A benefit of using neural network models for time series forecasting is that the weights can be updated as new data becomes available.
In this tutorial, you will discover how you can update a Long Short-Term Memory (LSTM) recurrent neural network with new data for time series forecasting.
After completing this tutorial, you will know:
- How to update an LSTM neural network with new data.
- How to develop a test harness to evaluate different update schemes.
- How to interpret the results from updating LSTM networks with new data.
Tutorial Overview
This tutorial is divided into 9 parts. They are:
- Shampoo Sales Dataset
- Experimental Test Harness
- Experiment: No Updates
- Experiment: 2 Update Epochs
- Experiment: 5 Update Epochs
- Experiment: 10 Update Epochs
- Experiment: 20 Update Epochs
- Experiment: 50 Update Epochs
- Comparison of Results
Environment
This tutorial assumes you have a Python SciPy environment installed. You can use either Python 2 or 3 with this example.
This tutorial assumes you have Keras v2.0 or higher installed with either the TensorFlow or Theano backend.
This tutorial also assumes you have scikit-learn, Pandas, NumPy, and Matplotlib installed.
If you need help setting up your Python environment, see this post:
Shampoo Sales Dataset
This dataset describes the monthly number of sales of shampoo over a 3-year period.
The units are a sales count and there are 36 observations. The original dataset is credited to Makridakis, Wheelwright, and Hyndman (1998).
The example below loads and creates a plot of the loaded dataset.
Running the example loads the dataset as a Pandas Series and prints the first 5 rows.
A line plot of the series is then created showing a clear increasing trend.
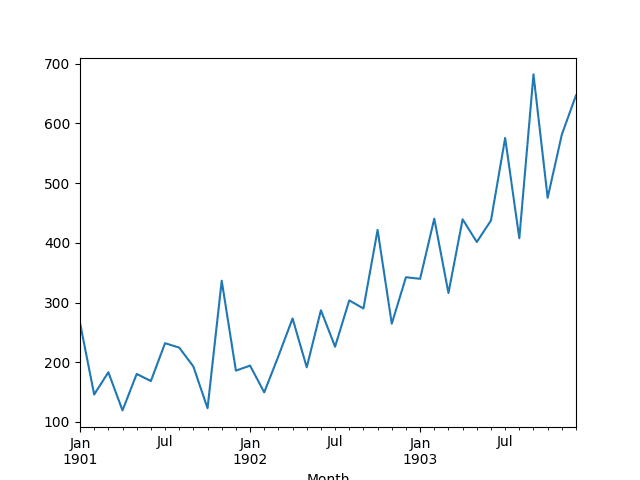
Line Plot of Shampoo Sales Dataset
Next, we will take a look at the LSTM configuration and test harness used in the experiment.
Need help with Deep Learning for Time Series?
Take my free 7-day email crash course now (with sample code).
Click to sign-up and also get a free PDF Ebook version of the course.
Experimental Test Harness
This section describes the test harness used in this tutorial.
Data Split
We will split the Shampoo Sales dataset into two parts: a training and a test set.
The first two years of data will be taken for the training dataset and the remaining one year of data will be used for the test set.
Models will be developed using the training dataset and will make predictions on the test dataset.
The persistence forecast (naive forecast) on the test dataset achieves an error of 136.761 monthly shampoo sales. This provides an acceptable lower bound of performance on the test set.
Model Evaluation
A rolling-forecast scenario will be used, also called walk-forward model validation.
Each time step of the test dataset will be walked one at a time. A model will be used to make a forecast for the time step, then the actual expected value from the test set will be taken and made available to the model for the forecast on the next time step.
This mimics a real-world scenario where new Shampoo Sales observations would be available each month and used in the forecasting of the following month.
This will be simulated by the structure of the train and test datasets.
All forecasts on the test dataset will be collected and an error score calculated to summarize the skill of the model. The root mean squared error (RMSE) will be used as it punishes large errors and results in a score that is in the same units as the forecast data, namely monthly shampoo sales.
