A problem with gradient boosted decision trees is that they are quick to learn and overfit training data.
One effective way to slow down learning in the gradient boosting model is to use a learning rate, also called shrinkage (or eta in XGBoost documentation).
In this post you will discover the effect of the learning rate in gradient boosting and how to tune it on your machine learning problem using the XGBoost library in Python.
After reading this post you will know:
- The effect learning rate has on the gradient boosting model.
- How to tune learning rate on your machine learning on your problem.
- How to tune the trade-off between the number of boosted trees and learning rate on your problem.
Slow Learning in Gradient Boosting with a Learning Rate
Gradient boosting involves creating and adding trees to the model sequentially.
New trees are created to correct the residual errors in the predictions from the existing sequence of trees.
The effect is that the model can quickly fit, then overfit the training dataset.
A technique to slow down the learning in the gradient boosting model is to apply a weighting factor for the corrections by new trees when added to the model.
This weighting is called the shrinkage factor or the learning rate, depending on the literature or the tool.
Naive gradient boosting is the same as gradient boosting with shrinkage where the shrinkage factor is set to 1.0. Setting values less than 1.0 has the effect of making less corrections for each tree added to the model. This in turn results in more trees that must be added to the model.
It is common to have small values in the range of 0.1 to 0.3, as well as values less than 0.1.
Let’s investigate the effect of the learning rate on a standard machine learning dataset.
Problem Description: Otto Dataset
In this tutorial we will use the Otto Group Product Classification Challenge dataset.
This dataset is available for free from Kaggle (you will need to sign-up to Kaggle to be able to download this dataset). You can download the training dataset train.csv.zip from the Data page and place the unzipped train.csv file into your working directory.
This dataset describes the 93 obfuscated details of more than 61,000 products grouped into 10 product categories (e.g. fashion, electronics, etc.). Input attributes are counts of different events of some kind.
The goal is to make predictions for new products as an array of probabilities for each of the 10 categories and models are evaluated using multiclass logarithmic loss (also called cross entropy).
This competition was completed in May 2015 and this dataset is a good challenge for XGBoost because of the nontrivial number of examples, the difficulty of the problem and the fact that little data preparation is required (other than encoding the string class variables as integers).
Tuning Learning Rate in XGBoost
When creating gradient boosting models with XGBoost using the scikit-learn wrapper, the learning_rate parameter can be set to control the weighting of new trees added to the model.
We can use the grid search capability in scikit-learn to evaluate the effect on logarithmic loss of training a gradient boosting model with different learning rate values.
We will hold the number of trees constant at the default of 100 and evaluate of suite of standard values for the learning rate on the Otto dataset.
There are 6 variations of learning rate to be tested and each variation will be evaluated using 10-fold cross validation, meaning that there is a total of 6×10 or 60 XGBoost models to be trained and evaluated.
The log loss for each learning rate will be printed as well as the value that resulted in the best performance.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
Running this example prints the best result as well as the log loss for each of the evaluated learning rates.
Interestingly, we can see that the best learning rate was 0.2.
This is a high learning rate and it suggest that perhaps the default number of trees of 100 is too low and needs to be increased.
We can also plot the effect of the learning rate of the (inverted) log loss scores, although the log10-like spread of chosen learning_rate values means that most are squashed down the left-hand side of the plot near zero.
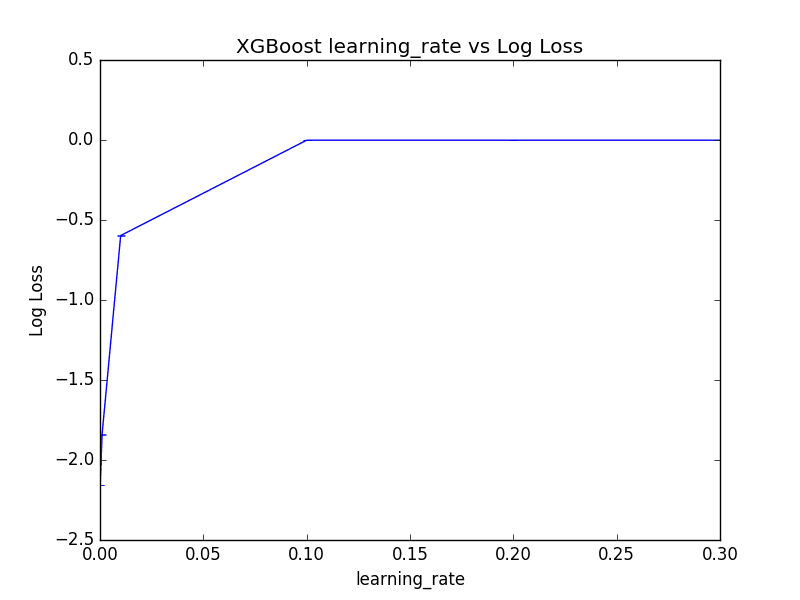
Tune Learning Rate in XGBoost
Next, we will look at varying the number of trees whilst varying the learning rate.
Tuning Learning Rate and the Number of Trees in XGBoost
Smaller learning rates generally require more trees to be added to the model.
