Methodology
Analysis and data processing in the study was carried out using the Weka machine learning software. A ten-fold cross-validation was used for experiments. This works in the following way:
- Produce 10 equal sized data sets from given data
- Divide each set into two groups: 90% for training and 10% for testing.
- Produce a classifier with an algorithm from 90% labeled data and apply that on the 10% testing data for set 1.
- Continue for set 2 through 10
- Average the performance of 10 classifiers produced from 10 equal sized (training and testing) sets
Need more help with Weka for Machine Learning?
Take my free 14-day email course and discover how to use the platform step-by-step.
Click to sign-up and also get a free PDF Ebook version of the course.
Take my free 14-day email course and discover how to use the platform step-by-step.
Click to sign-up and also get a free PDF Ebook version of the course.
Algorithms
For this study, we’ll take a look at the performance of 4 algorithms:
- Logistic Regression (Cessie & Houwelingen, 1990)
- Naive Bayes (John & Langley, 1995)
- Random Forest (Breiman, 2001)
- C4.5 (Quinlan, 1993)
These algorithms are relevant because they perform classification on a dataset, deal appropriately with missing or erroneous data, and have some kind of significance in scientific articles focused on medical diagnosis, see the papers Machine Learning for Medical Diagnosis: History, State of the Art, and Perspective and Artificial Neural Networks in Medical Diagnosis.
Logistic Regression is a probabilistic, statistical classifier used to predict the outcome of a categorical dependent variable based on one or more predictor variables. The algorithm measures the relationship between a dependent variable and one or more independent variables.
Naive Bayes is a simple probabilistic classifier based on Bayes’ theorem with strong independence assumptions. Bayes’ Theorem is as follows:

Bayes’ Theorem
Generally we can predict the outcome of some event by observing some evidence or probability of the event. The more evidence we have for an event occurring, the better we can support its prediction. At times, the evidence we have may depend on other events, making our predictions more complicated. To create a simplified (or “naive”) model, we make an assumption that all evidence for a particular event is independent of any other.
According to Breiman, Random Forest creates a combination of trees that vote on a particular outcome. The forest chooses the classification that contains the most votes. This algorithm is exciting because it is a bagging algorithm, and it can potentially improve our results by training the algorithm on different subsets of the training data. A random forest learner is grown in the following way:
- Sampling replacement members from the training set forms the input data. One-third of the training set is not present and is known to be “out-of-bag.”
- A random number of attributes, which form nodes and leaves, are chosen for each tree.
- Each tree is grown as large as possible without pruning (removing sections of trees that provide little significance in classification).
- Out-of-bag data then used for evaluating accuracy of each tree and entire forest.
C4.5 (also known as “J48” in Weka) is an algorithm used to generate a decision tree for classification. A decision tree in C4.5 is grown in the following way:
- At each node, choose the data that most effectively splits samples into subsets enriched in one class from the other.
- Set attribute with the highest normalized information gain.
- Use this attribute to create a decision node and make the prediction.
In this case, information gain is the measure of the difference between two probability distributions two attributes. What makes this algorithm helpful for us is that it solves several issues that Quinlan’s earlier algorithm, ID3, may have missed. According to Quinlan, these include, but are not limited to:
- Avoiding over-fitting the data (determining how deeply to grow a decision tree).
- Reduced error pruning.
- Rule post-pruning.
- Handling continuous attributes (e.g., temperature)
- Choosing an appropriate attribute selection measure.
- Handling training data with missing attribute values.
- Handling attributes with differing costs.
- Improving computational efficiency.
Evaluation
After performing a cross-validation on the dataset, I will focus on analyzing the algorithms through the lens of three metrics: accuracy, ROC area, and F1 measure.
Based on testing, accuracy will determine the percentage of instances that were correctly classified by the algorithm. This is an important start of our analysis since it will give us a baseline of how each algorithm performs.
The ROC curve is created by plotting the fraction of true positives vs. the fraction of false positives. An optimal classifier will have an ROC area value approaching 1.0, with 0.5 being comparable to random guessing. I believe it will be very interesting to see how our algorithms predict on this scale.
Finally, the F1 measure will be an important statistical analysis of classification since it will measure test accuracy. F1 measure uses precision (the number of true positives divided by the number of true positives and false positives) and recall (the true positives divided by the number of true positives and the number of false negatives) to output a value between 0 and 1, where higher values imply better performance.
I strongly believe that all algorithms will perform rather similarly because we are dealing with a small dataset for classification. However, the 4 algorithms should all perform better than the class baseline prediction that gave an accuracy of about 65%.
Results
To perform a rigorous analysis of various algorithms, I evaluated performance on all of the created datasets using Weka Experimenter. The results are shown below.

