It can be difficult to determine whether your Long Short-Term Memory model is performing well on your sequence prediction problem.
You may be getting a good model skill score, but it is important to know whether your model is a good fit for your data or if it is underfit or overfit and could do better with a different configuration.
In this tutorial, you will discover how you can diagnose the fit of your LSTM model on your sequence prediction problem.
After completing this tutorial, you will know:
- How to gather and plot training history of LSTM models.
- How to diagnose an underfit, good fit, and overfit model.
- How to develop more robust diagnostics by averaging multiple model runs.
1. Training History in Keras
You can learn a lot about the behavior of your model by reviewing its performance over time.
LSTM models are trained by calling the fit() function. This function returns a variable called history that contains a trace of the loss and any other metrics specified during the compilation of the model. These scores are recorded at the end of each epoch.
For example, if your model was compiled to optimize the log loss (binary_crossentropy) and measure accuracy each epoch, then the log loss and accuracy will be calculated and recorded in the history trace for each training epoch.
Each score is accessed by a key in the history object returned from calling fit(). By default, the loss optimized when fitting the model is called “loss” and accuracy is called “acc“.
Keras also allows you to specify a separate validation dataset while fitting your model that can also be evaluated using the same loss and metrics.
This can be done by setting the validation_split argument on fit() to use a portion of the training data as a validation dataset.
