Some neural network configurations can result in an unstable model.
This can make them hard to characterize and compare to other model configurations on the same problem using descriptive statistics.
One good example of a seemingly unstable model is the use of online learning (a batch size of 1) for a stateful Long Short-Term Memory (LSTM) model.
In this tutorial, you will discover how to explore the results of a stateful LSTM fit using online learning on a standard time series forecasting problem.
After completing this tutorial, you will know:
- How to design a robust test harness for evaluating LSTM models on time series forecasting problems.
- How to analyze a population of results, including summary statistics, spread, and distribution of results.
- How to analyze the impact of increasing the number of repeats for an experiment.
Model Instability
When you train the same network on the same data more than once, you may get very different results.
This is because neural networks are initialized randomly and the optimization nature of how they are fit to the training data can result in different final weights within the network. These different networks can in turn result in varied predictions given the same input data.
As a result, it is important to repeat any experiment on neural networks multiple times to find an averaged expected performance.
For more on the stochastic nature of machine learning algorithms like neural networks, see the post:
The batch size in a neural network defines how often the weights within the network are updated given exposure to a training dataset.
A batch size of 1 means that the network weights are updated after each single row of training data. This is called online learning. The result is a network that can learn quickly, but a configuration that can be quite unstable.
In this tutorial, we will explore the instability of online learning for a stateful LSTM configuration for time series forecasting.
We will explore this by looking at the average performance of an LSTM configuration on a standard time series forecasting problem over a variable number of repeats of the experiment.
That is, we will re-train the same model configuration on the same data many times and look at the performance of the model on a hold-out dataset and review how unstable the model can be.
Tutorial Overview
This tutorial is broken down into 6 parts. They are:
- Shampoo Sales Dataset
- Experimental Test Harness
- Code and Collect Results
- Basic Statistics on Results
- Repeats vs Test RMSE
- Review of Results
Environment
This tutorial assumes you have a Python SciPy environment installed. You can use either Python 2 or 3 with this example.
This tutorial assumes you have Keras v2.0 or higher installed with either the TensorFlow or Theano backend.
This tutorial also assumes you have scikit-learn, Pandas, NumPy, and Matplotlib installed.
Next, let’s take a look at a standard time series forecasting problem that we can use as context for this experiment.
Shampoo Sales Dataset
This dataset describes the monthly number of sales of shampoo over a 3-year period.
The units are a sales count and there are 36 observations. The original dataset is credited to Makridakis, Wheelwright, and Hyndman (1998).
The example below loads and creates a plot of the loaded dataset.
Running the example loads the dataset as a Pandas Series and prints the first 5 rows.
A line plot of the series is then created showing a clear increasing trend.
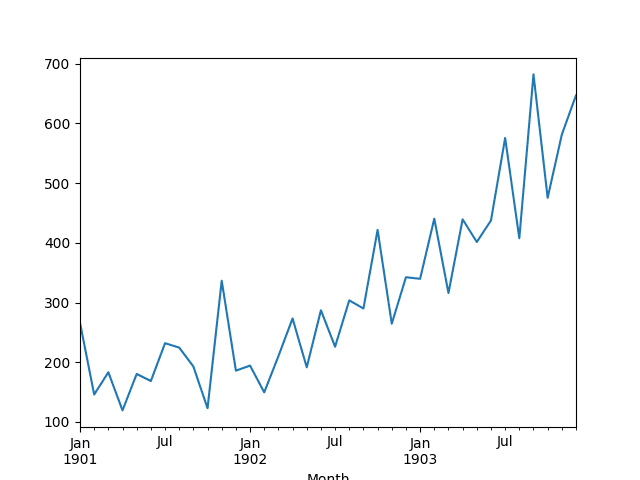
Line Plot of Shampoo Sales Dataset
Next, we will take a look at the LSTM configuration and test harness used in the experiment.
Experimental Test Harness
This section describes the test harness used in this tutorial.
Data Split
We will split the Shampoo Sales dataset into two parts: a training and a test set.
The first two years of data will be taken for the training dataset and the remaining one year of data will be used for the test set.
Models will be developed using the training dataset and will make predictions on the test dataset.
The persistence forecast (naive forecast) on the test dataset achieves an error of 136.761 monthly shampoo sales. This provides a lower acceptable bound of performance on the test set.
Model Evaluation
A rolling-forecast scenario will be used, also called walk-forward model validation.
Each time step of the test dataset will be walked one at a time. A model will be used to make a forecast for the time step, then the actual expected value from the test set will be taken and made available to the model for the forecast on the next time step.