Algorithm classification accuracy averages on diabetes datasets and a scatterplot of logistic regression performance on various datasets.
The data here suggests that Logistic Regression performs the best on the standard, unaltered dataset, while Random Forest performed the worst. However, there is no clear winner between any of the algorithms.
On average, it also seems that the standardized and normalized datasets gave stronger accuracies, while the discrete data set yielded the weakest accuracies. This may be due to the fact that nominal values do not allow for accurate predictions for the algorithms I took into consideration.

Weka Experimenter output comparing performance of Logistic Regression with performance of other algorithms.
The adjustment of scale on the normalized dataset may have improved results slightly. However, transforms and rescaling the data did not significantly improve results and therefore probably did not expose any structure in the data.
We can also see asterisks (*) by the values that have a statistically significant difference compared to those values in the first column, the accuracies of logistic regression. Weka figures out statistical insignificance through a pair-wise comparison of schemes using either a standard T-Test or the corrected resampled T-Test, see the paper Inference for the Generalization Error.
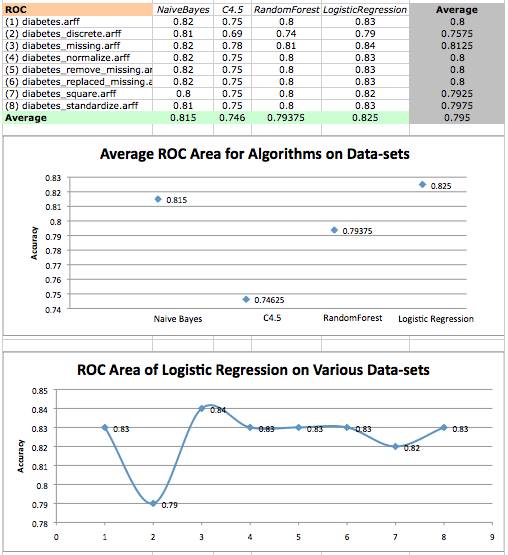
Algorithm ROC area averages on diabetes datasets and a scatterplot of logistic regression performance on various datasets
The results suggests that, once again, LogisticRegression performed the best, while C4.5 performed the worst. On average, it also seems that the dataset corrected for missing values performed the best, while the discrete data set performed the worst.
In both cases, we find that tree algorithms do not perform as well on this dataset. In fact, all results given by C4.5 (and all but one result of RandomForest) have statistically significant differences compared to those results given by LogisticRegression.
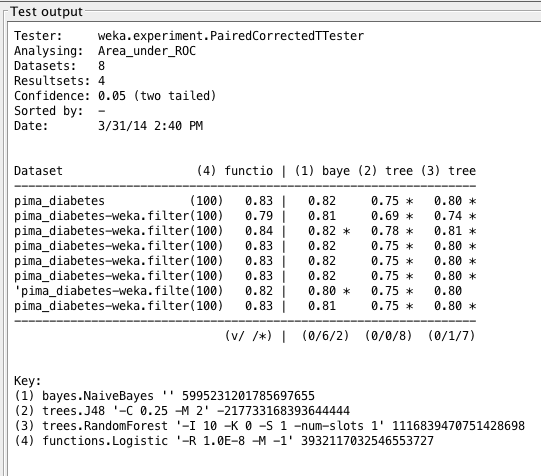
Weka Experimenter output comparing ROC curve area of Logistic Regression with ROC curve area of other algorithms.
This poor performance may be a result of the tree algorithm’s complexity. Measuring relationship with dependent and independent variables may be an advantage here. Also, C4.5 may not be choosing the correct attribute for its analysis, and therefore worsening predictions based on highest information gain.
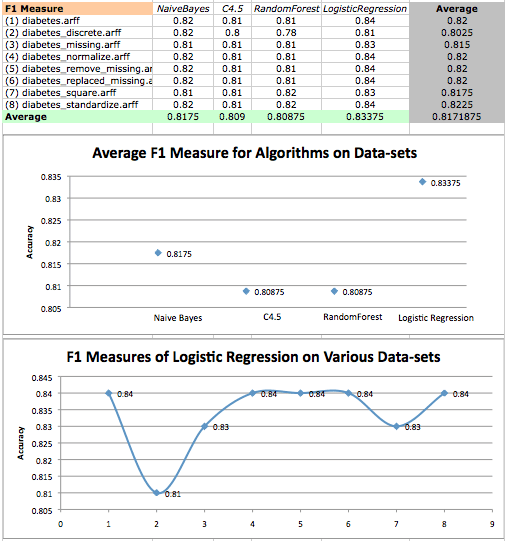
