The Weka machine learning workbench is so easy to use that working through a machine learning project can be a lot of fun.
In this post you will complete your first machine learning project using Weka, end-to-end. This gentle introduction to working through a project will tie together the key steps you need to complete when working through machine learning project in Weka.
After completing this project, you will know:
- How to analyze a dataset and hypothesize data preparation and modeling algorithms that could be used.
- How to spot check a suite of standard machine learning algorithms on a problem
- How to present final results.
Tutorial Overview
This tutorial will gently walk you through the key steps required to complete a machine learning project.
We will work through the following process:
- Load the dataset.
- Analyze the dataset.
- Evaluate algorithms.
- Present results.
You can use this as a template for the minimum steps in the process to work through your own machine learning project using Weka.
Need more help with Weka for Machine Learning?
Take my free 14-day email course and discover how to use the platform step-by-step.
Click to sign-up and also get a free PDF Ebook version of the course.
1. Load Dataset
In this tutorial, we will use the Iris Flowers Classification dataset.
Each instance in the iris dataset describes measurements of iris flowers and the task is to predict which species of 3 iris flower the observation belongs. There are 4 numerical input variables with the same units and generally the same scale. You can learn more about the datasets in the UCI Machine Learning Repository. Top results are in the order of 96% accuracy.
1. Open the Weka GUI Chooser.

Weka GUI Chooser
2. Click the “Explorer” button to open the Weka Explorer.
3. Click the “Open file…” button, navigate to the data/ directory and select iris.arff. Click the “Open button”.
The dataset is now loaded into Weka.
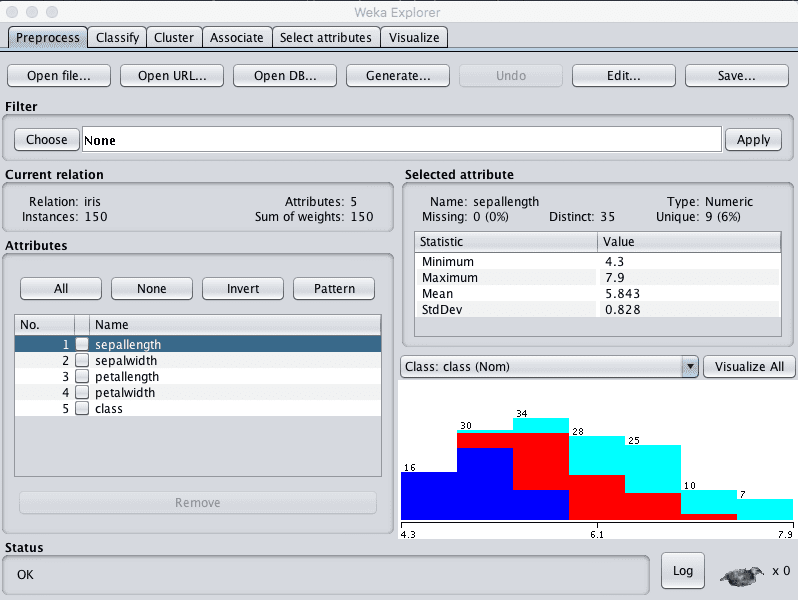
Weka Load Iris Flowers Dataset
2. Analyze the Dataset
It is important to review your data before you start modeling.
Reviewing the distribution of each attribute and the interactions between attributes may shed light on specific data transforms and specific modeling techniques that we could use.
Summary Statistics
Review the details about the dataset in the “Current relation” pane. We can notice a few things:
- The dataset is called iris.
- There are 150 instances. If we use 10-fold cross validation later to evaluate the algorithms, then each fold will be comprised of 15 instances, which is quite small. We may want to think about using 5-folds of 30 instances instead.
- There are 5 attributes, 4 inputs and 1 output variable.
There are a small number of attributes and we could investigate further using feature selection methods.
Click on each attribute in the “Attributes” pane and review the summary statistics in the “Selected attribute” pane.
We can notice a few facts about our data:
- There are no missing values for any of the attributes.
- All inputs are numeric and have values in the same range between about 0 and about 8.
- The last attribute is the output variable called class, it is nominal and has three values.