Data Preparation
Before we can fit an LSTM model to the dataset, we must transform the data.
The following three data transforms are performed on the dataset prior to fitting a model and making a forecast.
- Transform the time series data so that it is stationary. Specifically, a lag=1 differencing to remove the increasing trend in the data.
- Transform the time series into a supervised learning problem. Specifically, the organization of data into input and output patterns where the observation at the previous time step is used as an input to forecast the observation at the current time step
- Transform the observations to have a specific scale. Specifically, to rescale the data to values between -1 and 1 to meet the default hyperbolic tangent activation function of the LSTM model.
These transforms are inverted on forecasts to return them into their original scale before calculating an error score.
LSTM Model
We will use an LSTM model with 1 neuron fit for 500 epochs.
A batch size of 1 is required as we will be using walk-forward validation and making one-step forecasts for each of the final 12 months of data.
A batch size of 1 means that the model will be fit using online training (as opposed to batch training or mini-batch training). As a result, it is expected that the model fit will have some variance.
Ideally, more training epochs would be used (such as 1000 or 1500), but this was truncated to 500 to keep run times reasonable.
The model will be fit using the efficient ADAM optimization algorithm and the mean squared error loss function.
Experimental Runs
Each experimental scenario will be run 10 times.
The reason for this is that the random initial conditions for an LSTM network can result in very different performance each time a given configuration is trained.
Let’s dive into the experiments.
Experiment: No Updates
In this first experiment, we will evaluate an LSTM trained once and reused to make a forecast for each time step.
We will call this the ‘no updates model‘ or the ‘fixed model‘ as no updates will be made once the model is first fit on the training data. This provides a baseline of performance that we would expect experiments that make modest updates to the model to outperform.
The complete code listing is provided below.
Running the example stores the RMSE scores calculated on the test dataset using walk-forward validation. These are stored in a file called experiment_fixed.csv for later analysis. A summary of the scores is printed, shown below.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
The results suggest an average performance that outperforms the persistence model showing a test RMSE of 109.565465 compared to 136.761 monthly shampoo sales for persistence.
Next, we will start looking at configurations that make updates to the model during the walk-forward validation.
Experiment: 2 Update Epochs
In this experiment, we fit the model on all of the training data, then update the model after each forecast during the walk-forward validation.
Each test pattern used to elicit a forecast in the test dataset is then added to the training dataset and the model is updated.
In this case, the model is fit for an additional 2 training epochs before making the next forecast.
The same code listing as was used in the first experiment is used. The changes to the code listing are shown below.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
Running the experiment saves the final test RMSE scores in “experiment_update_2.csv” and prints summary statistics of the results, listed below.
Experiment: 5 Update Epochs
This experiments repeats the above update experiment and trains the model for an additional 5 epochs after each test pattern is added to the training dataset.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
Running the experiment saves the final test RMSE scores in “experiment_update_5.csv” and prints summary statistics of the results, listed below.
Experiment: 10 Update Epochs
This experiments repeats the above update experiment and trains the model for an additional 10 epochs after each test pattern is added to the training dataset.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
Running the experiment saves the final test RMSE scores in “experiment_update_10.csv” and prints summary statistics of the results, listed below.
Experiment: 20 Update Epochs
This experiments repeats the above update experiment and trains the model for an additional 20 epochs after each test pattern is added to the training dataset.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
Running the experiment saves the final test RMSE scores in “experiment_update_20.csv” and prints summary statistics of the results, listed below.
Experiment: 50 Update Epochs
This experiments repeats the above update experiment and trains the model for an additional 50 epochs after each test pattern is added to the training dataset.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
Running the experiment saves the final test RMSE scores in “experiment_update_50.csv” and prints summary statistics of the results, listed below.
Comparison of Results
In this section, we compare the results saved from the previous experiments.
We load each of the saved results, summarize the results with descriptive statistics, and compare the results using box and whisker plots.