This can also be done by setting the validation_data argument and passing a tuple of X and y datasets.
The metrics evaluated on the validation dataset are keyed using the same names, with a “val_” prefix.
2. Diagnostic Plots
The training history of your LSTM models can be used to diagnose the behavior of your model.
You can plot the performance of your model using the Matplotlib library. For example, you can plot training loss vs test loss as follows:
Creating and reviewing these plots can help to inform you about possible new configurations to try in order to get better performance from your model.
Next, we will look at some examples. We will consider model skill on the train and validation sets in terms of loss that is minimized. You can use any metric that is meaningful on your problem.
3. Underfit Example
An underfit model is one that is demonstrated to perform well on the training dataset and poor on the test dataset.
This can be diagnosed from a plot where the training loss is lower than the validation loss, and the validation loss has a trend that suggests further improvements are possible.
A small contrived example of an underfit LSTM model is provided below.
Running this example produces a plot of train and validation loss showing the characteristic of an underfit model. In this case, performance may be improved by increasing the number of training epochs.
In this case, performance may be improved by increasing the number of training epochs.
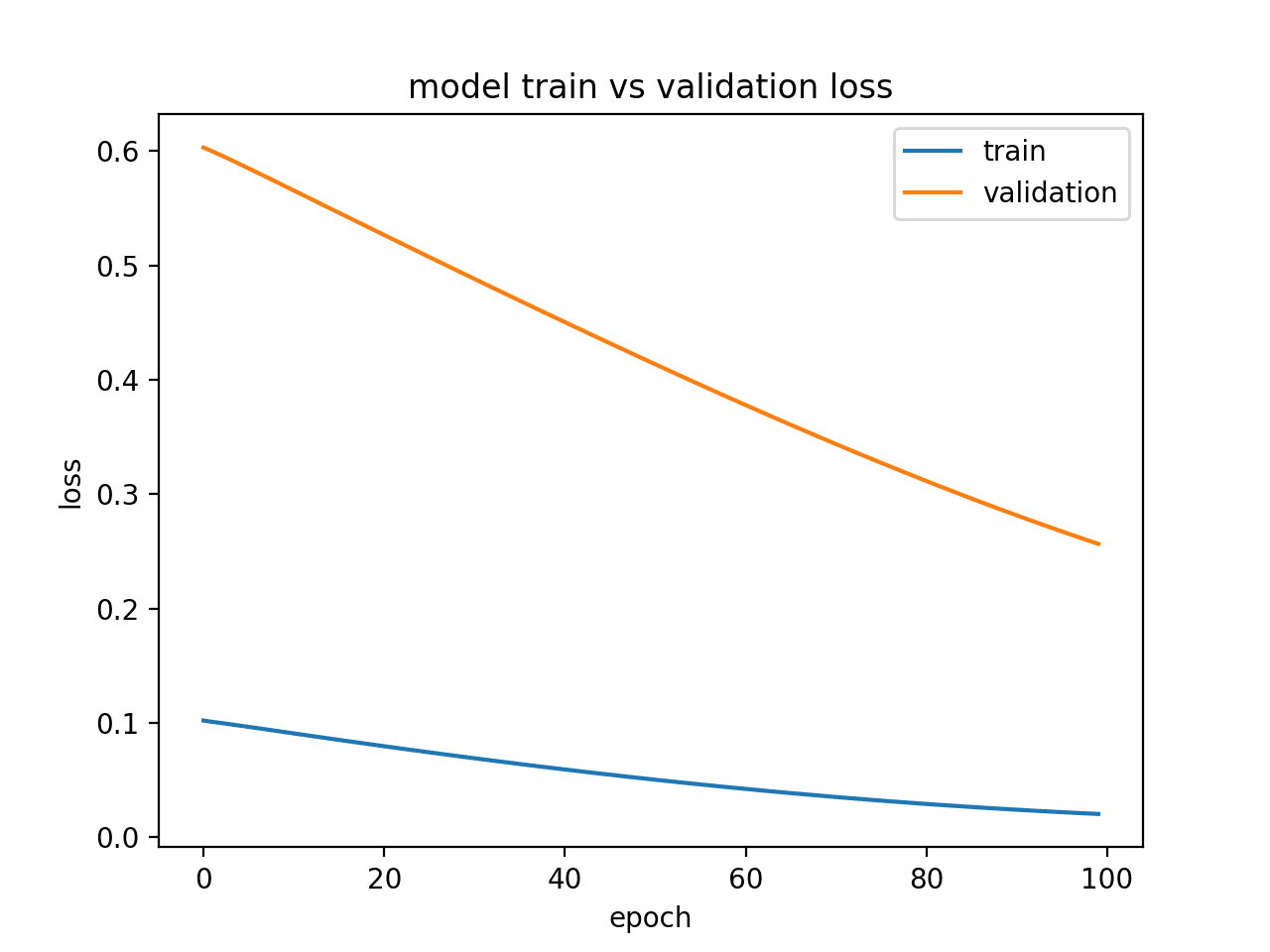
Diagnostic Line Plot Showing an Underfit Model
Alternately, a model may be underfit if performance on the training set is better than the validation set and performance has leveled off. Below is an example of an