- The classes are balanced, meaning that there is an equal number of instances in each class. If they were not balanced we may want to think about balancing them.
We may see some benefit from either normalizing or standardizing the data.
Attribute Distributions
Click the “Visualize All” button and lets review the graphical distribution of each attribute.
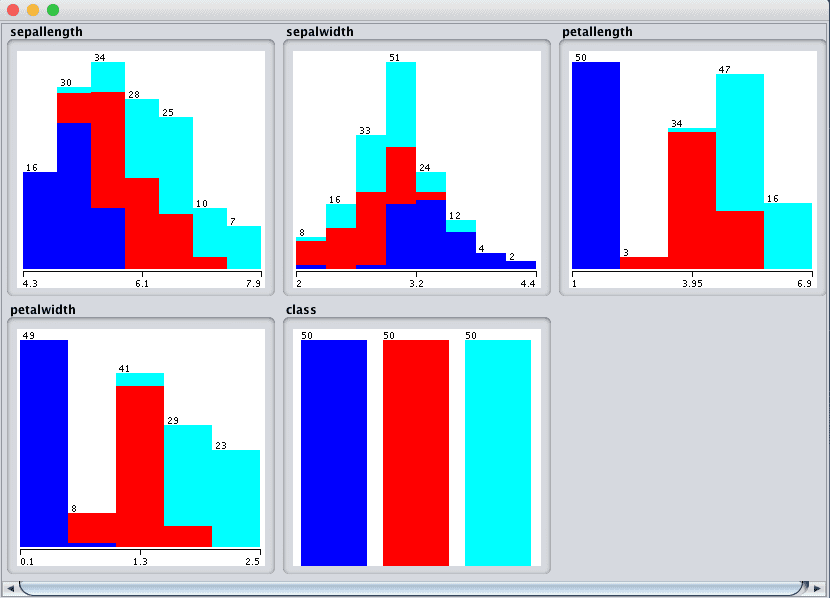
Weka Univariate Attribute Distribution Plots
We can notice a few things about the shape of the data:
- We can see overlap but differing distributions for each of the class values on each of the attributes. This is a good sign as we can probably separate the classes.
- It looks like sepalwidth has a Gaussian-like distribution. If we had a lot more data, perhaps it would be even more Gaussian.
- It looks like the other 3 input attributes have nearly-Gaussian distributions with a skew or a large number of observations at the low end of the distribution. Again, it makes me think that the data may be Gaussian if we had an order of magnitude more examples.
- We also get a visual indication that the classes are balanced.
Attribute Interactions
Click the “Visualize” tab and lets review some interactions between the attributes.
- Increase the window size so all plots are visible.
- Increase the “PointSize” to 3 to make the dots easier to see.
- Click the “Update” button to apply the changes.
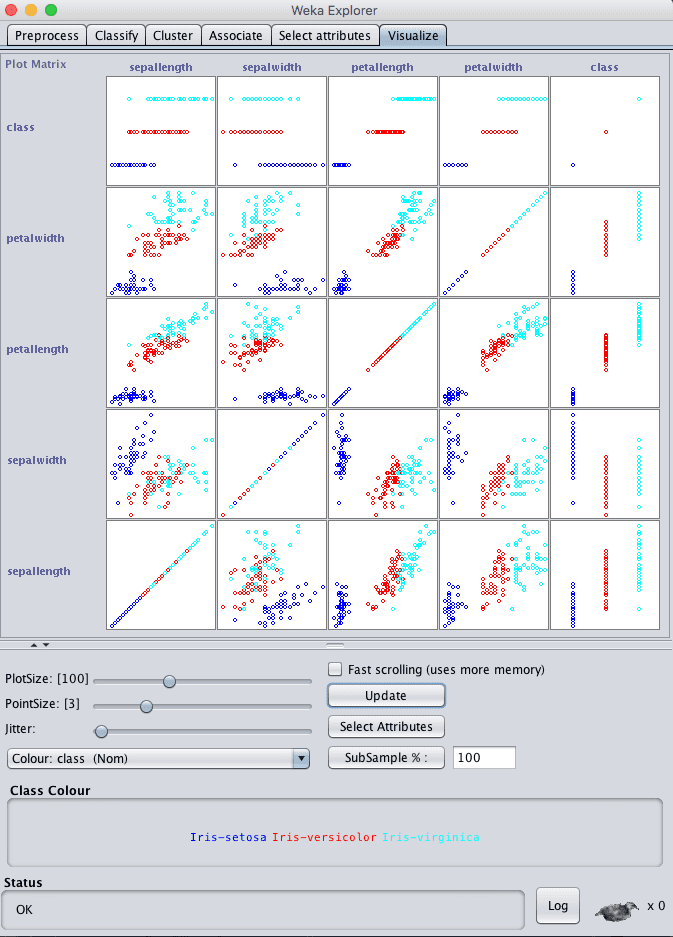
Weka Attribute Scatterplot Matrix
Looking across the graphs for the input variables, we can see good separation between the classes on the scatter plots. For example, petalwidth versus sepallength and petal width versus sepalwidth are good examples.