This mimics a real-world scenario where new Shampoo Sales observations would be available each month and used in the forecasting of the following month.
This will be simulated by the structure of the train and test datasets.
All forecasts on the test dataset will be collected and an error score calculated to summarize the skill of the model. The root mean squared error (RMSE) will be used as it punishes large errors and results in a score that is in the same units as the forecast data, namely monthly shampoo sales.
Data Preparation
Before we can fit an LSTM model to the dataset, we must transform the data.
The following three data transforms are performed on the dataset prior to fitting a model and making a forecast.
- Transform the time series data so that it is stationary. Specifically a lag=1 differencing to remove the increasing trend in the data.
- Transform the time series into a supervised learning problem. Specifically the organization of data into input and output patterns where the observation at the previous time step is used as an input to forecast the observation at the current time step
- Transform the observations to have a specific scale. Specifically, to rescale the data to values between -1 and 1 to meet the default hyperbolic tangent activation function of the LSTM model.
These transforms are inverted on forecasts to return them into their original scale before calculating and error score.
LSTM Model
We will use a base stateful LSTM model with 1 neuron fit for 1000 epochs.
A batch size of 1 is required as we will be using walk-forward validation and making one-step forecasts for each of the final 12 months of test data.
A batch size of 1 means that the model will be fit using online training (as opposed to batch training or mini-batch training). As a result, it is expected that the model fit will have some variance.
Ideally, more training epochs would be used (such as 1500), but this was truncated to 1000 to keep run times reasonable.
The model will be fit using the efficient ADAM optimization algorithm and the mean squared error loss function.
Experimental Runs
Each experimental scenario will be run 100 times and the RMSE score on the test set will be recorded from the end each run.
All test RMSE scores are written to file for later analysis.
Let’s dive into the experiments.
Code and Collect Results
The complete code listing is provided below.
It may take a few hours to run on modern hardware.
Running the experiment saves the RMSE scores of the fit model on the test dataset.
Results are saved to the file “experiment_stateful.csv“.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
A truncated listing of the results is provided below.
Basic Statistics on Results
We can start off by calculating some basic statistics on the entire population of 100 test RMSE scores.
Generally, we expect machine learning results to have a Gaussian distribution. This allows us to report the mean and standard deviation of a model and indicate a confidence interval for the model when making predictions on unseen data.
The snippet below loads the result file and calculates some descriptive statistics.
Running the example prints descriptive statistics from the results.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
We can see that on average, the configuration achieved an RMSE of about 107 monthly shampoo sales with a standard deviation of about 17.
We can also see that the best test RMSE observed was about 90 sales, whereas the worse was just under 200, which is quite a spread of scores.
To get a better idea of the spread of the data, a box and whisker plot is also created.
The plot shows the median (green line), middle 50% of the data (box), and outliers (dots). We can see quite a spread to the data towards poor RMSE scores.
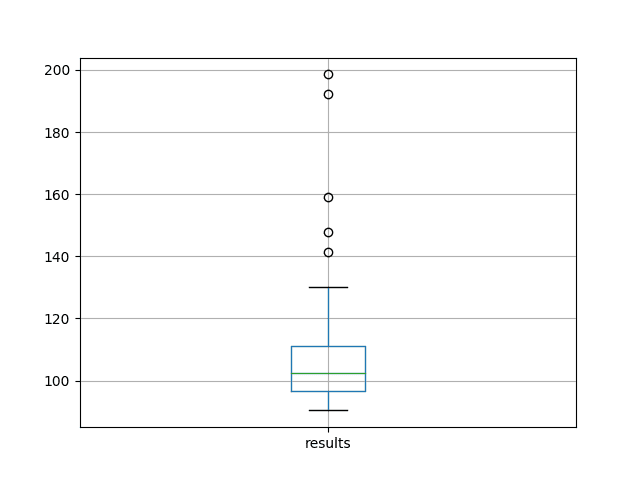
Box and Whisker Plot of 100 Test RMSE Scores on the Shampoo Sales Dataset
A histogram of the raw result values is also created.
The plot suggests a skewed or even an exponential distribution with a mass around an RMSE of 100 and a long tail leading out towards an RMSE of 200.
The distribution of the results are clearly not Gaussian. This is unfortunate, as the mean and standard deviation cannot be used directly to estimate a confidence interval for the model (e.g. 95% confidence as 2x the standard deviation around the mean).
The skewed distribution also highlights that the median (50th percentile) would be a better central tendency to use instead of the mean for these results. The median should be more robust to outlier results than the mean.