Below is an example of an an underfit model with insufficient memory cells.
Running this example shows the characteristic of an underfit model that appears under-provisioned.
In this case, performance may be improved by increasing the capacity of the model, such as the number of memory cells in a hidden layer or number of hidden layers.
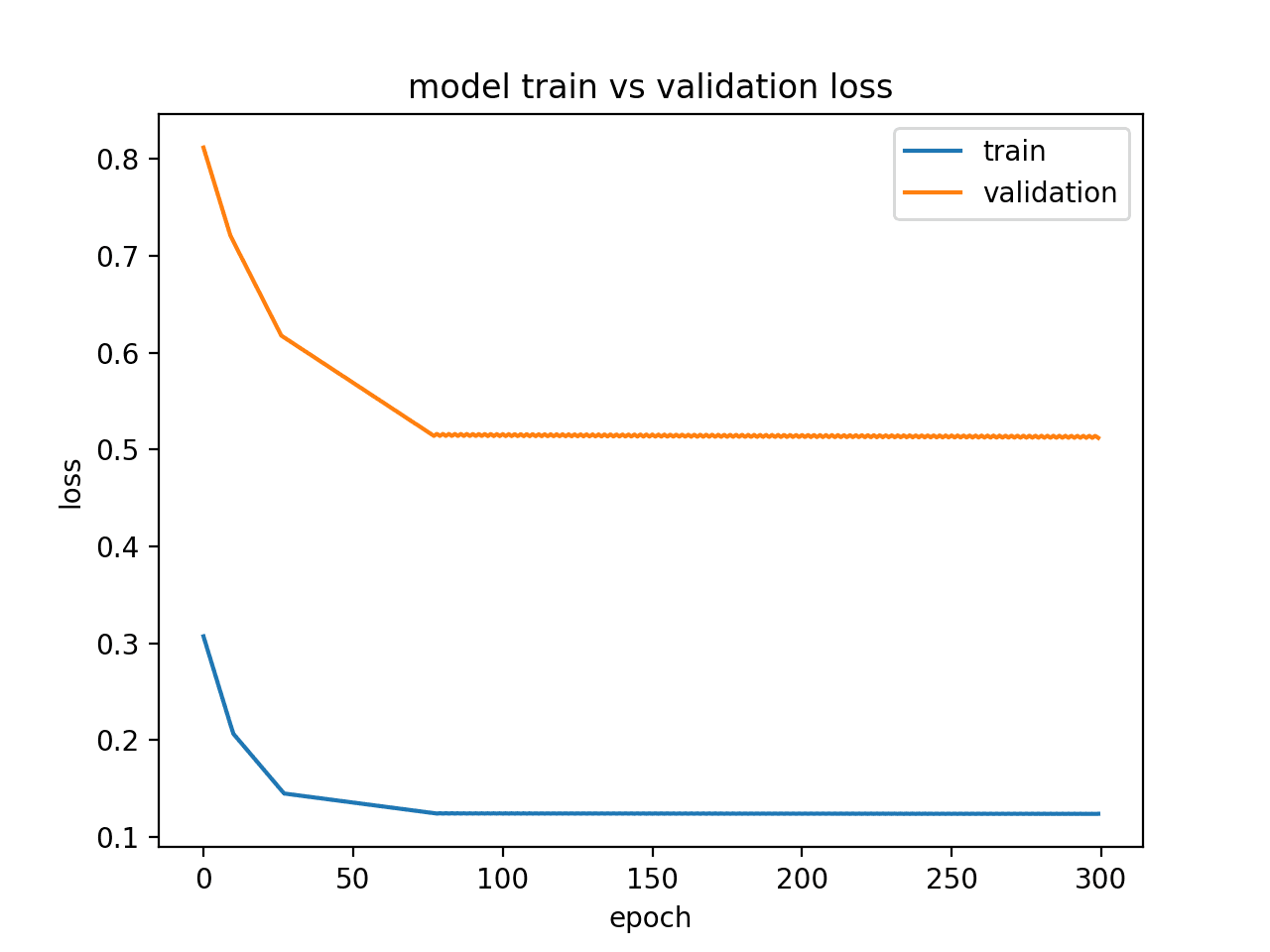
Diagnostic Line Plot Showing an Underfit Model via Status
4. Good Fit Example
A good fit is a case where the performance of the model is good on both the train and validation sets.
This can be diagnosed from a plot where the train and validation loss decrease and stabilize around the same point.
The small example below demonstrates an LSTM model with a good fit.
Running the example creates a line plot showing the train and validation loss meeting.
Ideally, we would like to see model performance like this if possible, although this may not be possible on challenging problems with a lot of data.

Diagnostic Line Plot Showing a Good Fit for a Model
5. Overfit Example
An overfit model is one where performance on the train set is good and continues to improve, whereas performance on the validation set improves to a point and then begins to degrade.
This can be diagnosed from a plot where the train loss slopes down and the validation loss slopes down, hits an inflection point, and starts to slope up again.
The example below demonstrates an overfit LSTM model.
Running this example creates a plot showing the characteristic inflection point in validation loss of an overfit model.
This may be a sign of too many training epochs.
In this case, the model training could be stopped at the inflection point. Alternately, the number of training examples could be increased.