This suggest that linear methods and maybe decision trees and instance based methods may do well on this problem. It also suggest that we probably do not need to spend too much time tuning or using advanced modeling techniques and ensembles. It may be a straightforward modeling problem.
3. Evaluate Algorithms
Let’s design a small experiment to evaluate a suite of standard classification algorithms on the problem.
1. Close the Weka Explorer.
2. Click the “Experimenter” button on the Weka GUI Chooser to launch the Weka Experiment Environment.
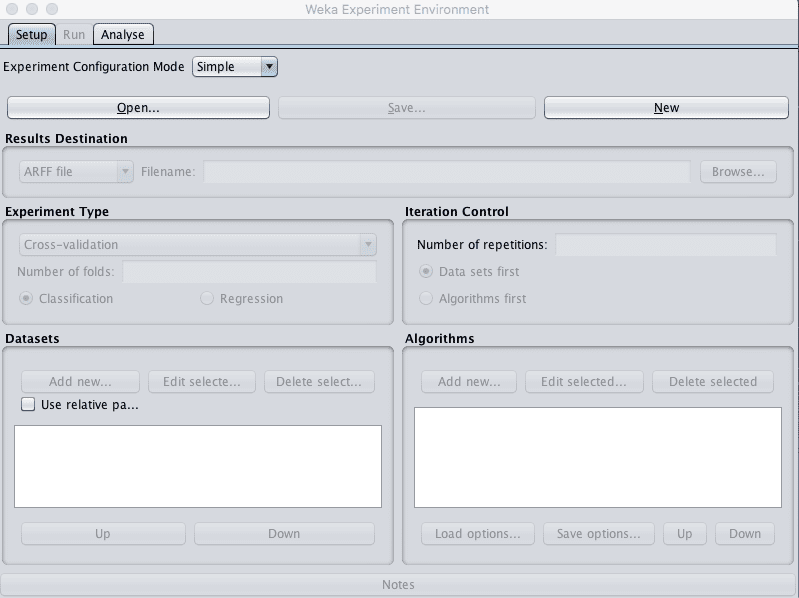
Weka Experiment Environment
3. Click “New” to start a new experiment.
4. In the “Experiment Type” pane change the “Number of folds” from “10” to “5”.
5. In the “Datasets” pane click “Add new…” and select data/iris.arff in your Weka installation directory.
6. In the “Algorithms” pane click “Add new…” and add the following 8 multi-class classification algorithms:
- rules.ZeroR
- bayes.NaiveBayes
- functions.Logistic
- functions.SMO
- lazy.IBk
- rules.PART
- trees.REPTree
- trees.J48
7. Select IBK in the list of algorithms and click the “Edit selected…” button.
8. Change “KNN” from “1” to “3” and click the “OK” button to save the settings.
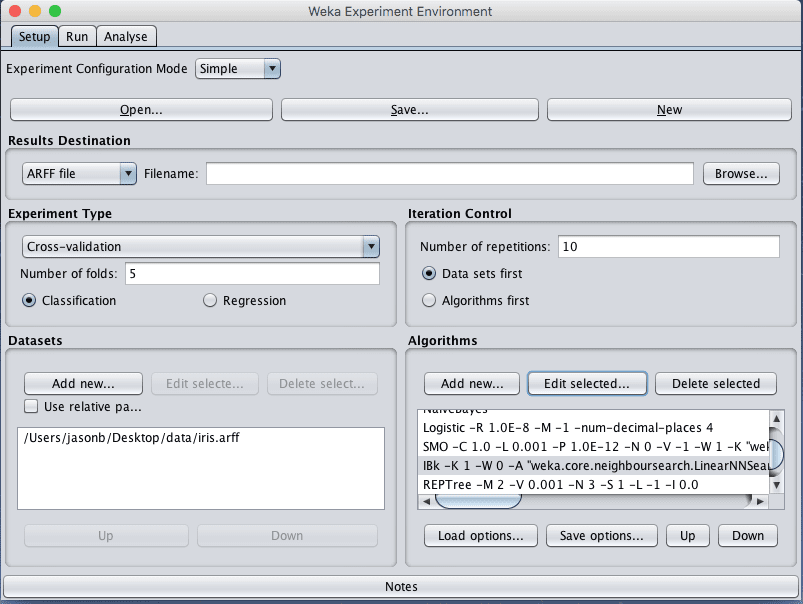
Weka Designed Algorithm Comparison Experiment
9. Click on “Run” to open the Run tab and click the “Start” button to run the experiment. The experiment should complete in just a few seconds.
