The problem of predictive modeling is to create models that have good performance making predictions on new unseen data.
Therefore it is critically important to use robust techniques to train and evaluate your models on your available training data. The more reliable the estimate of the performance on your model, the further you can push the performance and be confident it will translate to the operational use of your model.
In this post you will discover the various different ways that you can estimate the performance of your machine learning models in Weka.
After reading this post you will know:
- How to evaluate your model using the training dataset.
- How to evaluate your model using a random train and test split.
- How to evaluate your model using k-fold cross validation.
Model Evaluation Techniques
There are a number of model evaluation techniques that you can choose from, and the Weka machine learning workbench offers four of them, as follows:
Training Dataset
Prepare your model on the entire training dataset, then evaluate the model on the same dataset. This is generally problematic not least because a perfect algorithm could game this evaluation technique by simply memorizing (storing) all training patterns and achieve a perfect score, which would be misleading.
Supplied Test Set
Split your dataset manually using another program. Prepare your model on the entire training dataset and use the separate test set to evaluate the performance of the model. This is a good approach if you have a large dataset (many tens of thousands of instances).
Percentage Split
Randomly split your dataset into a training and a testing partitions each time you evaluate a model. This can give you a very quick estimate of performance and like using a supplied test set, is preferable only when you have a large dataset.
Cross Validation
Split the dataset into k-partitions or folds. Train a model on all of the partitions except one that is held out as the test set, then repeat this process creating k-different models and give each fold a chance of being held out as the test set. Then calculate the average performance of all k models. This is the gold standard for evaluating model performance, but has the cost of creating many more models.
You can see these techniques in the Weka Explorer on the “Classify” tab after you have loaded a dataset.
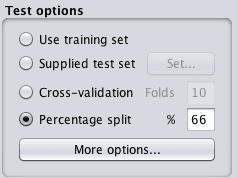
Weka Algorithm Evaluation Test Options
Which Test Option to Use
Given that there are four different test options to choose from, which one should you use?
Each test option has a time and place, summarized as follows:
- Training Dataset: Only to be used when you have all of the data and you are interested in creating a descriptive rather than a predictive model. Because you have all of the data, you do not need to make new predictions. You are interested in creating a model to better understand the problem.
- Supplied Test Set: When the data is very large, e.g. millions of records and you do not need all of it to train a model. Also useful when the test set has been defined by a third party.
- Percentage Split: Excellent to use to get a quick idea of the performance of a model. Not to be used to make decisions, unless you have a very large dataset and are confident (e.g. you have tested) that the splits sufficiently describe the problem. A common split value is 66% to 34% for train and test sets respectively.
- Cross Validation: The default. To be used when you are unsure. Generally provides a more accurate estimate of the performance than the other techniques. Not to be used when you have a very large data. Common values for k are 5 and 10, depending on the size of the dataset.
If in doubt, use k-fold cross validation where k is set to 10.
Need more help with Weka for Machine Learning?
Take my free 14-day email course and discover how to use the platform step-by-step.
Click to sign-up and also get a free PDF Ebook version of the course.
What About The Final Model
Test options are concerned with estimating the performance of a model on unseen data.
This is an important concept to internalize. The goal of predictive modeling is to create a model that performs best in a situation that we do not fully understand, the future with new unknown data. We must use these powerful statistical techniques to best estimate the performance of the model in this situation.
That being said, once we have chosen a model, it must be finalized. None of these test options are used for this purpose.
The model must be trained on the entire training dataset and saved. This topic of model finalization is beyond the scope of this post.
Just note, that the performance of the finalized model does not need to be calculated, it is estimated using the test option techniques discussed above.
Performance Summary
The performance summary is provided in Weka when you evaluate a model.
In the “Classify” tab after you have evaluated an algorithm by clicking the “Start” button, the results are presented in the “Classifier output” pane.
This pane includes a lot of information, including:
- The run information such as the algorithm and its configuration, the dataset and its properties as well as the test option
- The details of the constructed model, if any.
- The summary of the performance including a host of different measures.
Classification Performance Summary
When evaluating a machine learning algorithm on a classification problem, you are given a vast amount of performance information to digest.
This is because classification may be the most studied type of predictive modeling problem and there are so many different ways to think about the performance of classification algorithms.
There are three things to note in the performance summary for classification algorithms:
- Classification accuracy. This the ratio of the number of correct predictions out of all predictions made, often presented as a percentage where 100% is the best an algorithm can achieve. If your data has unbalanced classes, you may want to look into the Kappa metric which presents the same information taking the class balance into account.
- Accuracy by class. Take note of the true-positive and false-positive rates for the predictions for each class which can be instructive of the class breakdown for the problem is uneven or there are more than two classes. This can help you interpret the results if predicting one class is more important than predicting another.
- Confusion matrix. A table showing the number of predictions for each class compared to the number of instances that actually belong to each class. This is very useful to get an overview of the types of mistakes the algorithm made.