F1 Measure values on diabetes datasets and a scatterplot of logistic regression F1 measures on various datasets.
In the first two analyses, we found that the performance of Naive Bayes followed closely behind the performance of LogisticRegression. Now we find that all but one result of Naive Bayes have a statistically significant difference compared to results given by LogisticRegression.
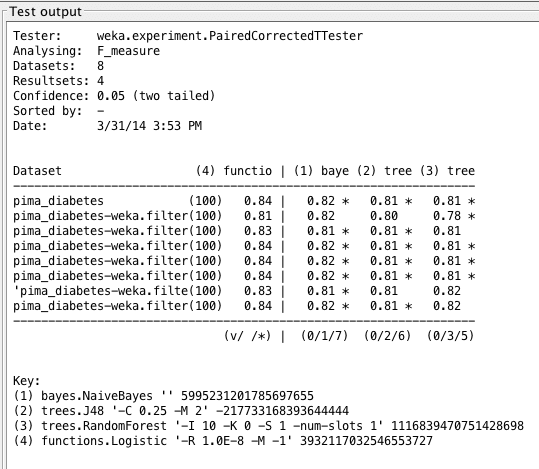
Weka Experimenter output comparing F1 score of Logistic Regression with F1 scores of other algorithms.
The results show us that LogisticRegression performs best, but not by much. This means that LogisticRegression has the most accurate tests in this case, and it learns quite well on this dataset. Just to recall the computation behind the F1-measure, we know:
- Recall: R = TP / (TP + FN),
- Precision: P = TP / (TP + FP), and
- F1-Measure: F1 = 2[ (R * P) / (R + P) ],
where TP = True Positive, FP = False Positive, FN = False Negative.
Our results then suggest that LogisticRegression maximizes the rate of True Positives, and minimizes the rate of False Negatives and False Positives. As for poor performance, I am led to believe that the predictions done by Naive Bayes are just too “naive” and the algorithm therefore uses independence too liberally.
We may need more data to provide more evidence for a particular event occurring, which should better support its prediction. Tree algorithms in this case may suffer due to their complexity, or just because of choosing incorrect attributes for analysis. This may become less of a problem with larger datasets.
Interestingly enough, we also find that the best performing algorithm, LogisticRegression, performs the worst on the diabetes_discrete.arff dataset. It’s probably safe to assume that, for LogisticRegression, all transforms of the data (except for diabetes_discrete.arff) seem to yield better very similar results, and this is very clear through the similar trend in each scatterplot!
Improving Results
To improve results, we can turn to ensemble methods like boosting. Boosting is an ensemble method that starts out with a base classifier that is prepared on the training data. A second classifier is then created behind it to focus on the instances in the training data that the first classifier got wrong.
The process continues to add classifiers until a limit is reached in the number of models or accuracy. Boosting is provided in Weka in the AdaBoostM1 (adaptive boosting) algorithm. The results are shown below:

Boosted algorithm accuracy averages on diabetes datasets and a scatterplot of logistic regression performance on various datasets. Original results are in red, while boosted results are in blue.
It’s clear that boosting had no effect on LogisticRegression, but significantly worsened the performance of the tree algorithms. According to the results from Weka’s Experimenter, the performance of the boosted LogisticRegression has a statistically significant difference compared to results given by the boosted C4.5, RandomForest, and boosted RandomForest.
Since RandomForest already includes an ensemble method, bagging, the addition of boosting may be causing overfitting which therefore could explain the poor performance.

Weka Experimenter output comparing performance of Boosted Logistic Regression with performance of other algorithms.
In any case, we are still unable to exceed the accuracy of 77.47% with the best performing algorithm, LogisticRegression. This may be due to limitations of the data or a low cross-validation value. We find that in some cases, such as with C4.5, accuracy drops drastically from 74.28% to 71.4% after performing AdaBoost.
Next we’ll take a look at ROC area for each boosted algorithm.

Boosted algorithm ROC area averages on diabetes datasets and a scatterplot of logistic regression performance on various datasets. Original results are in red, while boosted results are in blue.
We can see that the points on the scatter plot form a smoother trend. In other words, the variance between data points is smaller. Our results here are quite interesting: all boosted algorithms except for C4.5 show a lesser value for ROC area. That means boosting C4.5 gives slightly less false positives and slightly more true positives compared with other boosted algorithms.

Weka Experimenter output comparing ROC curve area of Logistic Regression with ROC curve area of other algorithms.
On a first look this seems a bit strange: boosting C4.5 gives a decreased accuracy, but an increased ROC area. The differences are clear if we consider that accuracy is actually a summary of true positives and false positives, whereas ROC area is an integration of hit rate and false alarm rate. Either way, we find that the boosted C4.5 has a statistically significant difference compared to those results given by LogisticRegression (both default and boosted forms).
Finally, we’ll take a look at F1 measure for boosted algorithms.
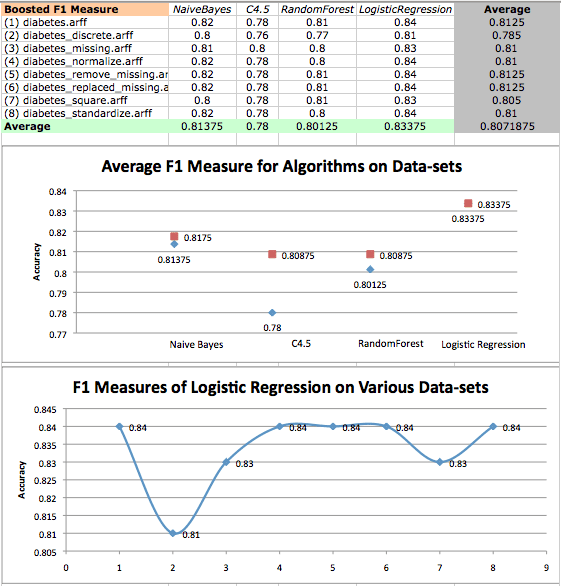
Boosted F1 Measure values on diabetes datasets and a scatterplot of logistic regression F1 measures on various datasets. Original results are in red, while boosted results are in blue.
Once again, we find that LogisticRegression performs quite well, but boosting has no effect on LogisticRegression when analyzing F1 measure. We seem to have pushed the limit of LogisticRegression, and once again see that it is statistically dominant over tree algorithms.
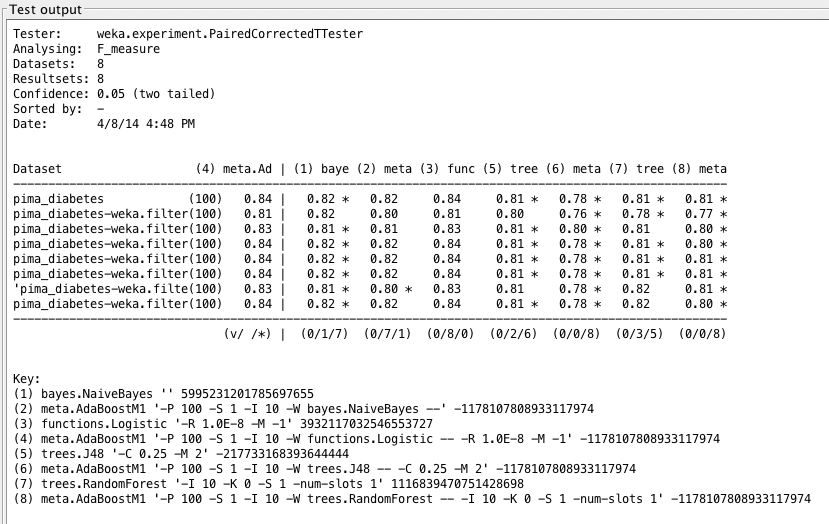
Weka Experimenter output comparing F1 score of Boosted Logistic Regression with F1 scores of other algorithms.
Need more help with Weka for Machine Learning?
Take my free 14-day email course and discover how to use the platform step-by-step.
Click to sign-up and also get a free PDF Ebook version of the course.
Removing Attributes to Test Assumptions
We may also be interested in changing the study to make it non-invasive, and therefore analyzing an algorithm’s performance on only four attributes: mass, skin, age, and pedi. This could help by allowing medical professionals administer the diabetes mellitus test over a larger scale and making the test faster. Of course with these advantages we may lose some accuracy.
Based on what we saw in scatter plots of the data, I believe our algorithms will perform quite well on the dataset, but not as well as with the standard dataset. Creating a new dataset (and naming it diabetes_noninvasive.arff) was a way to test our own assumptions on the onset of diabetes, namely that the risk increases with obesity and older age. In a similar fashion, I was able to remove attributes using Weka Explorer, and then analyze algorithm performance using Weka Experimenter. The results are shown below:

Algorithm accuracy averages on invasive and noninvasive diabetes datasets. Non-invasive results are in red, while original results are in blue.
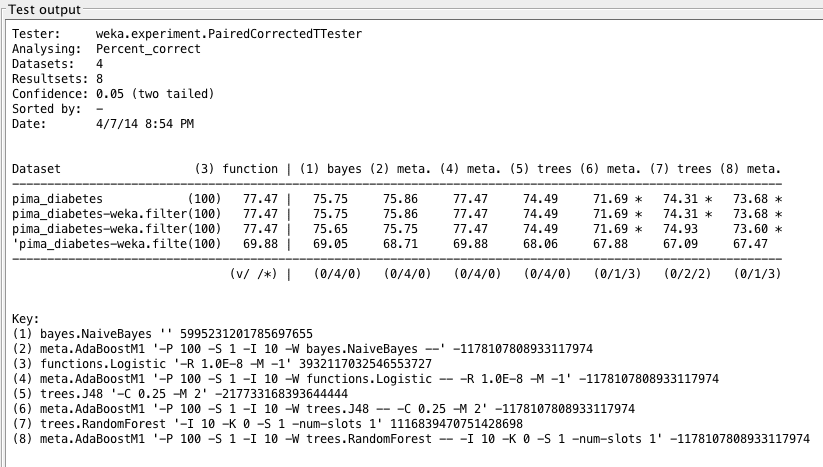
Weka Experimenter output comparing performance of Logistic Regression with performance of other algorithms.
Through all metrics, as predicted, the noninvasive dataset did not provide very accurate results. We find similar trends as we did in the earlier analysis, namely that LogisticRegression still performs most accurately.