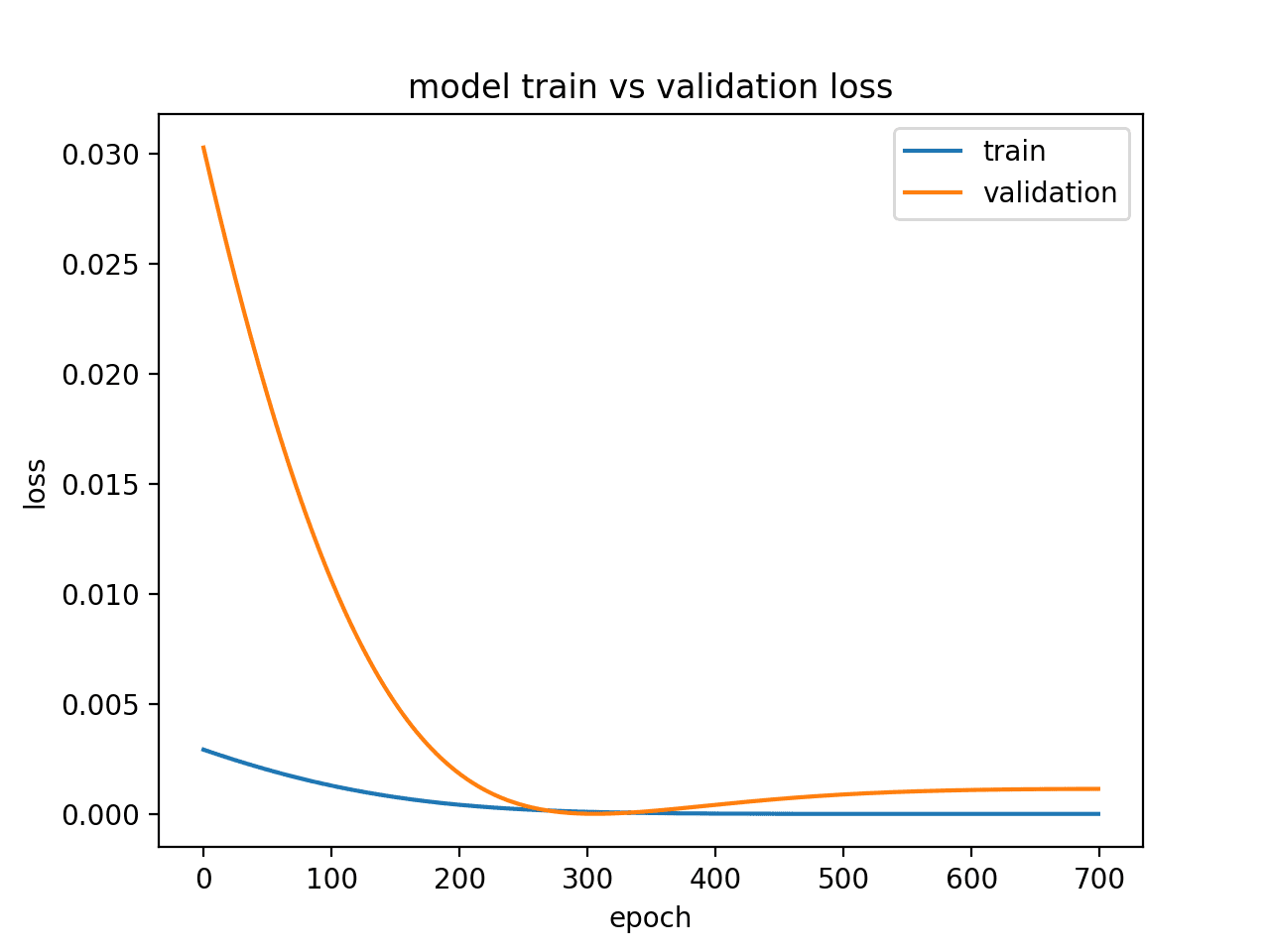
Diagnostic Line Plot Showing an Overfit Model
6. Multiple Runs Example
LSTMs are stochastic, meaning that you will get a different diagnostic plot each run.
It can be useful to repeat the diagnostic run multiple times (e.g. 5, 10, or 30). The train and validation traces from each run can then be plotted to give a more robust idea of the behavior of the model over time.
The example below runs the same experiment a number of times before plotting the trace of train and validation loss for each run.
In the resulting plot, we can see that the general trend of underfitting holds across 5 runs and is a stronger case for perhaps increasing the number of training epochs.