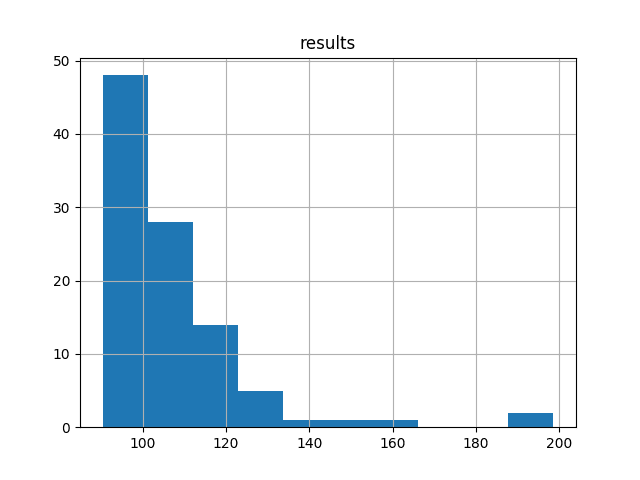
Histogram of Test RMSE Scores on Shampoo Sales Dataset
Repeats vs Test RMSE
We can start to look at how the summary statistics for the experiment change as the number of repeats is increased from 1 to 100.
We can accumulate the test RMSE scores and calculate descriptive statistics. For example, the score from one repeat, the scores from the first and second repeats, the scores from the first 3 repeats, and so on to 100 repeats.
We can review how the central tendency changes as the number of repeats is increased as a line plot. We’ll look at both the mean and median.
Generally, we would expect that as the number of repeats of the experiment is increased, the distribution would increasingly better match the underlying distribution, including the central tendency, such as the mean.
The complete code listing is provided below.
The cumulative size of the distribution, mean, and median is printed as the number of repeats is increased.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
A truncated output is listed below.
A line plot is also created showing how the mean and median change as the number of repeats is increased.
The results show that the mean is more influenced by outlier results than the median, as expected.
We can see that the median appears quite stable down around 99-100. This jumps to 102 towards the end of the plot suggesting a string of worse RMSE scores at later repeats.
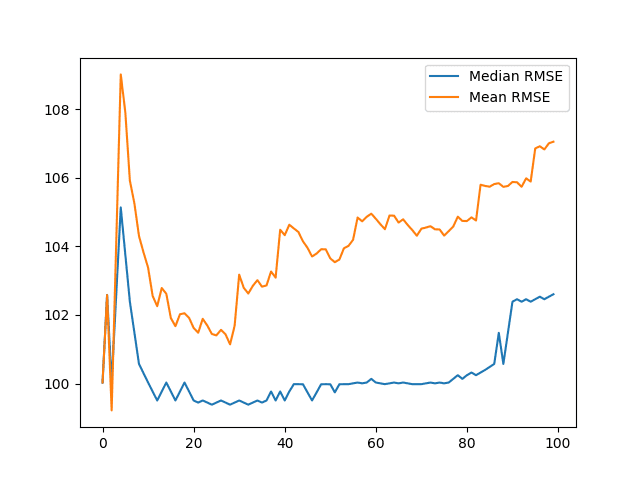
Line Plots of Mean and Median Test RMSE vs Number of Repeats
Review of Results
We made some useful observations from 100 repeats of a stateful LSTM on a standard time series forecasting problem.
Specifically:
- We observed that the distribution of results is not Gaussian. It may be a skewed Gaussian or an exponential distribution with a long tail and outliers.
- We observed that the distribution of results did not stabilize with the increase of repeats from 1 to 100.
The observations suggest a few important properties:
- The choice of online learning for the LSTM and problem results in a relatively unstable model.
- The chosen number of repeats (100) may not be sufficient to characterize the behavior of the model.
This is a useful finding as it would be a mistake to make strong conclusions about the model from 100 or fewer repeats of the experiment.
This is an important caution to consider when describing your own machine learning results.
This suggests some extensions to this experiment, such as:
- Explore the impact of the number of repeats on a more stable model, such as one using batch or mini-batch learning.
- Increase the number of repeats to thousands or more in an attempt to account for the general instability of the model with online learning.
Summary
In this tutorial, you discovered how to analyze experimental results from LSTM models fit using online learning.
You learned:
- How to design a robust test harness for evaluating LSTM models on time series forecast problems.
- How to analyze experimental results, including summary statistics.
- How to analyze the impact of increasing the number of experiment repeats and how to identify an unstable model.
Do you have any questions?
Ask your questions in the comments below and I will do my best to answer.






No comments:
Post a Comment