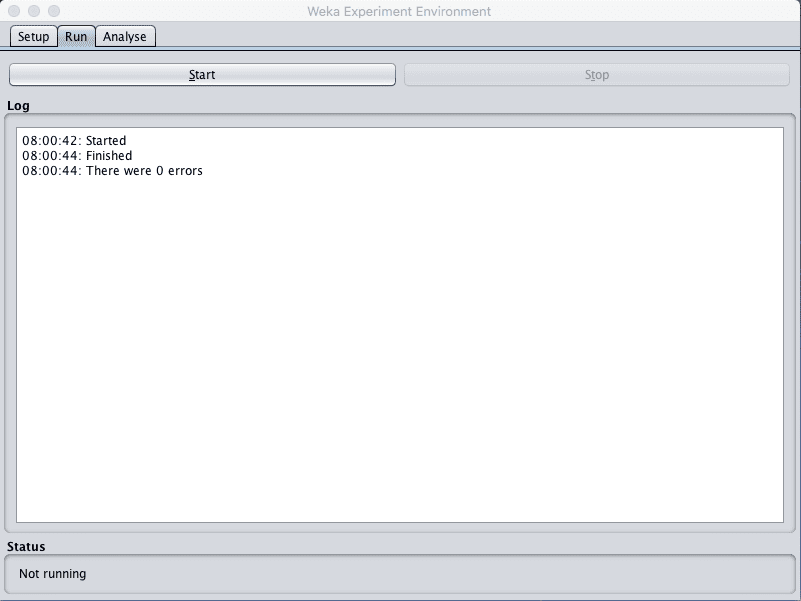
Weka Execute Weka Algorithm Comparison Experiment
10. Click on “Analyse” to open the Analyse tab. Click the “Experiment” button to load the results from the experiment.

Weka Load Algorithm Comparison Experiment Results
11. Click the “Perform test” button to perform a pairwise test comparing all of the results to the results for ZeroR.
We can see that all of the models have skill. Each model has a score that is better than ZeroR and the difference is statistically significant.
The results suggest both Logistic Regression and SVM achieved the highest accuracy. If we were to pick between the two, we would choose Logistic Regression if for no other reason that it is a much simpler model. Let’s compare all of the results to the Logistic Regression results as the test base.
12. Click “Select” for the “Test base”, select “functions.Logistic” and click the “Select” button to choose the new test base. Click the “Perform test” button again to perform the new analysis.
We now see a very different story. Although the results for Logistic look better, the analysis suggests that the difference between these results and the results from all of the other algorithms are not statistically significant.
From here we could choose an algorithm based on other criteria, like understandability or complexity. From this perspective Logistic Regression and Naive Bayes are good candidates.