Algorithm ROC area averages on invasive and noninvasive diabetes datasets. Non-invasive results are in red, while original results are in blue.
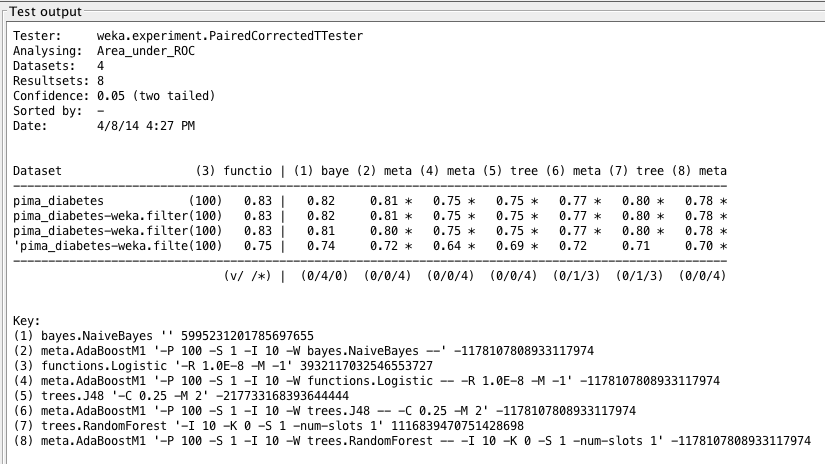
Weka Experimenter output comparing ROC area of Logistic Regression with ROC area of other algorithms.
Our results for the noninvasive test are actually comparable to those of the standard dataset. We may find that this fall in accuracy can be costly in the long run, but we could probably use this test as a precursor to an official diabetes mellitus test. With today’s technology, a noninvasive test can be performed online to predict the onset of diabetes — given we are okay with a bit more error — and can then suggest to a patient if further testing is necessary.

Algorithm F1 measure averages on invasive and noninvasive diabetes datasets. Non-invasive results are in red, while original results are in blue.
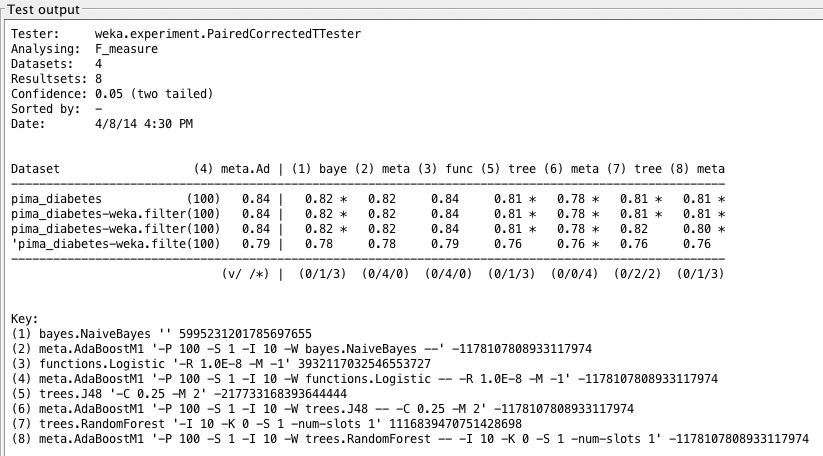
Weka Experimenter output comparing F1 measure of Boosted Logistic Regression with F1 measure of other algorithms.
Conclusion
In this study, we compared the performance of various algorithms and found that Logistic Regression performed well on the standard, unaltered dataset. We tried to understand how different altered datasets affected our results.
Moreover, we paid close attention to LogisticRegression, and analyzed its performance throughout various metrics. The work here gave me a better understanding of machine learning applications in medical diagnosis. This was also an important lesson on data transforms and algorithm analysis.
It is somewhat unfortunate that many medical datasets are small (this may be due to patient confidentiality), since a larger dataset would give us more flexibility and robustness in analysis. However, I strongly believe that this study is a good start for building methods that help diagnose patients, and bridge the gap between doctors and large datasets.






No comments:
Post a Comment