It can be hard to prepare data when you’re just getting started with deep learning.
Long Short-Term Memory, or LSTM, recurrent neural networks expect three-dimensional input in the Keras Python deep learning library.
If you have a long sequence of thousands of observations in your time series data, you must split your time series into samples and then reshape it for your LSTM model.
In this tutorial, you will discover exactly how to prepare your univariate time series data for an LSTM model in Python with Keras.
Kick-start your project with my new book Deep Learning for Time Series Forecasting, including step-by-step tutorials and the Python source code files for all examples.
Let’s get started.

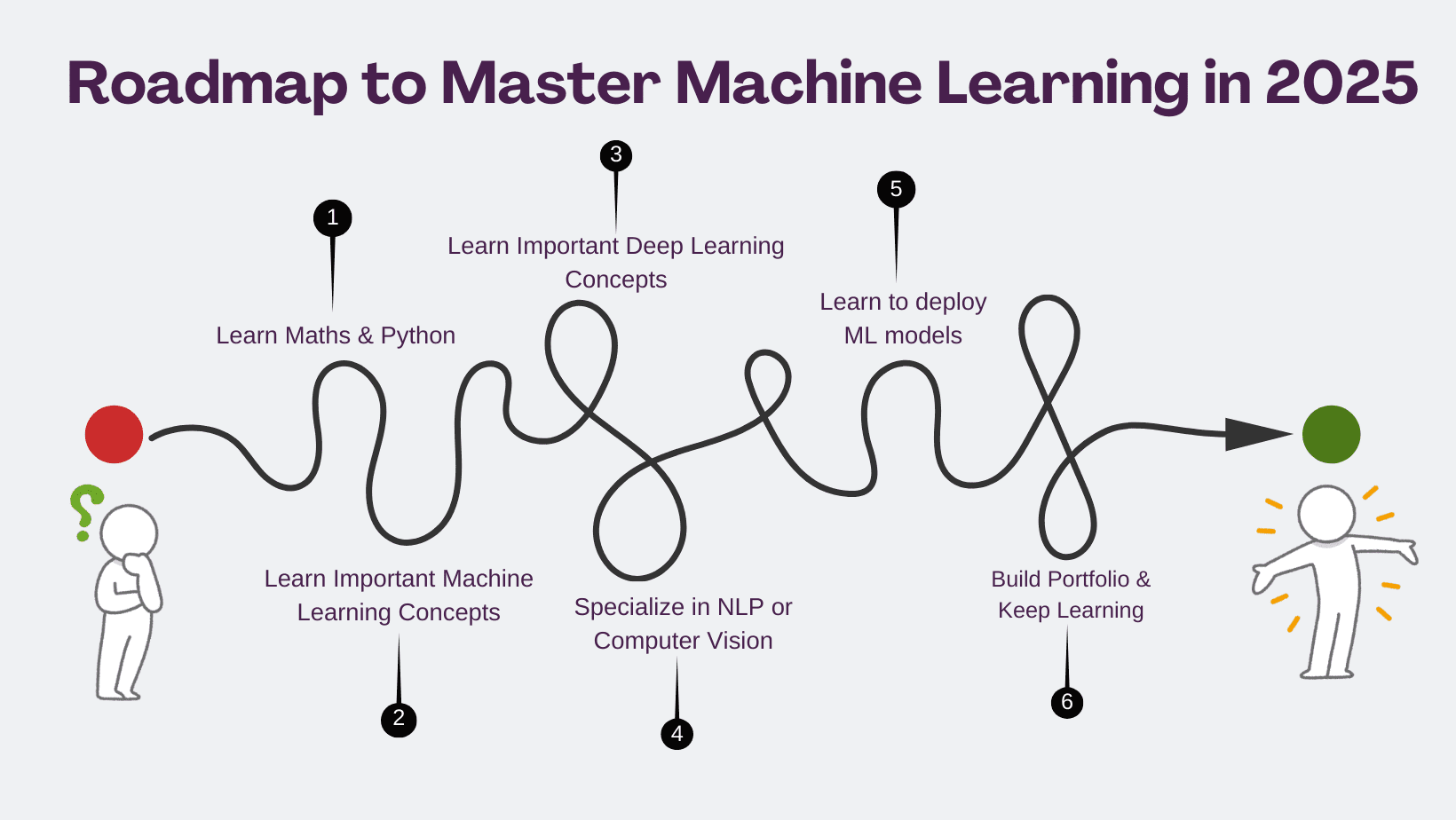
How to Prepare Univariate Time Series Data for Long Short-Term Memory Networks
Photo by Miguel Mendez, some rights reserved.
