Ensembles can give you a boost in accuracy on your dataset.
In this post you will discover how you can create three of the most powerful types of ensembles in R.
This case study will step you through Boosting, Bagging and Stacking and show you how you can continue to ratchet up the accuracy of the models on your own datasets.Let’s get started.
Increase The Accuracy Of Your Models
It can take time to find well performing machine learning algorithms for your dataset. This is because of the trial and error nature of applied machine learning.
Once you have a shortlist of accurate models, you can use algorithm tuning to get the most from each algorithm.
Another approach that you can use to increase accuracy on your dataset is to combine the predictions of multiple different models together.
This is called an ensemble prediction.
Combine Model Predictions Into Ensemble Predictions
The three most popular methods for combining the predictions from different models are:
- Bagging. Building multiple models (typically of the same type) from different subsamples of the training dataset.
- Boosting. Building multiple models (typically of the same type) each of which learns to fix the prediction errors of a prior model in the chain.
- Stacking. Building multiple models (typically of differing types) and supervisor model that learns how to best combine the predictions of the primary models.
This post will not explain each of these methods. It assumes you are generally familiar with machine learning algorithms and ensemble methods and that you are looking for information on how to create ensembles with R.
Need more Help with R for Machine Learning?
Take my free 14-day email course and discover how to use R on your project (with sample code).
Click to sign-up and also get a free PDF Ebook version of the course.
Ensemble Machine Learning in R
You can create ensembles of machine learning algorithms in R.
There are three main techniques that you can create an ensemble of machine learning algorithms in R: Boosting, Bagging and Stacking. In this section, we will look at each in turn.
Before we start building ensembles, let’s define our test set-up.
Test Dataset
All of the examples of ensemble predictions in this case study will use the ionosphere dataset.
This is a dataset available from the UCI Machine Learning Repository. This dataset describes high-frequency antenna returns from high energy particles in the atmosphere and whether the return shows structure or not. The problem is a binary classification that contains 351 instances and 35 numerical attributes.
Let’s load the libraries and the dataset.
Note that the first attribute was a factor (0,1) and has been transformed to be numeric for consistency with all of the other numeric attributes. Also note that the second attribute is a constant and has been removed.
Here is a sneak-peek at the first few rows of the ionosphere dataset.
For more information, see the description of the Ionosphere dataset on the UCI Machine Learning Repository.
See this summary of published world-class results on the dataset.
1. Boosting Algorithms
We can look at two of the most popular boosting machine learning algorithms:
- C5.0
- Stochastic Gradient Boosting
Below is an example of the C5.0 and Stochastic Gradient Boosting (using the Gradient Boosting Modeling implementation) algorithms in R. Both algorithms include parameters that are not tuned in this example.
We can see that the C5.0 algorithm produces a more accurate model with an accuracy of 94.58%.
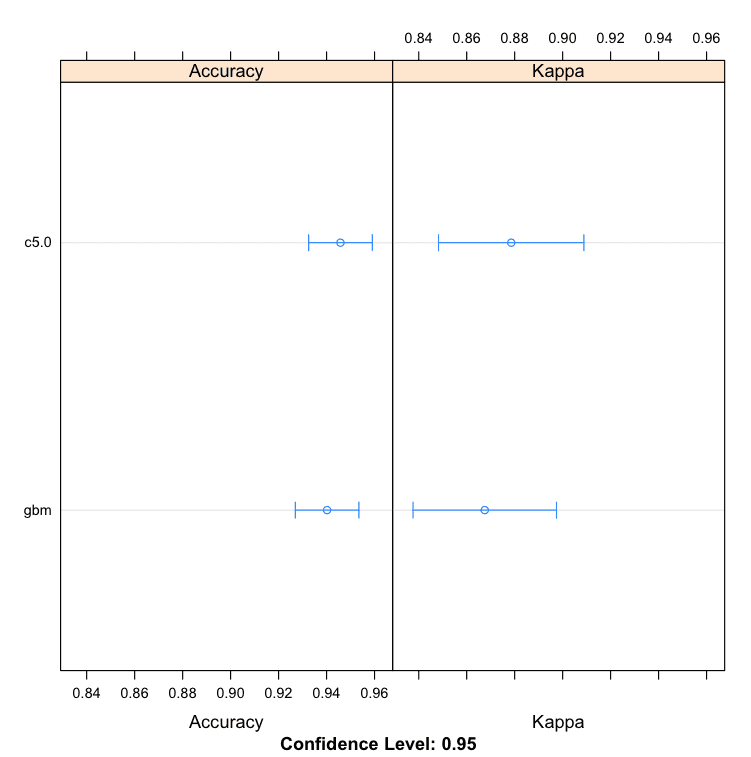
Boosting Machine Learning Algorithms in R
Learn more about caret boosting models tree: Boosting Models.
