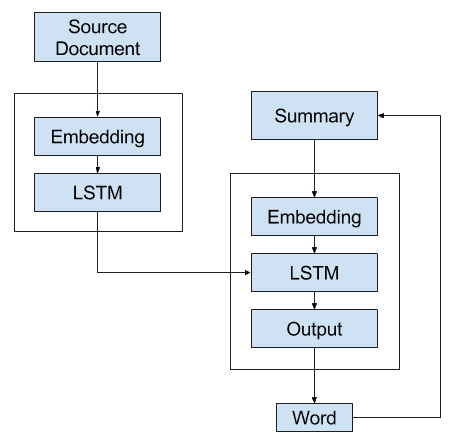
Alternate 3 – Recursive Text Summarization Model B
Here is some sample code for this approach in Keras using the functional API.
Do you have any other alternate implementation ideas?
Let me know in the comments below.
Further Reading
This section provides more resources on the topic if you are looking go deeper.
Papers
- A Neural Attention Model for Abstractive Sentence Summarization, 2015.
- Generating News Headlines with Recurrent Neural Networks, 2015.
- Abstractive Text Summarization Using Sequence-to-Sequence RNNs and Beyond, 2016.
- Get To The Point: Summarization with Pointer-Generator Networks, 2017.
Related
- Encoder-Decoder Long Short-Term Memory Networks
- Attention in Long Short-Term Memory Recurrent Neural Networks
Summary
In this tutorial, you discovered how to implement the Encoder-Decoder architecture for text summarization in the Keras deep learning library.
Specifically, you learned:
- How text summarization can be addressed using the Encoder-Decoder recurrent neural network architecture.
- How different encoders and decoders can be implemented for the problem.
- Three models that you can use to implement the architecture for text summarization in Keras.
Do you have any questions?
Ask your questions in the comments below and I will do my best to answer.





No comments:
Post a Comment