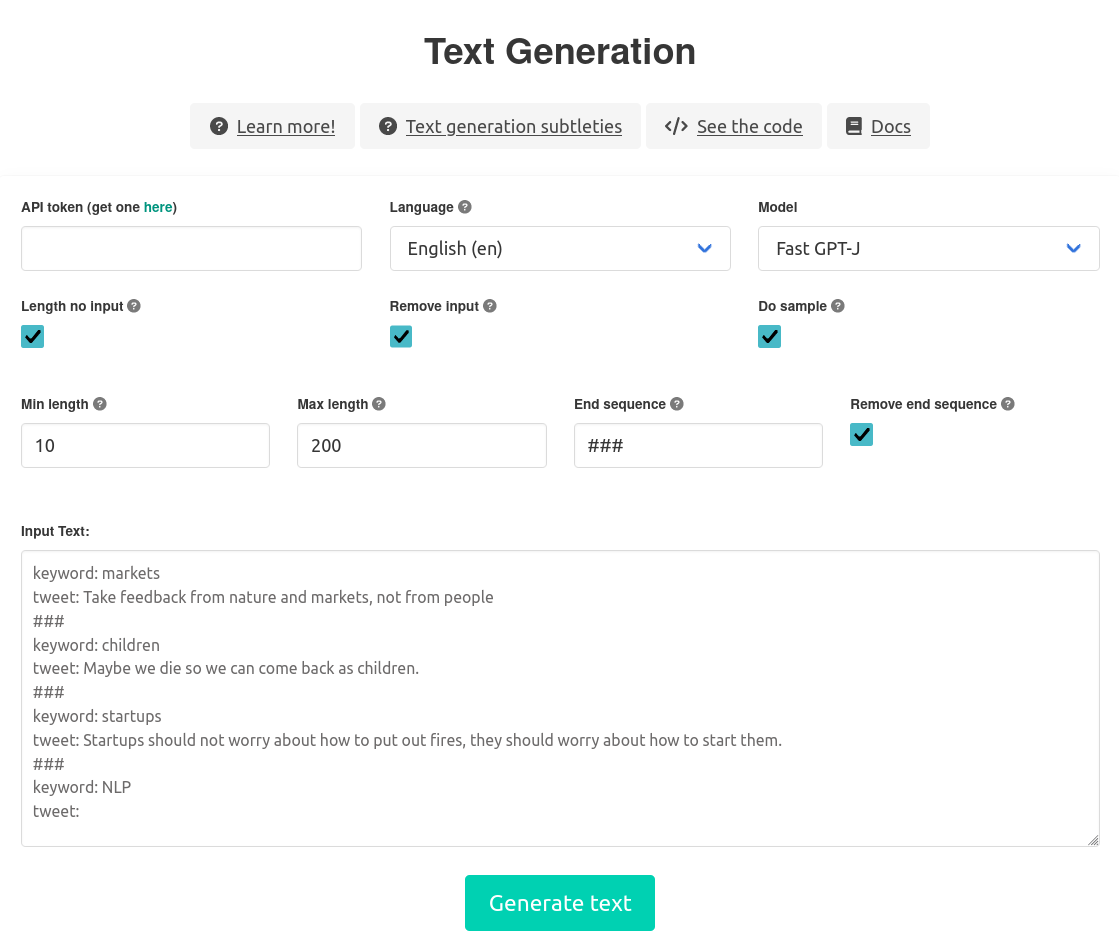
GPT-J may be the most powerful open-source Natural Language Processing model today (it's the only open-source alternative competing with GPT-3), you might find it too general and not perfectly suited to your use case. In that case, fine-tuning GPT-J with your own data is the key.
The Power of GPT-J
Since it's been released by in June 2021, GPT-J has attracted tons of Natural Language Processing users - data scientists or developers - who believe that this powerful Natural Language Processing model will help them take their AI application to the next level (see EleutherAI's website).
GPT-J is so powerful because it was trained on 6 billion parameters. The consequence is that this is a very versatile model that you can use for almost any advanced Natural Language Processing use case (sentiment analysis, text classification, chatbots, translation, code generation, paraphrase generation, and much more). When properly tuned, GPT-J is so fluent that it's impossible to say that the text is generated by a machine...
It is possible to easily adapt GPT-J to your use case on-the-fly by using the so-called technique (see how to use it here). However, if few-shot learning is not enough, you need to go for a more advanced technique: fine-tuning.
What is Fine-Tuning?
When it comes to creating your own model, the traditional technique is about training a new model from scratch with your own data. The problem is that modern models like GPT-J are so huge that it's almost impossible for anyone to train this model from scratch. EleutherAI said it took them 5 weeks to train GPT-J on TPUs v3-256, which means it cost hundreds of thousands of dollars...
Good news is that re-training GPT-J is not necessary because we have fine-tuning! Fine-tuning is about taking the existing GPT-J model and slightly adapting it. In the past, training traditional Natural Language Processing models from scratch used to take tons of examples. With the new generation Transformer-based models, it is different: fewer examples are necessary and can lead to great results. If you ever heard of "transfer-learning", this is what it is about.
How to Fine-Tune GPT-J?
Even if fine-tuning GPT-J is much easier than training the model from scratch, it is still a challenge for several reasons:
- • It is a very compute intensive operation that can be painfully long on GPU. The best option is to use a TPU for that.
- • The fine-tuning process takes some practice, some parameters should be tweaked, and you can easily end up with a suboptimal accuracy.
- • Once you have your brand new fine-tuned model it's not over: you have to deploy it and reliably use it in production.
If you want to fine-tune GPT-J by yourself, here is how you could do it:
- • Follow the how-to from the Mesh Transformer Jax team here.
- • Make sure to perform the fine-tuning on a TPU V3 as you will run out of memory on a TPU V2. You can ask for a free TPU access for 1 month thanks to the TPU research cloud (TRC) program.
- • Don't forget to turn your result into a slim GPT-J version that is more suited for production inference.
Fine-Tuning GPT-J on NLP Cloud
At NLP Cloud we worked hard on a fine-tuning platform for GPT-J. It is now possible to easily fine-tune GPT-J: simply upload your dataset containing your examples, and let us fine-tune and deploy the model for you. Once the process is finished, you can use your new model as a private model on our API.
GPT-J Fine-Tuning on NLP Cloud
The fine-tuning process itself is free, and then you need to select a fine-tuning plan depending on the volume of requests you want to make on your newly deployed model.
If you do not want to spend too much time on the fine-tuning and deployment operations, it is an option you might want to consider.
Conclusion
GPT-J is an amazing Natural Language Processing model. Mix it with few-shot learning and fine-tuning, and you will get a state of the art AI application!