2. Bagging Algorithms
Let’s look at two of the most popular bagging machine learning algorithms:
- Bagged CART
- Random Forest
Below is an example of the Bagged CART and Random Forest algorithms in R. Both algorithms include parameters that are not tuned in this example.
We can see that random forest produces a more accurate model with an accuracy of 93.25%.
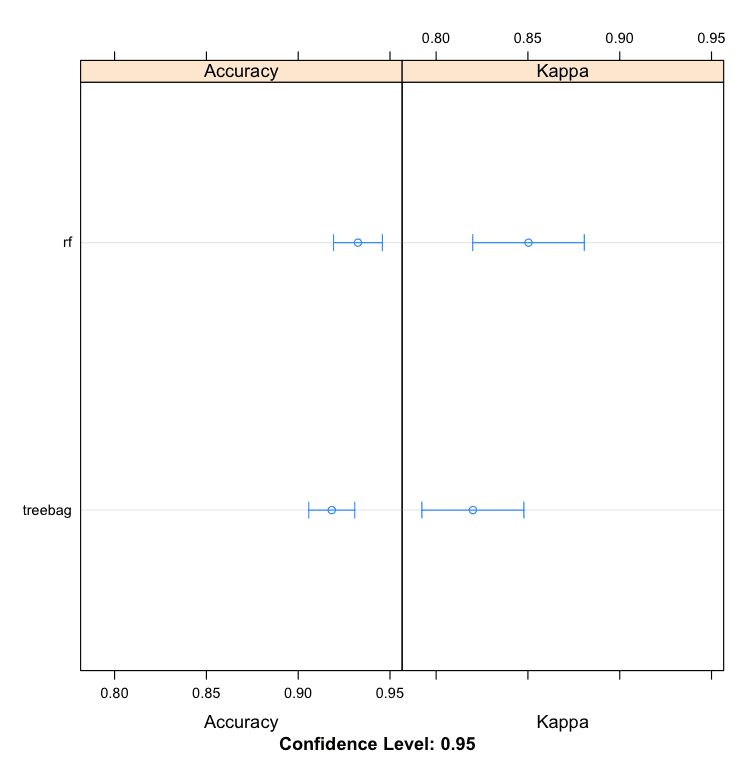
Bagging Machine Learning Algorithms in R
Learn more about caret bagging model here: Bagging Models.
3. Stacking Algorithms
You can combine the predictions of multiple caret models using the caretEnsemble package.
Given a list of caret models, the caretStack() function can be used to specify a higher-order model to learn how to best combine the predictions of sub-models together.
Let’s first look at creating 5 sub-models for the ionosphere dataset, specifically:
- Linear Discriminate Analysis (LDA)
- Classification and Regression Trees (CART)
- Logistic Regression (via Generalized Linear Model or GLM)
- k-Nearest Neighbors (kNN)
- Support Vector Machine with a Radial Basis Kernel Function (SVM)
Below is an example that creates these 5 sub-models. Note the new helpful caretList() function provided by the caretEnsemble package for creating a list of standard caret models.
We can see that the SVM creates the most accurate model with an accuracy of 94.66%.
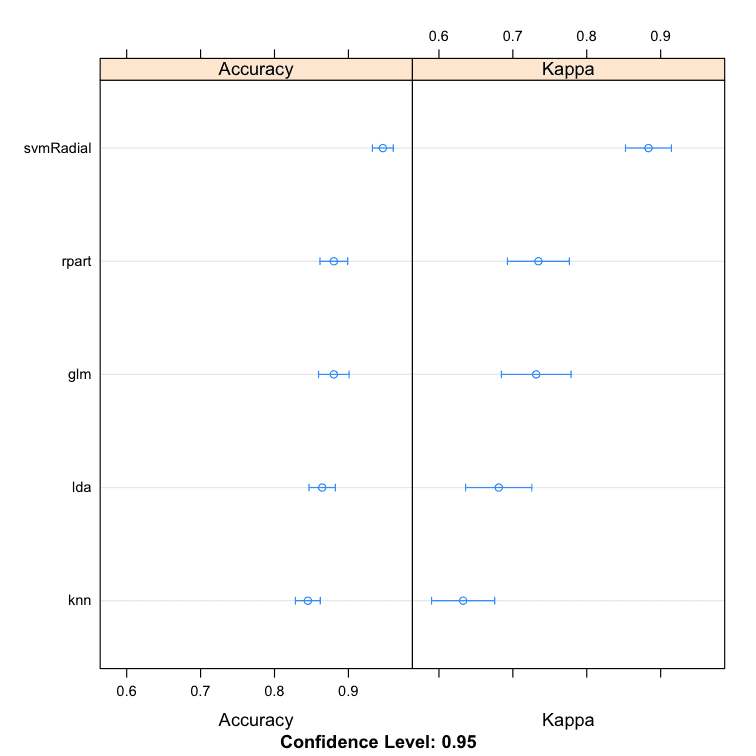
Comparison of Sub-Models for Stacking Ensemble in R
When we combine the predictions of different models using stacking, it is desirable that the predictions made by the sub-models have low correlation. This would suggest that the models are skillful but in different ways, allowing a new classifier to figure out how to get the best from each model for an improved score.