We can explore this relationship by evaluating a grid of parameter pairs. The number of decision trees will be varied from 100 to 500 and the learning rate varied on a log10 scale from 0.0001 to 0.1.
There are 5 variations of n_estimators and 4 variations of learning_rate. Each combination will be evaluated using 10-fold cross validation, so that is a total of 4x5x10 or 200 XGBoost models that must be trained and evaluated.
The expectation is that for a given learning rate, performance will improve and then plateau as the number of trees is increased. The full code listing is provided below.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
Running the example prints the best combination as well as the log loss for each evaluated pair.
We can see that the best result observed was a learning rate of 0.1 with 300 trees.
It is hard to pick out trends from the raw data and small negative log loss results. Below is a plot of each learning rate as a series showing log loss performance as the number of trees is varied.
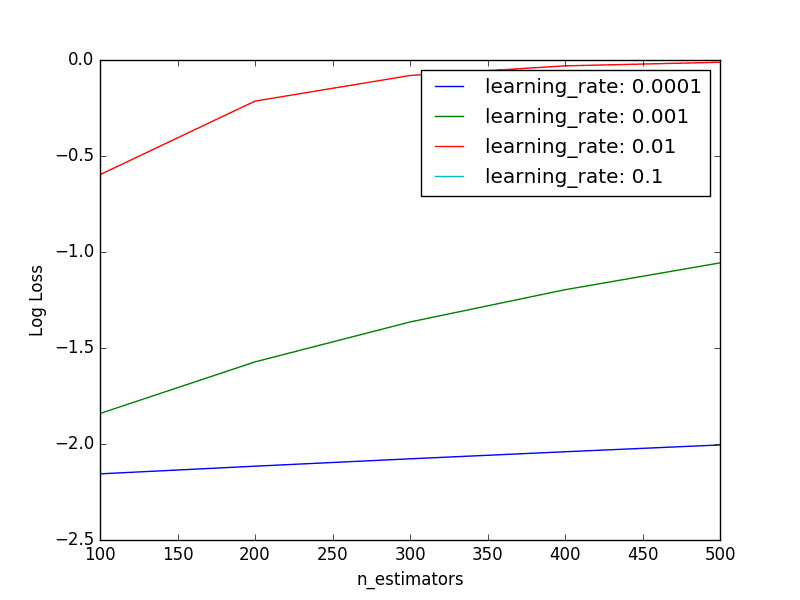
Tuning Learning Rate and Number of Trees in XGBoost
We can see that the expected general trend holds, where the performance (inverted log loss) improves as the number of trees is increased.
Performance is generally poor for the smaller learning rates, suggesting that a much larger number of trees may be required. We may need to increase the number of trees to many thousands which may be quite computationally expensive.
The results for learning_rate=0.1 are obscured due the large y-axis scale of the graph. We can extract the performance measure for just learning_rate=0.1 and plot them directly.
Running this code shows the increased performance as the number of trees are added, followed by a plateau in performance across 400 and 500 trees.
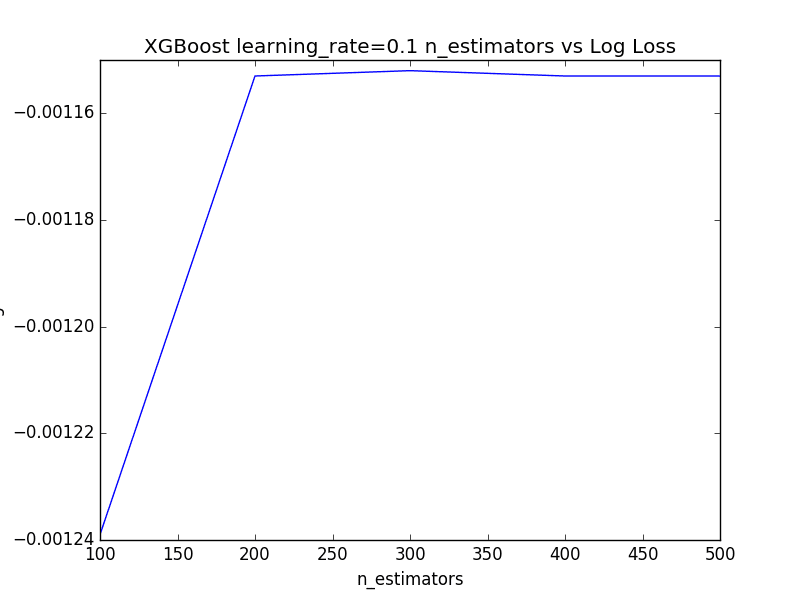
Plot of Learning Rate=0.1 and varying the Number of Trees in XGBoost
Summary
In this post you discovered the effect of weighting the addition of new trees to a gradient boosting model, called shrinkage or the learning rate.
Specifically, you learned:
- That adding a learning rate is intended to slow down the adaptation of the model to the training data.
- How to evaluate a range of learning rate values on your machine learning problem.
- How to evaluate the relationship of varying both the number of trees and the learning rate on your problem.
Do you have any questions regarding shrinkage in gradient boosting or about this post? Ask your questions in the comments and I will do my best to answer them.





No comments:
Post a Comment