The XGBoost library for gradient boosting uses is designed for efficient multi-core parallel processing.
This allows it to efficiently use all of the CPU cores in your system when training.
In this post you will discover the parallel processing capabilities of the XGBoost in Python.
After reading this post you will know:
- How to confirm that XGBoost multi-threading support is working on your system.
- How to evaluate the effect of increasing the number of threads on XGBoost.
- How to get the most out of multithreaded XGBoost when using cross validation and grid search.
Problem Description: Otto Dataset
In this tutorial we will use the Otto Group Product Classification Challenge dataset.
This dataset is available from Kaggle (you will need to sign-up to Kaggle to be able to download this dataset). You can download the training dataset train.zip from the Data page and place the unzipped trian.csv file into your working directory.
This dataset describes the 93 obfuscated details of more than 61,000 products grouped into 10 product categories (e.g. fashion, electrons, etc.). Input attributes are counts of different events of some kind.
The goal is to make predictions for new products as an array of probabilities for each of the 10 categories and models are evaluated using multiclass logarithmic loss (also called cross entropy).
This competition completed in May 2015 and this dataset is a good challenge for XGBoost because of the nontrivial number of examples and the difficulty of the problem and the fact that little data preparation is required (other than encoding the string class variables as integers).
Impact of the Number of Threads
XGBoost is implemented in C++ to explicitly make use of the OpenMP API for parallel processing.
The parallelism in gradient boosting can be implemented in the construction of individual trees, rather than in creating trees in parallel like random forest. This is because in boosting, trees are added to the model sequentially. The speed of XGBoost is both in adding parallelism in the construction of individual trees, and in the efficient preparation of the input data to aid in the speed up in the construction of trees.
Depending on your platform, you may need to compile XGBoost specifically to support multithreading. See the XGBoost installation instructions for more details.
The XGBClassifier and XGBRegressor wrapper classes for XGBoost for use in scikit-learn provide the nthread parameter to specify the number of threads that XGBoost can use during training.
By default this parameter is set to -1 to make use of all of the cores in your system.
Generally, you should get multithreading support for your XGBoost installation without any extra work.
Depending on your Python environment (e.g. Python 3) you may need to explicitly enable multithreading support for XGBoost. The XGBoost library provides an example if you need help.
You can confirm that XGBoost multi-threading support is working by building a number of different XGBoost models, specifying the number of threads and timing how long it takes to build each model. The trend will both show you that multi-threading support is enabled and give you an indication of the effect it has when building models.
For example, if your system has 4 cores, you can train 8 different models and time how long in seconds it takes to create each, then compare the times.
We can use this approach on the Otto dataset. The full example is provided below for completeness.
You can change the num_threads array to meet the number of cores on your system.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
Running this example summarizes the execution time in seconds for each configuration.
A plot of these timings is provided below.
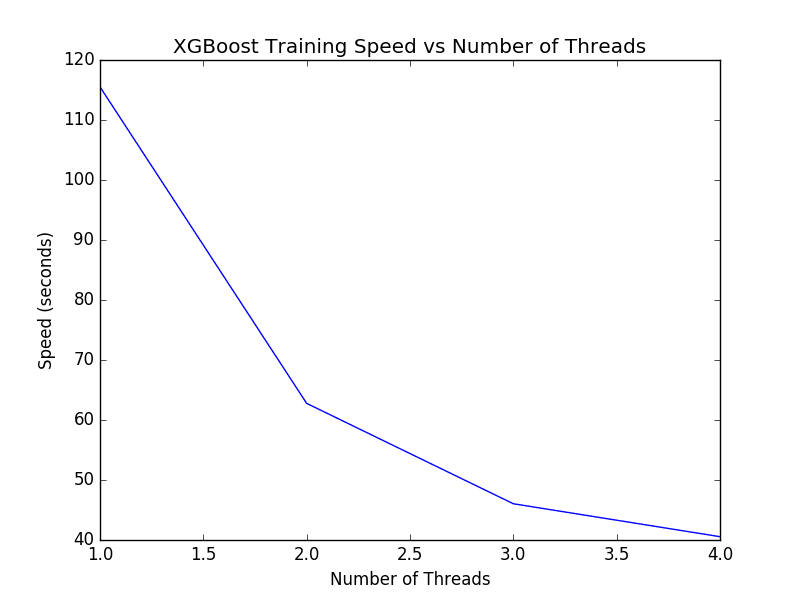
XGBoost Tune Number of Threads for Single Model
We can see a nice trend in the decrease in execution time as the number of threads is increased.