How to Prepare Time Series Data
Perhaps the most common question I get is how to prepare time series data for supervised learning.
I have written a few posts on the topic, such as:
- How to Convert a Time Series to a Supervised Learning Problem in Python
- Time Series Forecasting as Supervised Learning
But, these posts don’t help everyone.
I recently got this email:
I have two columns in my data file with 5000 rows, column 1 is time (with 1 hour interval) and column 2 is bits/sec and I am trying to forecast bits/sec. In that case can you please help me to set sample, time step and feature [for LSTMs]?
There are few problems here:
- LSTMs expect 3D input, and it can be challenging to get your head around this the first time.
- LSTMs don’t like sequences of more than 200-400 time steps, so the data will need to be split into samples.
In this tutorial, we will use this question as the basis for showing one way to specifically prepare data for the LSTM network in Keras.
Need help with Deep Learning for Time Series?
Take my free 7-day email crash course now (with sample code).
Click to sign-up and also get a free PDF Ebook version of the course.
1. Load the Data
I assume you know how to load the data as a Pandas Series or DataFrame.
If not, see these posts:
Here, we will mock loading by defining a new dataset in memory with 5,000 time steps.
Running this piece both prints the first 5 rows of data and the shape of the loaded data.
We can see we have 5,000 rows and 2 columns: a standard univariate time series dataset.
2. Drop Time
If your time series data is uniform over time and there is no missing values, we can drop the time column.
If not, you may want to look at imputing the missing values, resampling the data to a new time scale, or developing a model that can handle missing values. See posts like:
- How to Handle Missing Timesteps in Sequence Prediction Problems with Python
- How to Handle Missing Data with Python
- How To Resample and Interpolate Your Time Series Data With Python
Here, we just drop the first column:
Now we have an array of 5,000 values.
3. Split Into Samples
LSTMs need to process samples where each sample is a single time series.
In this case, 5,000 time steps is too long; LSTMs work better with 200-to-400 time steps based on some papers I’ve read. Therefore, we need to split the 5,000 time steps into multiple shorter sub-sequences.
I write more about splitting up long sequences here:
- How to Handle Very Long Sequences with Long Short-Term Memory Recurrent Neural Networks
- How to Prepare Sequence Prediction for Truncated Backpropagation Through Time in Keras
There are many ways to do this, and you may want to explore some depending on your problem.
For example, perhaps you need overlapping sequences, perhaps non-overlapping is good but your model needs state across the sub-sequences and so on.
Here, we will split the 5,000 time steps into 25 sub-sequences of 200 time steps each. Rather than using NumPy or Python tricks, we will do this the old fashioned way so you can see what is going on.
We now have 25 sub sequences of 200 time steps each.
If you’d prefer to do this in a one liner, go for it. I’d love to see what you can come up with.
Post your approach in the comments below.
4. Reshape Subsequences
The LSTM needs data with the format of [samples, time steps and features].
Here, we have 25 samples, 200 time steps per sample, and 1 feature.
First, we need to convert our list of arrays into a 2D NumPy array of 25 x 200.
Running this piece, you should see:
Next, we can use the reshape() function to add one additional dimension for our single feature.
And that is it.
The data can now be used as an input (X) to an LSTM model.
Further Reading
This section provides more resources on the topic if you are looking to go deeper.
Related Posts
- How to Convert a Time Series to a Supervised Learning Problem in Python
- Time Series Forecasting as Supervised Learning
- How to Load and Explore Time Series Data in Python
- How To Load Machine Learning Data in Python
- How to Handle Missing Timesteps in Sequence Prediction Problems with Python
- How to Handle Missing Data with Python
- How To Resample and Interpolate Your Time Series Data With Python
- How to Handle Very Long Sequences with Long Short-Term Memory Recurrent Neural Networks
- How to Prepare Sequence Prediction for Truncated Backpropagation Through Time in Keras
API
Summary
In this tutorial, you discovered how to convert your long univariate time series data into a form that you can use to train an LSTM model in Python.
Did this post help? Do you have any questions?
Let me know in the comments below.