Gentle introduction to the Encoder-Decoder LSTMs for
sequence-to-sequence prediction with example Python code.
The Encoder-Decoder LSTM is a recurrent neural network designed to address sequence-to-sequence problems, sometimes called seq2seq.
Sequence-to-sequence prediction problems are challenging because the number of items in the input and output sequences can vary. For example, text translation and learning to execute programs are examples of seq2seq problems.
In this post, you will discover the Encoder-Decoder LSTM architecture for sequence-to-sequence prediction.
After completing this post, you will know:
- The challenge of sequence-to-sequence prediction.
- The Encoder-Decoder architecture and the limitation in LSTMs that it was designed to address.
- How to implement the Encoder-Decoder LSTM model architecture in Python with Keras.
Sequence-to-Sequence Prediction Problems
Sequence prediction often involves forecasting the next value in a real valued sequence or outputting a class label for an input sequence.
This is often framed as a sequence of one input time step to one output time step (e.g. one-to-one) or multiple input time steps to one output time step (many-to-one) type sequence prediction problem.
There is a more challenging type of sequence prediction problem that takes a sequence as input and requires a sequence prediction as output. These are called sequence-to-sequence prediction problems, or seq2seq for short.
One modeling concern that makes these problems challenging is that the length of the input and output sequences may vary. Given that there are multiple input time steps and multiple output time steps, this form of problem is referred to as many-to-many type sequence prediction problem.
Encoder-Decoder LSTM Architecture
One approach to seq2seq prediction problems that has proven very effective is called the Encoder-Decoder LSTM.
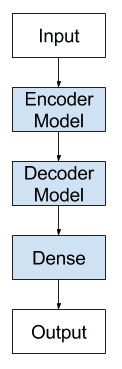
This architecture is comprised of two models: one for reading the input sequence and encoding it into a fixed-length vector, and a second for decoding the fixed-length vector and outputting the predicted sequence. The use of the models in concert gives the architecture its name of Encoder-Decoder LSTM designed specifically for seq2seq problems.
… RNN Encoder-Decoder, consists of two recurrent neural networks (RNN) that act as an encoder and a decoder pair. The encoder maps a variable-length source sequence to a fixed-length vector, and the decoder maps the vector representation back to a variable-length target sequence.
— Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation, 2014.
The Encoder-Decoder LSTM was developed for natural language processing problems where it demonstrated state-of-the-art performance, specifically in the area of text translation called statistical machine translation.
The innovation of this architecture is the use of a fixed-sized internal representation in the heart of the model that input sequences are read to and output sequences are read from. For this reason, the method may be referred to as sequence embedding.
In one of the first applications of the architecture to English-to-French translation, the internal representation of the encoded English phrases was visualized. The plots revealed a qualitatively meaningful learned structure of the phrases harnessed for the translation task.
The proposed RNN Encoder-Decoder naturally generates a continuous-space representation of a phrase. […] From the visualization, it is clear that the RNN Encoder-Decoder captures both semantic and syntactic structures of the phrases
— Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation, 2014.
On the task of translation, the model was found to be more effective when the input sequence was reversed. Further, the model was shown to be effective even on very long input sequences.
We were able to do well on long sentences because we reversed the order of words in the source sentence but not the target sentences in the training and test set. By doing so, we introduced many short term dependencies that made the optimization problem much simpler. … The simple trick of reversing the words in the source sentence is one of the key technical contributions of this work
— Sequence to Sequence Learning with Neural Networks, 2014.
This approach has also been used with image inputs where a Convolutional Neural Network is used as a feature extractor on input images, which is then read by a decoder LSTM.
… we propose to follow this elegant recipe, replacing the encoder RNN by a deep convolution neural network (CNN). […] it is natural to use a CNN as an image
encoder”, by first pre-training it for an image classification task and using the last hidden layer as an input to the RNN decoder that generates sentences— Show and Tell: A Neural Image Caption Generator, 2014.
Encoder-Decoder LSTM Model Architecture
Applications of Encoder-Decoder LSTMs
The list below highlights some interesting applications of the Encoder-Decoder LSTM architecture.
- Machine Translation, e.g. English to French translation of phrases.
- Learning to Execute, e.g. calculate the outcome of small programs.
- Image Captioning, e.g. generating a text description for images.
- Conversational Modeling, e.g. generating answers to textual questions.
- Movement Classification, e.g. generating a sequence of commands from a sequence of gestures.
Implement Encoder-Decoder LSTMs in Keras
The Encoder-Decoder LSTM can be implemented directly in the Keras deep learning library.
We can think of the model as being comprised of two key parts: the encoder and the decoder.
First, the input sequence is shown to the network one encoded character at a time. We need an encoding level to learn the relationship between the steps in the input sequence and develop an internal representation of these relationships.
One or more LSTM layers can be used to implement the encoder model. The output of this model is a fixed-size vector that represents the internal representation of the input sequence. The number of memory cells in this layer defines the length of this fixed-sized vector.
The decoder must transform the learned internal representation of the input sequence into the correct output sequence.
One or more LSTM layers can also be used to implement the decoder model. This model reads from the fixed sized output from the encoder model.
As with the Vanilla LSTM, a Dense layer is used as the output for the network. The same weights can be used to output each time step in the output sequence by wrapping the Dense layer in a TimeDistributed wrapper.
There’s a problem though.
We must connect the encoder to the decoder, and they do not fit.
That is, the encoder will produce a 2-dimensional matrix of outputs, where the length is defined by the number of memory cells in the layer. The decoder is an LSTM layer that expects a 3D input of [samples, time steps, features] in order to produce a decoded sequence of some different length defined by the problem.
If you try to force these pieces together, you get an error indicating that the output of the decoder is 2D and 3D input to the decoder is required.
We can solve this using a RepeatVector layer. This layer simply repeats the provided 2D input multiple times to create a 3D output.
The RepeatVector layer can be used like an adapter to fit the encoder and decoder parts of the network together. We can configure the RepeatVector to repeat the fixed length vector one time for each time step in the output sequence.
Putting this together, we have:
To summarize, the RepeatVector is used as an adapter to fit the fixed-sized 2D output of the encoder to the differing length and 3D input expected by the decoder. The TimeDistributed wrapper allows the same output layer to be reused for each element in the output sequence.
Further Reading
This section provides more resources on the topic if you are looking go deeper.
Papers
- Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation, 2014.
- Sequence to Sequence Learning with Neural Networks, 2014.
- Show and Tell: A Neural Image Caption Generator, 2014.
- Learning to Execute, 2015.
- A Neural Conversational Model, 2015.
Keras API
Posts
- How to use an Encoder-Decoder LSTM to Echo Sequences of Random Integers
- Learn to Add Numbers with an Encoder-Decoder LSTM Recurrent Neural Network
- Attention in Long Short-Term Memory Recurrent Neural Networks
Summary
In this post, you discovered the Encoder-Decoder LSTM architecture for sequence-to-sequence prediction
Specifically, you learned:
- The challenge of sequence-to-sequence prediction.
- The Encoder-Decoder architecture and the limitation in LSTMs that it was designed to address.
- How to implement the Encoder-Decoder LSTM model architecture in Python with Keras.
Do you have any questions?
Ask your questions in the comments below and I will do my best to answer.







No comments:
Post a Comment