Some machine learning algorithms will achieve better performance if your time series data has a consistent scale or distribution.
Two techniques that you can use to consistently rescale your time series data are normalization and standardization.
In this tutorial, you will discover how you can apply normalization and standardization rescaling to your time series data in Python.
After completing this tutorial, you will know:
- The limitations of normalization and expectations of your data for using standardization.
- What parameters are required and how to manually calculate normalized and standardized values.
- How to normalize and standardize your time series data using scikit-learn in Python.
Kick-start your project with my new book Time Series Forecasting With Python, including step-by-step tutorials and the Python source code files for all examples.
Let’s get started.
- Updated Apr/2019: Updated the link to dataset.
- Updated Aug/2019: Updated data loading to use new API.

How to Normalize and Standardize Time Series Data in Python
Photo by Sage Ross, some rights reserved.
Minimum Daily Temperatures Dataset
This dataset describes the minimum daily temperatures over 10 years (1981-1990) in the city Melbourne, Australia.
The units are in degrees Celsius and there are 3,650 observations. The source of the data is credited as the Australian Bureau of Meteorology.
Below is a sample of the first 5 rows of data, including the header row.
Below is a plot of the entire dataset.
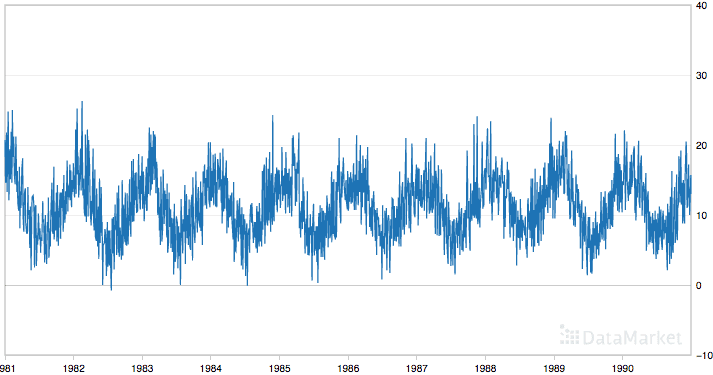
Minimum Daily Temperatures
The dataset shows a strong seasonality component and has a nice, fine-grained detail to work with.
This tutorial assumes that the dataset is in your current working directory with the filename “daily-minimum-temperatures-in-me.csv“.
Normalize Time Series Data
Normalization is a rescaling of the data from the original range so that all values are within the range of 0 and 1.
Normalization can be useful, and even required in some machine learning algorithms when your time series data has input values with differing scales.It may be required for algorithms, like k-Nearest neighbors, which uses distance calculations and Linear Regression and Artificial Neural Networks that weight input values.
Normalization requires that you know or are able to accurately estimate the minimum and maximum observable values. You may be able to estimate these values from your available data. If your time series is trending up or down, estimating these expected values may be difficult and normalization may not be the best method to use on your problem.
A value is normalized as follows:
Where the minimum and maximum values pertain to the value x being normalized.
For example, for the temperature data, we could guesstimate the min and max observable values as 30 and -10, which are greatly over and under-estimated. We can then normalize any value like 18.8 as follows:
You can see that if an x value is provided that is outside the bounds of the minimum and maximum values, that the resulting value will not be in the range of 0 and 1. You could check for these observations prior to making predictions and either remove them from the dataset or limit them to the pre-defined maximum or minimum values.
You can normalize your dataset using the scikit-learn object MinMaxScaler.
Good practice usage with the MinMaxScaler and other rescaling techniques is as follows:
- Fit the scaler using available training data. For normalization, this means the training data will be used to estimate the minimum and maximum observable values. This is done by calling the fit() function,
- Apply the scale to training data. This means you can use the normalized data to train your model. This is done by calling the transform() function
- Apply the scale to data going forward. This means you can prepare new data in the future on which you want to make predictions.
If needed, the transform can be inverted. This is useful for converting predictions back into their original scale for reporting or plotting. This can be done by calling the inverse_transform() function.
Below is an example of normalizing the Minimum Daily Temperatures dataset.
The scaler requires data to be provided as a matrix of rows and columns. The loaded time series data is loaded as a Pandas Series. It must then be reshaped into a matrix of one column with 3,650 rows.
The reshaped dataset is then used to fit the scaler, the dataset is normalized, then the normalization transform is inverted to show the original values again.
Running the example prints the first 5 rows from the loaded dataset, shows the same 5 values in their normalized form, then the values back in their original scale using the inverse transform.
We can also see that the minimum and maximum values of the dataset are 0 and 26.3 respectively.
There is another type of rescaling that is more robust to new values being outside the range of expected values; this is called Standardization. We will look at that next.
Standardize Time Series Data
Standardizing a dataset involves rescaling the distribution of values so that the mean of observed values is 0 and the standard deviation is 1.
This can be thought of as subtracting the mean value or centering the data.
Like normalization, standardization can be useful, and even required in some machine learning algorithms when your time series data has input values with differing scales.
Standardization assumes that your observations fit a Gaussian distribution (bell curve) with a well behaved mean and standard deviation. You can still standardize your time series data if this expectation is not met, but you may not get reliable results.
This includes algorithms like Support Vector Machines, Linear and Logistic Regression, and other algorithms that assume or have improved performance with Gaussian data.
Standardization requires that you know or are able to accurately estimate the mean and standard deviation of observable values. You may be able to estimate these values from your training data.
A value is standardized as follows:
Where the mean is calculated as:
And the standard_deviation is calculated as:
For example, we can plot a histogram of the Minimum Daily Temperatures dataset as follows:
Running the code gives the following plot that shows a Gaussian distribution of the dataset, as assumed by standardization.
Minimum Daily Temperatures Histogram
We can guesstimate a mean temperature of 10 and a standard deviation of about 5. Using these values, we can standardize the first value in the dataset of 20.7 as follows:
The mean and standard deviation estimates of a dataset can be more robust to new data than the minimum and maximum.
You can standardize your dataset using the scikit-learn object StandardScaler.
Below is an example of standardizing the Minimum Daily Temperatures dataset.
Running the example prints the first 5 rows of the dataset, prints the same values standardized, then prints the values back in their original scale.
We can see that the estimated mean and standard deviation were 11.1 and 4.0 respectively.
Summary
In this tutorial, you discovered how to normalize and standardize time series data in Python.
Specifically, you learned:
- That some machine learning algorithms perform better or even require rescaled data when modeling.
- How to manually calculate the parameters required for normalization and standardization.
- How to normalize and standardize time series data using scikit-learn in Python.
Do you have any questions about rescaling time series data or about this post?
Ask your questions in the comments and I will do my best to answer.





No comments:
Post a Comment