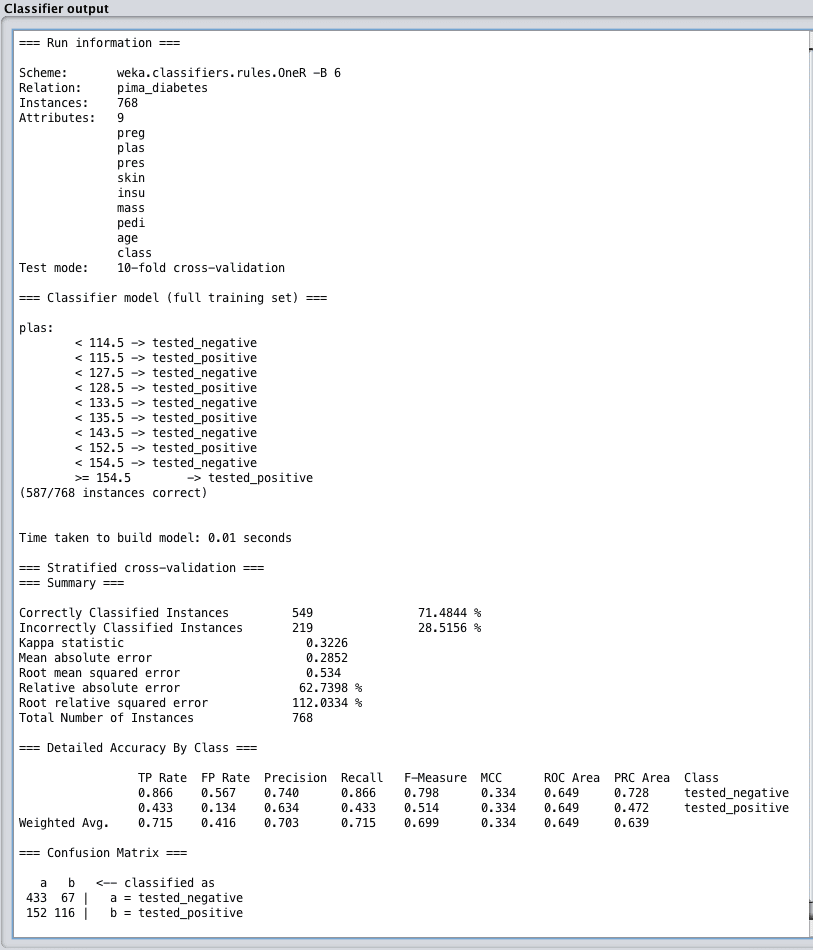
Weka Classification Performance Summary
Regression Performance Summary
When evaluating a machine learning algorithm on a regression problem, you are given a number of different performance measures to review.
Of note the performance summary for regression algorithms are two things:
- Correlation Coefficient. This is how well the predictions are correlated or change with the actual output value. A value of 0 is the worst and a value of 1 is a perfectly correlated set of predictions.
- Root Mean Squared Error. This is the average amount of error made on the test set in the units of the output variable. This measure helps you get an idea on the amount a given prediction may be wrong on average.
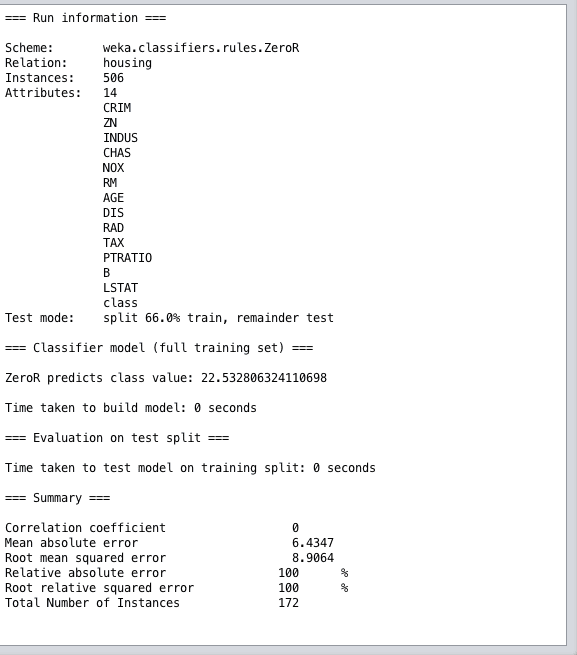
Weka Regression Performance Summary
Summary
In this post you discovered how to estimate the performance of your machine learning models on unseen data in Weka.
Specifically, you learned:
- About the importance of estimating the performance of machine learning models on unseen data as the core problem in predictive modeling.
- About the 4 different test options and when to use each, paying specific attention to train and test splits and k-fold cross validation.
- About the performance summary for classification and regression problems and to which metrics to pay attention.
Do you have any questions about estimating model performance in Weka or about this post? Ask your questions in the comments and I will do my best to answer them.





No comments:
Post a Comment