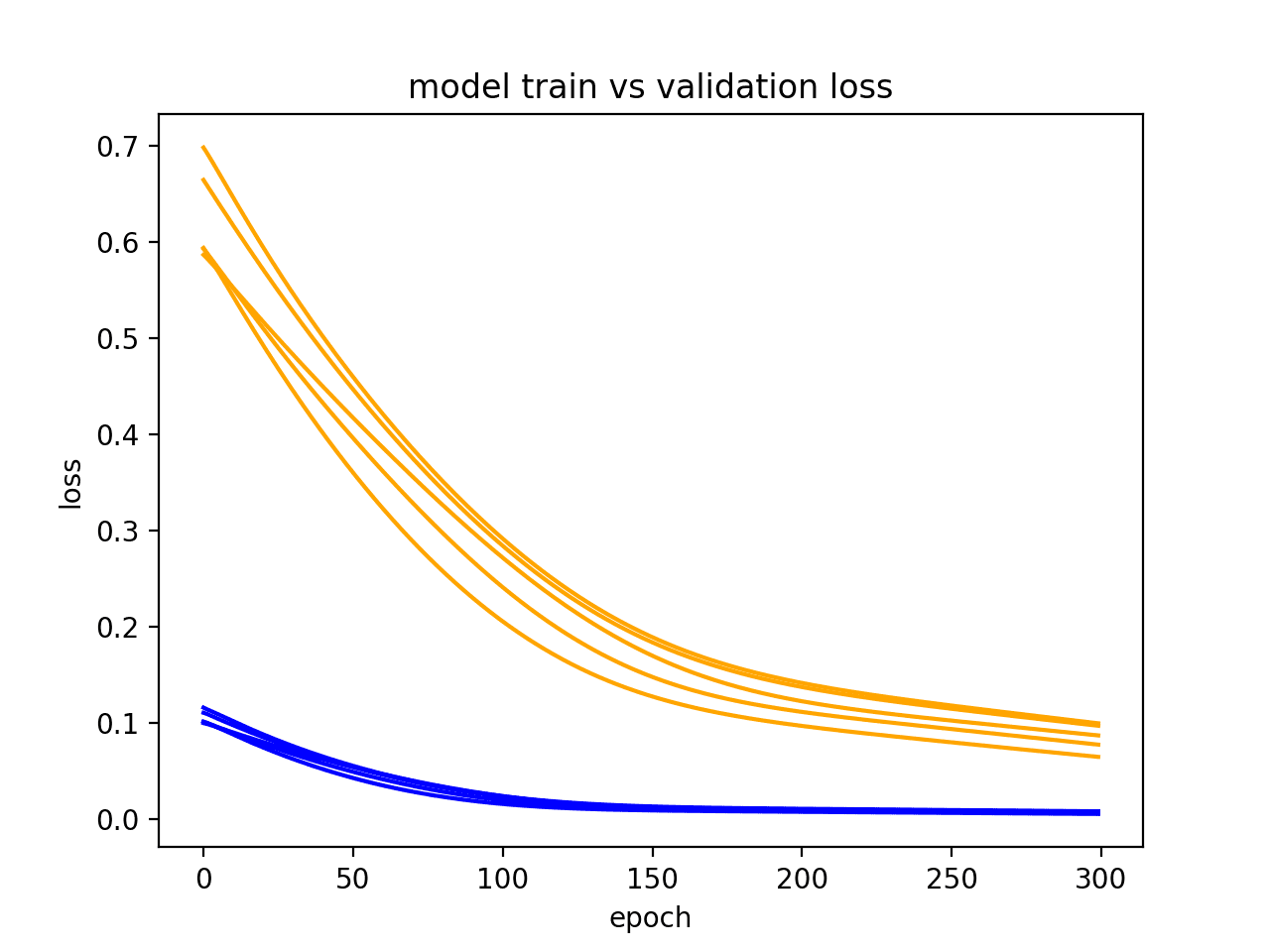
Diagnostic Line Plot Showing Multiple Runs for a Model
Further Reading
This section provides more resources on the topic if you are looking go deeper.
Summary
In this tutorial, you discovered how to diagnose the fit of your LSTM model on your sequence prediction problem.
Specifically, you learned:
- How to gather and plot training history of LSTM models.
- How to diagnose an underfit, good fit, and overfit model.
- How to develop more robust diagnostics by averaging multiple model runs.
Do you have any questions?
Ask your questions in the comments below and I will do my best to answer.





No comments:
Post a Comment