If you do not see an improvement in running time for each new thread, you may want to investigate how to enable multithreading support in XGBoost as part of your install or at runtime.
We can run the same code on a machine with a lot more cores. The large Amazon Web Services EC2 instance is reported to have 32 cores. We can adapt the above code to time how long it takes to train the model with 1 to 32 cores. The results are plotted below.
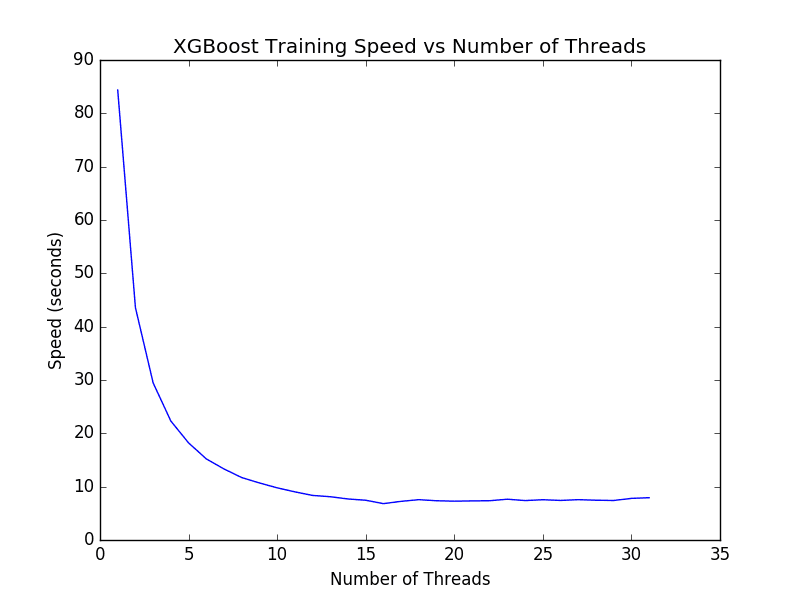
XGBoost Time to Train Model on 1 to 32 Cores
It is interesting to note that we do not see much improvement beyond 16 threads (at about 7 seconds). I expect the reason for this is that the Amazon instance only provides 16 cores in hardware and the additional 16 cores are available by hyperthreading. The results suggest that if you have a machine with hyperthreading, you may want to set num_threads to equal the number of physical CPU cores in your machine.
The low-level optimized implementation of XGBoost with OpenMP squeezes every last cycle out of a large machine like this.
Parallelism When Cross Validating XGBoost Models
The k-fold cross validation support in scikit-learn also supports multithreading.
For example, the n_jobs argument on the cross_val_score() function used to evaluate a model on a dataset using k-fold cross validation allows you to specify the number of parallel jobs to run.
By default, this is set to 1, but can be set to -1 to use all of the CPU cores on your system, which is good practice. For example:
This raises the question as to how cross validation should be configured:
- Disable multi-threading support in XGBoost and allow cross validation to run on all cores.
- Disable multi-threading support in cross validation and allow XGBoost to run on all cores.
- Enable multi-threading support for both XGBoost and Cross validation.
We can get an answer to this question by simply timing how long it takes to evaluate the model in each circumstance.
In the example below we use 10 fold cross validation to evaluate the default XGBoost model on the Otto training dataset. Each of the above scenarios is evaluated and the time taken to evaluate the model is reported.
The full code example is provided below.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
Running the example prints the following results.
We can see that there is a benefit from parallelizing XGBoost over the cross validation folds. This makes sense as 10 sequential fast tasks is better than (10 divided by num_cores) slow tasks.
Interestingly we can see that the best result is achieved by enabling both multi-threading within XGBoost and in cross validation. This is surprising because it means that num_cores number of parallel XGBoost models are competing for the same num_cores in the construction of their models. Nevertheless, this achieves the fastest results and is the suggested usage of XGBoost for cross validation.
Because grid search uses the same underlying approach to parallelism, we expect the same finding to hold for optimizing the hyperparameters for XGBoost.
Summary
In this post you discovered the multi-threading capability of XGBoost.
You learned:
- How to check that the multi-threading support in XGBoost is enabled on your system.
- How increasing the number of threads affects the performance of training XGBoost models.
- How to best configure XGBoost and Cross Validation in Python for minimum running time.
Do you have any questions about multithreading support for XGBoost or about this post? Ask your questions in the comments and I will do my best to answer.





No comments:
Post a Comment