If the predictions for the sub-models were highly corrected (>0.75) then they would be making the same or very similar predictions most of the time reducing the benefit of combining the predictions.
We can see that all pairs of predictions have generally low correlation. The two methods with the highest correlation between their predictions are Logistic Regression (GLM) and kNN at 0.517 correlation which is not considered high (>0.75).
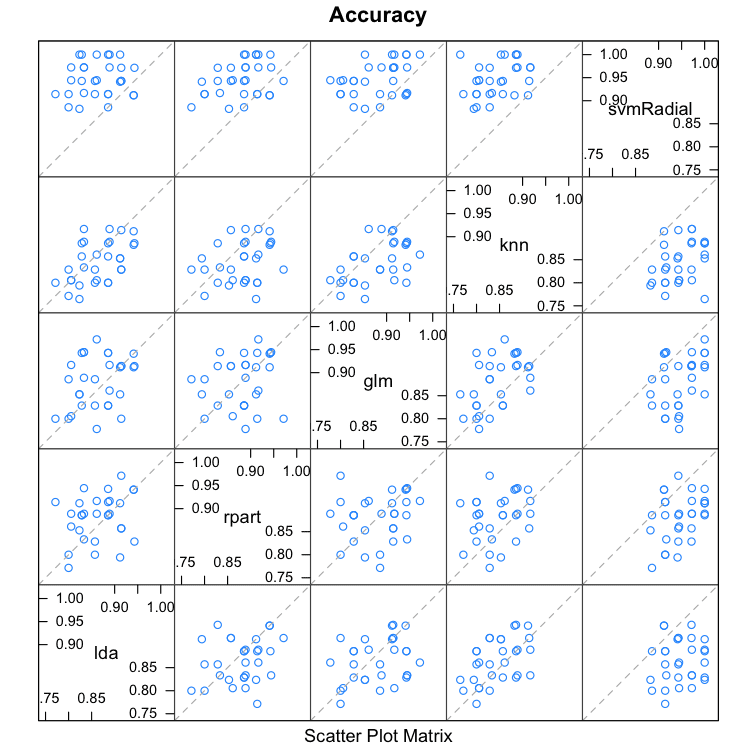
Correlations Between Predictions Made By Sub-Models in Stacking Ensemble
Let’s combine the predictions of the classifiers using a simple linear model.
We can see that we have lifted the accuracy to 94.99% which is a small improvement over using SVM alone. This is also an improvement over using random forest alone on the dataset, as observed above.
We can also use more sophisticated algorithms to combine predictions in an effort to tease out when best to use the different methods. In this case, we can use the random forest algorithm to combine the predictions.
We can see that this has lifted the accuracy to 96.26% an impressive improvement on SVM alone.
You Can Build Ensembles in R
You do not need to be an R programmer. You can copy and paste the sample code from this blog post to get started. Study the functions used in the examples using the built-in help in R.
You do not need to be a machine learning expert. Creating ensembles can be very complex if you are doing it from scratch. The caret and the caretEnsemble package allow you start creating and experimenting with ensembles even if you don’t have a deep understanding of how they work. Read-up on each type of ensemble to get more out of them at a later time.
You do not need to collect your own data. The data used in this case study was from the mlbench package. You can use standard machine learning dataset like this to learn, use and experiment with machine learning algorithms.
You do not need to write your own ensemble code. Some of the most powerful algorithms for creating ensembles is provided by R, ready to run. Use the examples in this post to get started right now. You can always adapt it to your specific cases or try out new ideas with custom code at a later time.
Summary
In this post you discovered that you can use ensembles of machine learning algorithms to improve the accuracy of your models.
You discovered three types of ensembles of machine learning algorithms that you can build in R:
- Boosting
- Bagging
- Stacking
You can use the code in this case study as a template on your current or next machine learning project in R.
Next Step
Did you work through the case study?
- Start your R interactive environment.
- Type or copy-paste all of the code in this case study.
- Take the time to understand each part of the case study using the help for R functions.
Do you have any questions about this case study or using ensembles in R? Leave a comment and ask and I will do my best to answer.







No comments:
Post a Comment