We could also seek to further improve the results of one or more of these algorithms and see if we can achieve a significant improvement. If we change the “Significance” to less constraining values of 0.50, we can see that the tree and KNN algorithms start to drop away. This suggests we could spend more time on the remaining methods. Change “significance” back to “0.05”.
Let’s choose to stick with Logistic Regression. We can collect some numbers we can use to describe the performance of the model on unseen data.
13. Check “Show std. deviations” to show standard deviations of accuracy scores.
14. Click the “Select” button for “Displayed Columns” and choose “functions.Logistic”, click “Select” to accept the selection. This will only show the results for the Logistic Regression algorithm.
15. Click “Perform test” to rerun the analysis.
We now have a final result we can use to describe our model.
We can see that the estimated accuracy of the model on unseen data is 96.33% with a standard deviation of 3.38%.
4. Finalize Model and Present Results
We can create a final version of our model trained on all of the training data and save it to file.
1. Close the Weka Experiment Environment.
2. Open the Weka Explorer and load the data/iris.arff dataset.
3. Click on the Classify tab.
4. Select the functions.Logistic algorithm.
5. Change the “Test options” from “Cross Validation” to “Use training set”.
6. Click the “Start” button to create the final model.
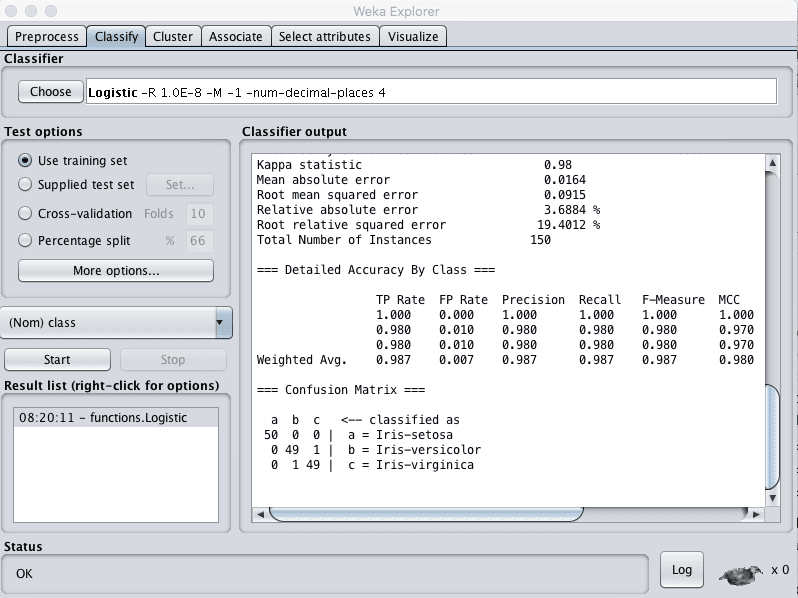
Weka Train Finalized Model on Entire Training Dataset
7. Right click on the result item in the “Result list” and select “Save model”. Select a suitable location and type in a suitable name, such as “iris-logistic” for your model.
This model can then be loaded at a later time and used to make predictions on new flower measurements.
We can use the mean and standard deviation of the model accuracy collected in the last section to help quantify the expected variability in the estimated accuracy of the model on unseen data.
For example, we know that 95% of model accuracies will fall within two standard deviations of the mean model accuracy. Or, restated in a way we can explain to other people, we can generally expect that the performance of the model on unseen data will be 96.33% plus or minus 2 * 3.38 or 6.76, or between 87.57% and 100% accurate.
You can learn more about using the mean and standard deviation of a Gaussian distribution in the Wikipedia page titled 68–95–99.7 rule.
Summary
In this post you completed your first machine learning project end-to-end using the Weka machine learning workbench.
Specifically, you learned:
- How to analyze your dataset and suggest at specific data transform and modeling techniques that may be useful.
- How to spot check a suite of algorithms on the problem and analyze their results.
- How to finalize the model for making predictions on new data and presenting the estimated accuracy of the model on unseen data.
Do you have any questions about running a machine learning project in Weka or about this post? Ask your questions in the comments and I will do my best to answer them.







No comments:
Post a Comment