The complete code listing is provided below.
Running the example first calculates and prints descriptive statistics for each of the experimental results.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
If we look at the average performance, we can see that the fixed model provides a good baseline of performance, but we see that a modest number of update epochs (20 and 50) produce worse test set RMSE on average.
We see that a small number of update epochs result in better overall test set performance, specifically 2 epochs followed by 5 epochs. This is encouraging.
A box and whisker plot is also created that compares the distribution of test RMSE results from each experiment.
The plot highlights the median (green line) as well as the middle 50% of the data (box) for each experiment. The plot tells the same story as the average performance, suggesting that a small number of training epochs (2 or 5 epochs) result in the best overall test RMSE.
The plot shows a rise in test RMSE as the number of updates increases to 20 epochs, then back down again for 50 epochs. This might be a sign of significant further training improving the model (11 * 50 epochs) or an artifact of the small number of repeats (10).
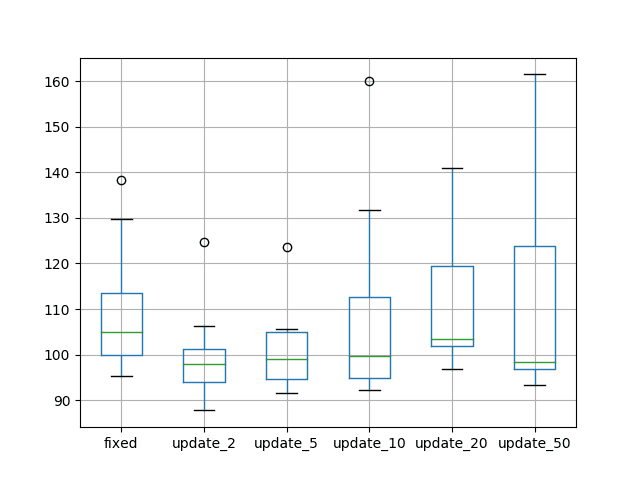
Box and Whisker Plots Comparing the Number of Update Epochs
It is important to point out that these results are specific to the model configuration and this dataset.
It is hard to generalize these results beyond this specific example, although these experiments do provide a framework for performing similar experiments on your own predictive modeling problem.
Extensions
This section lists ideas for extensions to the experiments in this section.
- Statistical Significance Tests. We could calculate pairwise statistical significance tests, such as the Student t-test, to see if the differences between the means in the populations of results are statistically significant or not.
- More Repeats. We could increase the number of repeats from 10 to 30, 100, or more in an attempt to make the findings more robust.
- More Epochs. The base LSTM model was only fit for 500 epochs with online training and it is believed that additional training epochs will result in a more accurate baseline model. The number of epochs was cut to decrease experiment run time.
- Compare to more Epochs. The results for experiments that update the model should be compared directly to experiments of a fixed model that uses the same number of overall epochs to see if adding the additional test patterns to the training dataset makes any noticeable difference. For example, 2 update epochs for each test pattern could be compared to a fixed model trained for 500 + (12-1) * 2) or 522 epochs, an update model 5 compared to a fixed model fit for 500 + (12-1) * 5) or 555 epochs, and so on.
- Completely New Model. Add an experiment where a new model is fit after each test pattern is added to the training dataset. This was attempted, but the extended run time prevented the results being collected prior to finalizing this tutorial. This would be expected to provide an interesting point of comparison to the update and fixed models.
Did you explore any of these extensions?
Report your results in the comments; I’d love to hear what you discovered.Summary
In this tutorial, you discovered how to update an LSTM network as new data becomes available for time series forecasting in Python.
Specifically, you learned:
- How to design a systematic set of experiments to explore the effect of updating LSTM models.
- How to update an LSTM model as new data becomes available.
- That updates to an LSTM model can result in a more effective predictive model, but careful calibration is required on your forecast problem.
Do you have any questions?
Ask your questions in the comments below and I will do my best to answer.





No comments:
Post a Comment